语音信号特征参数估计算法研究毕业论文
2020-04-10 16:58:46
摘 要
语音识别技术广泛应用于信号处理,模式识别,发声机制和听觉机制,人工智能等领域。中国物联网校企联盟将语音识别视为一种“机器听觉系统”。可见,语音识别在现阶段地位的重要性。它有着可观的应用背景,同时也有深远的理论研究价值。作为语音识别的第一步提取特征参数显得尤为重要。
为了提高语音识别率,本文提出了一种新的特征参数提取算法。首先提取短时平均能量、短时平均过零率和MFCC参数,然后该算法将短时平均能量、基音周期融合到MFCC特征参数中,形成新的特征参数。利用DTW算法对特征参数进行匹配,实现语音识别。使用数字0到9作为语音样本进行语音识别,仿真实验表明,新的特征参数可以提高语音识别率。但由于实验语音样本不够,实验结果客观性不足。系统的大部分工作和包装都由MATLAB完成,版本为7.0。
关键词:语音识别;特征参数;DTW;MFCC
Abstract
Speech recognition technology is widely used in signal processing, pattern recognition, phonation mechanism and auditory mechanism, artificial intelligence and other fields. The China Internet of Things School-Enterprise Alliance regards speech recognition as a "machine hearing system." It can be seen that the importance of speech recognition at the present stage. It has a considerable application background, but also has profound theoretical research value. Extracting feature parameters as the first step in speech recognition is particularly important.
In order to improve the speech recognition rate, this paper proposes a new feature parameter extraction algorithm. First, the short-term average energy, short-time average zero-crossing rate and MFCC parameters are extracted. Then the algorithm combines the short-term average energy and pitch period into the MFCC feature parameters to form new feature parameters. The DTW algorithm is used to match the feature parameters to achieve speech recognition. Using the numbers 0 to 9 as speech samples for speech recognition, simulation