深度神经网络压缩与量化算法研究毕业论文
2020-04-08 14:23:45
摘 要
由于相机对光照等环境因素的依赖性,利用激光雷达进行车周环境感知已经在自动化驾驶领域中受到了很大的关注。相关的基于深度学习的激光雷达目标检测算法也在这几年不断的出现并迭代改善,很大程度的改善了以前基于传统手工特征算法的准确性。但是基于深度学习的方法的一个较大缺点就是相比传统方法计算时间会较长,这在自动驾驶这样对实时性要求很高的系统中就存在实用性的问题。
本文主要关注深度学习的模型压缩量化方法及其相关特定的变种方法,如特殊的卷积核等。在此基础上,进一步将相关知识应用到实用激光雷达3D目标检测算法AVOD上。应用在无人驾驶系统激光雷达三维目标检测深度学习算法的深度学习模型压缩量化旨在加速激光雷达检测算法的模型推断时间,并在同时保证一定的 模型精度。 全文工作将分为以下几点:
第一,本文首先阐述本课题的研究背景及意义,并简要介绍深度学习模型压缩量化加速技术目前的常用方法;
第二,本文尝试使用模型剪枝方法来进行模型压缩;
第三,本文尝试使用模型量化方法以实现模型压缩;
第四,在自动驾驶 3D 目标检测领域,目前涌现出许多基于深度学习的方法,其中最热的属卷积神经网络(简称CNN),它有着更好的识别准确率和更强的鲁棒性。因此本系统采用基于 CNN 的最新方法 AVOD 进行基于激光雷达点云的 3D目标检测,并通过 MobileNets 及其剪枝模型对其进行模型加速压缩。
最后,本文总结了深度学习技术及其压缩量化任务上的应用前景,并提出对未来的展望。
关键词:模型量化, 模型剪枝, 激光雷达, 自动驾驶, 3D目标检测, 深度学习
ABSTRACT
Due to the camera’s dependence on lighting and other environmental factors, the use of laser radar for vehicle-period environment perception has received much attention in the field of automated driving. Relevant depth-learning-based lidar 3D detection algorithms have also been appearing and iteratively improved over the years, greatly improving the accuracy of previous traditional manual feature-based algorithms. However, one of the major drawbacks of the deep learning method is that the calculation time will be longer compared to the traditional method. This has practical problems in automatic driving systems that require high real-time performance.
This paper focuses on the model of deep learning, the compression and quantification method, and its related specific variant methods, such as special convolution kernels. On this basis, the relevant knowledge is further applied to the practical lidar 3D detection algorithm AVOD. The deep learning model used in the unmanned lidar for deep-learning 3D object detection algorithms is modeled with compression and quantification methods aimed at accelerating the model inference time of the lidar detection algorithm and at the same time guaranteeing a certain degree of model accuracy. The full text work will be divided into the following points:
First, this article elaborates the research background and significance of this topic, and briefly introduces the current common methods of the compression and quantification acceleration technology of the deep learning model;
Second, this paper attempts to use the model pruning method to compress the model.
Third, this article attempts to use model quantification methods to achieve model compression;
Fourth, in the field of automatic driving 3D target detection, many methods based on deep learning have emerged. Among them, the hottest convolutional neural network (CNN) has better recognition accuracy and robustness. . Therefore, this system adopts the latest CNN-based AVOD for 3D target detection based on Lidar point cloud, and accelerates the model compression through MobileNets and its pruning model.
Finally, this paper summarizes the application prospects of deep learning technology and its compression and quantification tasks, and puts forward the prospects for the future.
Key words: Model quantification, model pruning, lidar, self-driving, 3D detection, deep learning
目 录
摘要 I
ABSTRACT II
目 录 III
第1章 绪论 5
1.1课题背景和研究现状 5
1.1.1 研究背景 5
1.1.2 研究现状 6
1.2深度学习模型机器应用 7
1.2.1 传统方法 7
1.2.2 深度学习 7
1.3本文的内容安排 8
1.3本章小结 8
第2章 背景知识 9
2.1 前向神经网络概述 9
2.2 卷积神经网络概述 10
2.2.1 卷积操作 10
2.2.2 感受野 11
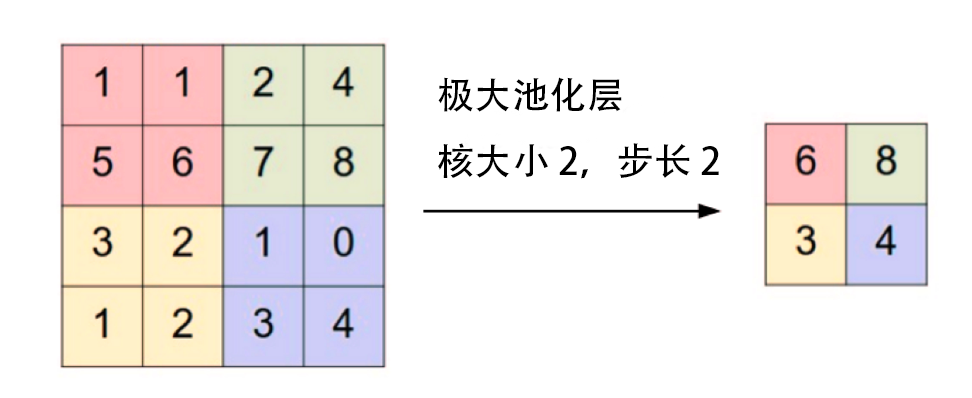
2.2.3 池化层 11
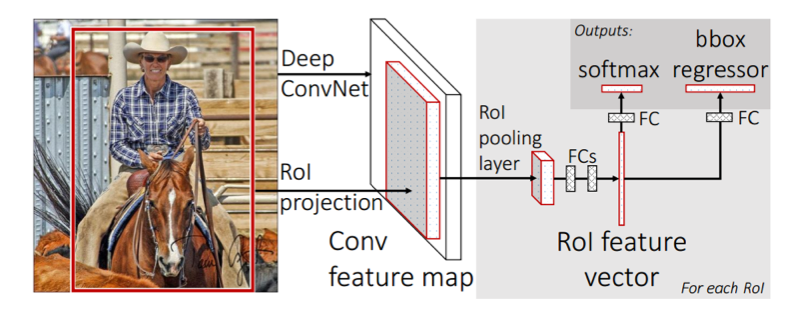
2.2.4 RoI池化 12
2.3 目标检测 12
2.3.1 传统目标检测器 13
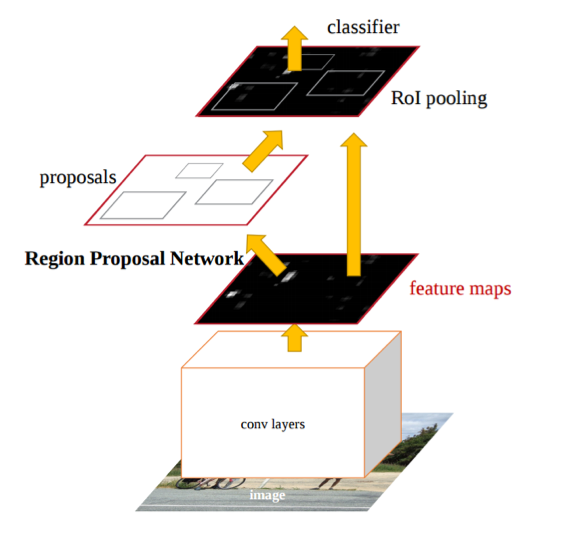
2.3.2 二阶段目标检测器 13
2.3.3 单阶段目标检测器 14
2.4 3D目标检测 15
2.5 目标检测方法评估指标 16
2.5.1 Bounding Box 评估 17
2.5.2 精确率与召回率 17
2.5.3 平均精度(AP) 17
2.5.4 平均朝向相似度(AOS) 17
第3章 深度学习模型量化 19
3.1 Dense Network 19
3.2 使用SmoothGrad技术进行卷积神经网络输出解释 20
3.2.1 算法实现 21
3.3 使用模型量化方法进行卷积神经网络尺寸压缩 23
3.3.1 数据处理 24
3.3.2 模型设计 24
3.3.3 算法实现 25
3.3 本章小结 26
第4章 深度学习模型剪枝 27
4.1 使用模型剪枝方法进行卷积神经网络尺寸压缩 27
4.1.1 数据处理 27
4.1.2 模型设计 28
4.1.3 算法实现 32
4.2 本章小结 35
第5章 基于AVOD的激光雷达点云3D目标检测及其优化加速 36
5.1 RGB图像输入 36
5.2 点云表征 37
5.2.1 BEV图计算 38
5.3 从RGV图与点云中生成特征图 39
5.3.1 VGG特征提取器 39
5.3.2 MobileNets特征提取器 41
5.4 多模态融合候选框生成 43
5.4.1 Anchor生成 43
5.4.2 3D候选框生成 43
5.4.3 损失函数 44
5.5 二阶段检测网络 44