experiments show that the new feature parameters can improve the speech recognition rate. However, due to the lack of experimental speech samples, the experimental results are insufficient. Most of the work and packaging of the system is done by MATLAB, version 7.0..
Keywords : Speech recognition; Characteristic parameters; DTW; MFCC
目 录
摘要 I
Abstract II
第1章 绪论 1
1.1实验开发环境介绍 1
1.2语音识别的发展过程及研究进展 1
1.3语音识别的原理及组成 2
1.4语音特征参数提取在语音识别中的重要性 3
第2章 语音信号的预处理 5
2.1预加重 5
2.2 分帧与加窗 6
第3章 特征参数提取 8
3.1 短时平均能量 8
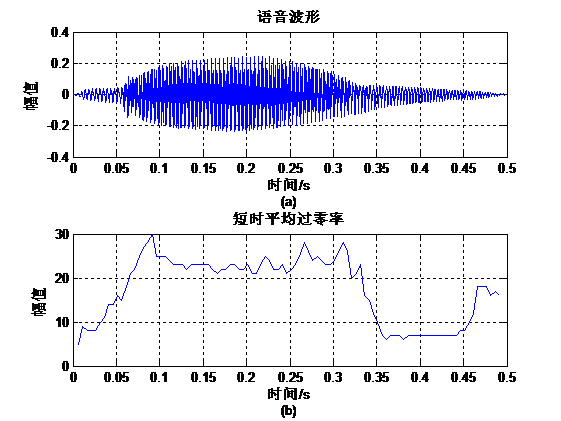
3.2 短时平均过零率 10
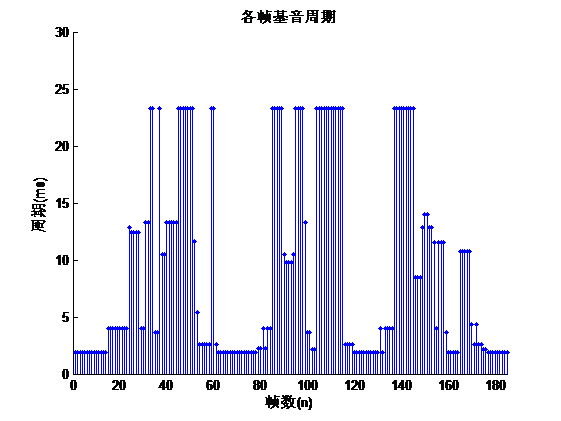
3.3 基音周期 11
3.4 Mel频率倒谱系数MFCC 13
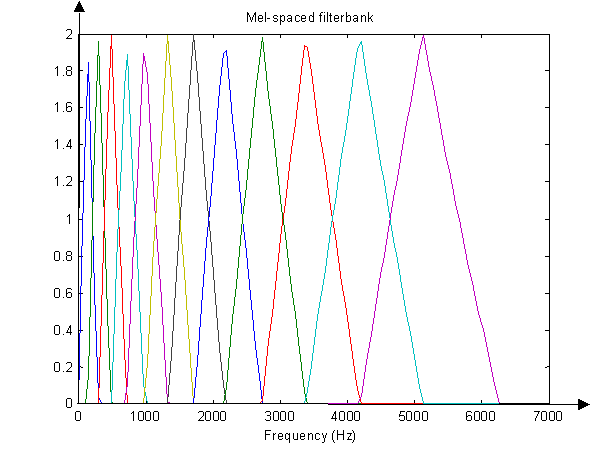
3.4.1 Mel频率分析 13
3.4.2 Mel频率倒谱系数提取 14
第4章 DTW算法 16
4.1 DTW算法原理 16
4.2 DTW算法过程 17
第5章 改进的特征参数 18
5.1 改进的特征参数计算流程 18
5.2 仿真实验及其分析 18
第6章 结论 20
参考文献 21
致 谢 22
第1章 绪论
机器交谈并让机器了解你所说的,是人们梦寐以求的一件事情。语音识别技术是将人类语音中的词汇或内容转换为计算机可读文本[1]。作为与计算机交互的第一步,语音识别已经成为智能计算机系统的重要组成部分,并被专门列为研究主题。如今整个社会都在朝着智能化生产的方向前进,智能识别作为其中关键的一环必然会得到大量的研究支持。
1.1实验开发环境介绍
MATLAB是由美国Mathworks公司出品的一款数值分析计算软件,现在的科研应用中多用于图像或者声音的处理、信号的检测处理以及数学方面的建模[2]。并且MATLAB软件本身自带许多打包好的针对多种不同任务的工具箱,可以胜任多种工作环境和目标,对于开发项目的初学者来说十分的简单快捷。
MATLAB最直观的优点之一是可视化,不论是什么数据结果它都能通过图形直观地表现出来以便于用户理解。相对于其他开发环境来说,MATLAB的运行速度会更慢,但是在开发速度上以及各种调试过程中MATLAB具有它自己独到之处[2]。在本系统的开发之初,所有要求和完成目标都比较不明确,在这种情况下MATLAB可以很轻松地在过程中发现问题所在并加入新的函数代码。
本次实验本系统的基本算法框架正是建立在语音信号的分析计算上,通过对语音信号进行逐帧分析,加上特征参数算法的函数可以提取出特征参数的向量矩阵。然后利用DTW算法进行训练匹配最终得到实验结果。
1.2语音识别的发展过程及研究进展