5.5.1 3D候选框编码 44
5.5.2 显式朝向向量回归 45
5.5.3 生成检测结果 45
5.6 数据处理 45
5.7 实验结果 46
5.8 本章小结 47
第6章 总结与展望 49
6.1研究总结 49
6.2研究展望 49
参考文献 50
致谢 54
第1章 绪论
1.1课题背景和研究现状
1.1.1 研究背景
在过去几年中,深度神经网络在计算机视觉,语音识别和自然语言处理等领域的若干具有挑战性的任务中取得了最先进的性能。而深度神经网络的一个显着特征似乎已经将它们与其他机器学习模型区分开来,这就是它们随数据增长的能力。也就是说,随着训练集大小的增加,我们可以通过增加神经网络的大小(隐藏单元和层的数量,从而增加权重的数量)来继续提高分类精度,这不同于线性模型,其随着数据不断增长,其分类准确性将很快停滞。因此,我们可以继续提高神经网络的准确性,将其扩大并对更多数据进行训练。这意味 着我们可以期待在未来的实际应用中看到更大的神经网络。事实上,在计算机 视觉文献中报道的模型已经从1990年代的不足一百万重量增加到了2000年的数百万,并且在最近的工作中,模型已经超过了数十亿级(每个浮点值)。随着越来越多的数据和计算能力的推动,深度学习模型变得越来越深层,以便更好地从数据中学习。虽然这些模型通常部署在数据中心后端,但如要去保护用户隐私并减少用户使用模型的查询时间则需要将这些深度神经网络提供的智能迁移到移动计算设备。将大型精确的深度学习模型部署到资源受限的计算环 境(如手机,智能相机等)以进行设备实时推断时会带来一些非常关键的挑战。首先,最先进的深度学习模型通常具有数百万个需要O(MB)存储的参数,而、移动设备上的内存通常是有限的。此外,一个模型推断甚至需要调用O(10^9)存储器访问和算术运算的情况并不罕见,而所有这些都会消耗功率并散发热量,这会消耗有限的电池容量以及测试设备的热量最大限度。
这个问题最近引起了相当的关注。根据近来的研究,研究人员已经掌握了两个重要的事实。
- 目前那些我们知道如何训练以获得最优精度的大型神经网络通常包含非常显著的冗余度,这使得我们有可能去以相当的精度来找到更小的神经网 络。
- 通常如果我们首先训练一个大模型,然后以某种方式将其转化为较小模型(即“压缩”模型),相比于直接去训练一个小的模型可以获得 效果更好的结果。这两个事实也就让压缩量化深度神经网络成为了当前研究的重点。
1.1.2 研究现状
 面对这一问题,越来越多的工作也开始涌现出来,这些工作都旨在发现压缩神经网络模型的方法,同时限制模型质量的潜在损失。
面对这一问题,越来越多的工作也开始涌现出来,这些工作都旨在发现压缩神经网络模型的方法,同时限制模型质量的潜在损失。
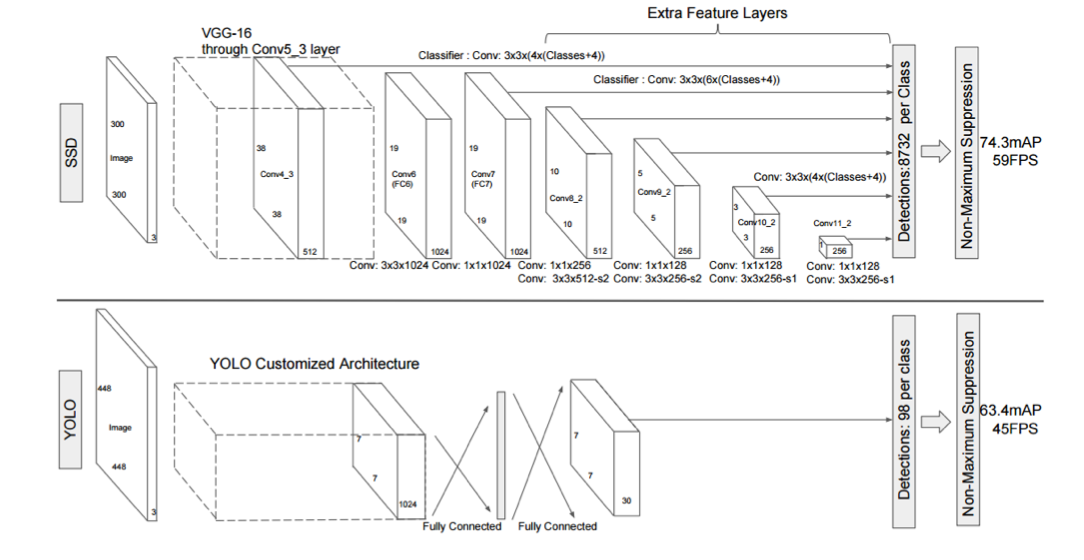
表1-1 ⽹络压缩不同⽅法的总结
近来这些模型压缩方法主要可以分为四类:参数修剪和共享,低秩分解, 转移/紧凑卷积滤波器和知识蒸馏。基于参数修剪和共享的方法探索了模型参 数中的冗余,并试图去除冗余和不重要的方法。基于低秩分解的技术使用矩阵/张量分解来估计深层 CNN 的信息参数。基于转移/压缩卷积滤波器的方法设 计了特殊的结构卷积滤波器来减少存储和计算复杂度。知识蒸馏方法学习蒸馏 模型并训练更紧凑的神经网络以再现更大网络的输出。
一般而言,参数修剪和共享,低秩因子分解和知识蒸馏方法可用于具有完全连接层和卷积层的DNN,从而实现可比较的性能。在另一方面,使用转移/紧凑型滤波器的方法仅适用于仅具有卷积层的模型。此外,低秩因子分解和基 于转换/压缩过滤器的方法均提供了端到端的流水线,可以很容易地在CPU/GPU环境中实现。而参数修剪和共享使用不同的方法,如矢量量化,二进制编码和稀疏约束来执行任务,这通常需要几个步骤才能达到目标。
1.2深度学习模型机器应用
1.2.1 传统方法
在深度学习技术受到广泛关注与应用之前,人们为了解决一些普遍的图像、语音问题而设计了大量的手工特征方法。比如一些应用在图像领域上的有。
• 用于边缘检测的Sobel、SIFT、HoG、SURF等图像特征。
• 用于曲线、直线检测的广义Hough变换。
应用在自然语音处理领域上的有。
• 用于文本分类的Adaboost, SVM等常规分类方法。
• 用于词性标注,命名实体识别等问题的条件随机场。
然而以上这些方法的一个大的缺点就是非常依赖人工特征的设计与选择,对不同的问题,需要分别进行单独的特征工程,因此很难去适应一些环境多变、复杂的场景。同时,即使在一些应用最成功的领域上,传统方法的效果也与人本身的视觉感知水平相去甚远。
从广义来看,这些视觉与语音问题的解决都可以看成学习一个将输入特征映射到指定输出的函数,而深度学习在学习不特定函数的强大能力使得其有非常非常大的潜力成为解决这些问题一劳永逸的方案,近几年来深度学习的极大成功也印证了这一点。
1.2.2 深度学习
深度学习技术其实就是机器学习下的神经网络技术分支,相较最简单的多层感知机模型,深度学习模型则变得更深(层数更多)、更大(规模数量)。
当前最主流的深度神经网络模型可以大致分类两类,一类是应用到视觉领域上的卷积神经网络CNN模型,一类是主要应用到自然语言及序列预测问题上的递归神经网路RNN模型,在最新的进展中,时序卷积网络TCN模型(即应用在序列预测问题上的卷积神经网络)也开始大方异彩,所以有理由相信在今后两种深度学习模型的差异性以及解决的问题也会极大程度的获得统一。