语音识别中,最早研究说话人识别是在20世纪30年代。早期的研究热点是人耳听声识别的实验,并探讨听声识别的可能性。随着研究方法和工具的不断完善,研究工作逐渐摆脱了简单的人耳听别。在贝尔实验室的L.G.Kesta提出“声纹”概念之后,电子技术和计算机技术的发展使得通过机器自动识别人类声音成为可能[3]。贝尔实验室的S.Pruzansky提出了一种基于模板匹配和概率统计方差分析的声纹识别方法,并将倒谱和线性预测分析应用于声纹识别。
语音识别研究始于20世纪50年代。20世纪60年代末和70年代初的语音识别研究中最重要的就是语音信号的线性预测编码(LPC)的发展和动态时间规整(DTW)技术。它们分别有效地解决了语音特征选取和不匹配时间匹配问题,对语音识别具有十分重要的意义。在这个时期,研究的主要目标还是孤立词语音识别。
过度到20世纪80年代,连接词语音识别成为了语音识别研究的重点之一,并开发了一系列连接词语音识别算法以及关键字识别算法。美国国防部的ITT Higgins(国际电报电报公司)和Wohlford发明的模板连接方法实现了关键字检测(KWS),并提出了填充模板的概念(该模板来自于词汇外的言语训练)。从那时起,贝尔实验室的Wilpon就基于HMM实现了5个电话术语的关键词,并且开始利用KWS,这意味着KWS研究的兴起[3]。BBN Systems and Technology,Inc.的Rohlicek和其他人也研究了非特定人类KWS的连续HMM建模问题。另一个重要的发展是语音识别算法从模板匹配技术到统计模型技术的转变。人们的研究从微观层面过度到宏观层面,不再过分深究语音特征的细化,而是从整体的平均角度建立最优化的语音识别系统。统计语言模型也开始逐渐取代基于规则语言模型。
自20世纪90年代以来,语音识别在细化模型设计、特征参数的提取和优化,以及系统的自适应技术上取得了更多重要进展[4]。语音识别技术进一步成熟,并逐渐实现商业化。
随着我国国际地位的不断提高和在经济和市场中的重要地位,汉语语音识别越来越受到人们的关注。IBM的Viavoice和微软的中文识别引擎是当今汉语语言识别的最高水平[5]。近年来,我国对语音识别的研究发展迅速,尤其是我国大型词汇连续语音识别系统的研究已经接近甚至超过了国外的最高水平。
目前,苹果的语音识别技术在国内外都处于领先水平并一直走在前列。在国内方面,科大,搜狗,盛大,捷通华声,云智生 ,紫东翻译,百度语音等系统都采用了最新的语音识别技术。市场上的其他相关产品也直接或间接地嵌入了类似的技术[6]。
1.3语音识别的原理及组成
语音识别实际上是模式识别的一种,是通过提取语音信号的特征参数,根据训练阶段得到声学模型对特征参数进行判别,判断属于哪一类。训练和学习两个过程构成了语音识别的全部内容。其中,训练学习是指通过提取特征参数,并将这些特征参数储存在库中作为语音的模版。识别过程是指根据一定的算法确定待测语音的特征参数与模板库中语音信息的对应模板之间的测量值,以实现最佳识别输出[7]。识别过程比训练和学习更加重要和复杂。换句话说,在训练阶段,用户逐个说出词汇表中的每个单词,并将其特征向量作为模板保存在模板库中。在识别阶段,将模板库中每个模板的特征向量和输入信号按顺序进行比较,输出相似度最高的模板作为识别结果。
语音识别的大致过程如下:
图1.1 语音识别过程
特征提取是降低语音信号的维数,提取语音中的有用信息,消除和识别无关信息。这样产生的特征参数不仅表示说话者信息,而且还减少稍后识别所需的处理时间。常用的语音特征参数是梅尔倒谱系数(MFCC)和线性预测倒谱系数(LPCC)。LPCC在所有频率上线性近似语音,但这与人类听觉特性不一致。而MFCC考虑到人耳对语音信号的影响,才进行的特征参数的提取。其实还有很多其他的特征参数,例如:音高,音调周期,短时能量,共振峰等。目前语音信号特征参数的提取主要采用MFCC等参数或LPCC参数,再添加其他参数作为补充,可以在一定程度上提高语音信号的准确性。。