由于两者模型的差异性,目前模型压缩与量化的主要进展还是专注在CNN模型上,这其中也还包括设计CNN模型的专用的高效卷积核,对卷积核参数进行低秩近视等方法,以及将会介绍和实验的最新的3D目标检测算法AVOD也主要采用的是卷积神网络的架构,所以本文主要关注在对CNN模型的压缩量化上。
1.3本文的内容安排
本文的主要内容是首先对深度神经网络的剪枝、量化相关算法进行探索、调研、了解相关原理、尝试完成相关实验并给出实验结果。
在相关论文模型的探索基础上,本文也会进一步尝试进行实用性的实验,主要包括以下两步
1. 实现在自动驾驶领域上应用的最先进的激光雷达3D目标检测AVOD框架。
2. 根据该算法的特殊性进行相应的模型改变,使用已有的一些方法,以达到加速的使用效果,使得模型在车辆上离线部署时获得更大的优势。
1.3本章小结
本章首先介绍了深度神经网络量化与压缩的背景及其动机、意义,之后介绍了该问题上的最新研究进展,对比了传统方法与深度学习方法各自的优缺点,最后简短的说明了本论文的内容安排。
第2章 背景知识
2.1 前向神经网络概述
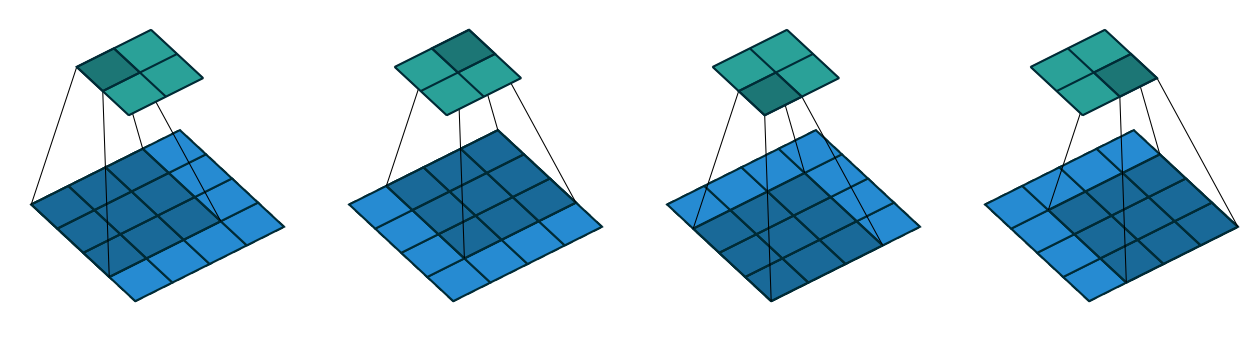
前向神经网络是在实用中最基础以及最常见的一种神经网络。前向神经网络的主要目标是去近似一个函数。一个前向神经网络定义了一个表示的映射关系,其中是函数的输入,是映射输入到输出的函数。一个通常的前向神经网络包括个隐藏层,这些隐藏层被参数化为个权重矩阵以及偏置向量。这些权重矩阵以及偏置向量组成了参数向量,通过该参数向量可以去定义前向神经网络尝试学习的函数。通过学习该参数,前向神经网络可以学习到最佳的一个映射关系。前向神经网络之所以被称为网络是因为它们通常可以通过不同的函数的组合来表示。一个神经网络可以用一个有向无环图来描述其内部每一层的函数具体是如何相互组合的。举例来说,如[figure2-1]所示,我们可以有三个函数,即具有三层映射的神经网络,其中三层映射分别表示为,以及,通过将三者链式链接起来为,一次得到整个神经网络。其中即是输入的某种量化特征。进一步的以图像为例,通过三层的函数连接,神经网络可以逐层的学习带有层次性的特征,如底层的特征代表图像的边缘、界限与直线,高层的特征则代表更加复杂的目标形状、属性。通常一个学习好的神经网络会去查找输入的特定特征,当该神经网络看到之前没有见到过的样本的时候,它就会去计算它学习到需要查找的特征的概率,从而对新样本进行目标推断,以此而具有外推、学习能力。