声学模型(acoustic model)用于描述每个基本语音单元在训练阶段的特征参数向量的概率分布训练,由语音库中每个基本语音单元的多个说话者训练语音特征向量生成。目前隐马尔可夫模型常用于建立声学模型。
发音字典(pronunciation dictionary)是指以音素为识别单位进行识别。例如,在识别一个单词中的三个音素是æ,p和l时,会使用字典来确定该词是苹果apple。
语音模型(language model)是用于调整声学模型所识别的不合逻辑的词语,例如:当我们听到外国人说错了的中国人时,我们仍然可以认识到这些内容,因为我们有语法知识。
1.4语音特征参数提取在语音识别中的重要性
语音特征参数的提取是语音识别中不可缺少的重要环节[7]。当人们说话时,声带振动的不规律性,以及声音在传播时候的噪声叠加,在人耳收到声音信号后会携带很多信息。其中有用的信息包括了语义信息和个人特征等。语义涵盖了文字信息,而个人特征常常作为说话人个体的识别。特征参数是在提取过程中不同语音信号之间特有的特征,于是特征参数的选择尤为重要。单纯对声音而言,对异音字特征参数之间的差别要尽可能大,而对同音字特征参数的差别尽可能小。同时,应考虑计算机的处理和存储时间。
如上所述,计算机模式识别匹配包含了语音识别。在这个匹配的过程中,计算机首先要对输入的语音信号进行分析和处理。从中提取重要的特征参数,并使用特征参数来构建语音模型作为识别模板。之后计算机对输入的测试语音进行特征提取,逐个搜索并匹配存储在计算机中的识别模板,然后查找并输出最佳匹配结果[8]。可以得出结论,特征参数的选择和语音模型的质量直接关系到识别结果的质量。因此,语音特征参数的提取在语音识别中起着不可或缺的作用。
特征参数的研究是语音识别的基础。特征参数应该能够完整和准确地表达语音信号,同时也要把多余的信息给过滤掉,这其实就是去冗余的过程[9]。
第2章 语音信号的预处理
由于语音信号的复杂性和时变性,我们在对语音信号进行分析时,要对语音信号进行预处理。这里的预处理是指对语音信号的特殊处理:预加重和分帧加窗。这些步骤的主要目的就是为了消除会造成特征参数不准确的混叠和失真,这些混叠和失真大部分是由于人类发声器官本身和采集语音信号的设备所引起的。只有消除了这些影响,才能保证后续语音特征参数的质量,提高语音识别的效率。
2.1预加重
由于语音信号的平均功率谱会受到声门激励和口鼻辐射的影响,高频端大约在800Hz以上按6dB/oct (倍频程)衰减,频率越高,相应的分量幅度越小[8]。要提升信号高频部分,一般采用的措施是对信号s(n)进行预加重。使用数字滤波器的预加重通常是一阶的,即:
其中a为预加重系数,一般取a=0.9375。
预加重的主要目的是改善信号的高频分量,使信号的频谱平坦,以促进频谱分析或信道参数分析。此外,预加重在一定程度上还能抑制随机噪声。
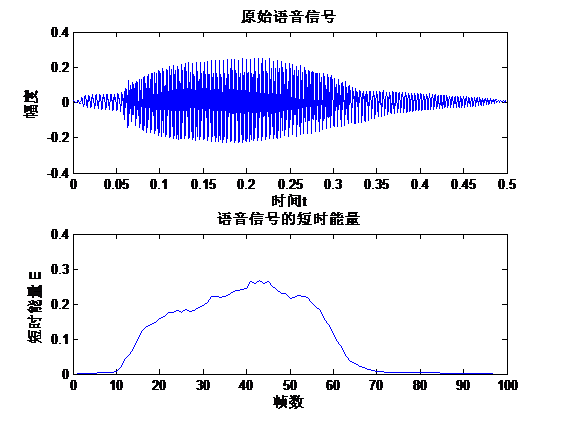
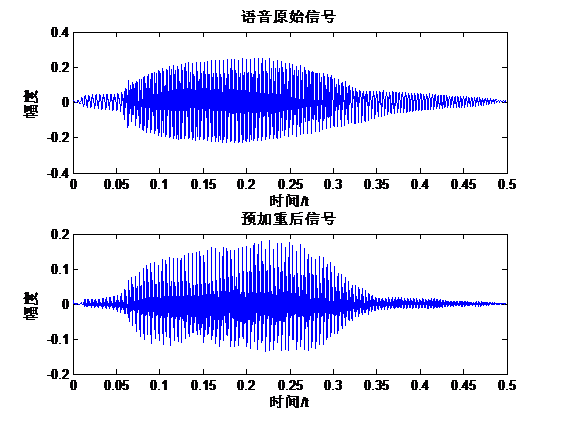 如图2.1,为时长为0.5s的原始语音信号和预加重后信号图形,信号波形并无显著变化。
如图2.1,为时长为0.5s的原始语音信号和预加重后信号图形,信号波形并无显著变化。
图2.1 原始语音信号和预加重后的信号波形
但是,图2.2中预加重前后的频谱比较表明,在频率的范围内,预加重前的频谱幅度高于预加重之后的;而当时,预加重后的频谱幅度则高于预加重之前的。根据比较,在预加重之后,信号的频谱变得稍微平坦。并且发现在低频部分信号稍微削减,但是在高频部分信号幅度得到补充。
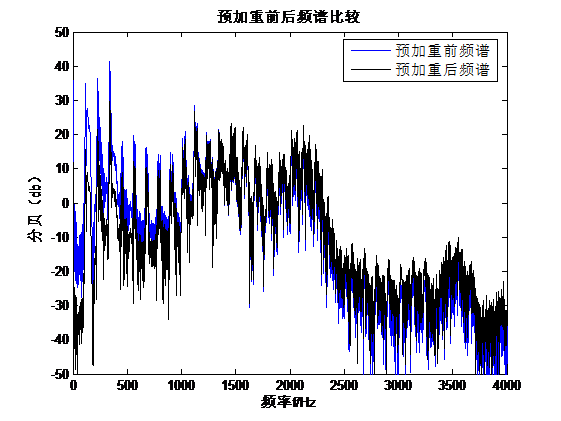
图2.2 预加重后信号及其频谱
2.2 分帧与加窗
由于语音信号是非平稳的并且具有时变特性,但是又由于人类声音发出器官肌肉运动的速度非常缓慢,可以认为语音信号局部稳定且具有短期稳定性[9]。因此,语音信号分析往往采用分段处理的方式来处理,每个分段是一帧,帧长一般为10ms~30ms。然后,对于长整型语音信号,特征参数是由每帧信号的特征参数组成的特征参数序列。。
分帧处理后,在帧与帧之间会出现不连续的情况。那样信号在分帧之后会越来越偏离离原来的语音信号(特别在帧交接处),因此,信号需要进行加窗处理[10]。除此之外,加窗处理还会让原本没有周期性的语音信号出现周期性变化。
加窗处理,即要将提取的帧信号乘以一个窗函数,如图2.3所示:

图2.3 一帧信号与窗函数相乘
加窗让帧信号的幅度在两端逐渐消失为零,如图5所示。加窗后,减弱了傅里叶变换后旁瓣大小以及频谱泄露,可以提高频谱的分辨率。但加窗的代价是信号的两端被削弱,并没有和中央部分一样得到强调。弥补这一点的方法是帧不应该被背对背截取,而是应该相互重叠部分。两个相邻帧的起始位置之间的时间差被称为帧移。帧移常常为帧长的一半。如果使用矩形窗口,则矩形窗口的频谱的高频分量影响信号的高频分量,所以通常使用汉明窗口或汉宁窗口。
16ms
5ms
图2.4 分帧示意图
图2.4中,每帧的长度为16ms,每两帧之间有的重叠部分,我们称对这个语音信号进行帧长为16ms,帧移为5ms的分帧。这样进行分帧,减少了两连续帧之间的信号断续的问题。
用的最多的三种窗分别是矩形窗、汉明窗(Hamming)和汉宁窗(Hanning),它们定义式分别是:
(1) | (2.2) | |
(2) | (2.3) | |
(3) |
| (2.4) |
第3章 特征参数提取
语音信号中包含很多特征参数,不同的特征参数表示不同的物理和声学含义。不同特征参数的选择对语音信号的识别也有不同的影响。原始语音信号是时域中的连续波形,若直接对原始信号进行分析处理,既费时费力,还会降低语音识别率。因此,良好的语音特征参数可以大大提高语音识别率。特征参数提取是为了获得与识别有关的有用信息并减少语音信号中的冗余信息。这样,既能减少识别处理量,又能更好地提高识别率。
所有模式识别不能避开的就是特征参数的提取了。早在20世纪40年代,人们就引入了可见语言的概念。可视语音是使用语谱图来描述语音信号[3]。因此语谱图中的语谱信息在当时常常以特征参数的方式应用于语音识别,其实至今仍有人使用语谱图进行语音识别。进入50年代后,人们不满足于语谱图的信息,开始在时域方向对语音信号进行研究,语音特征参数如振幅,短期平均能量,短时过零率和短时自相关函数被不断提出。随着识别技术的进步,人们发现语音信号在时域中的识别能力和稳定性已经不能满足识别技术的需要。然后开始提出使用频域参数,作为语音信号参数的一个特征,例如:共振峰,基音频率,线性倒谱对等。
总而言之,提取的特征参数要满足以下特征[11]:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: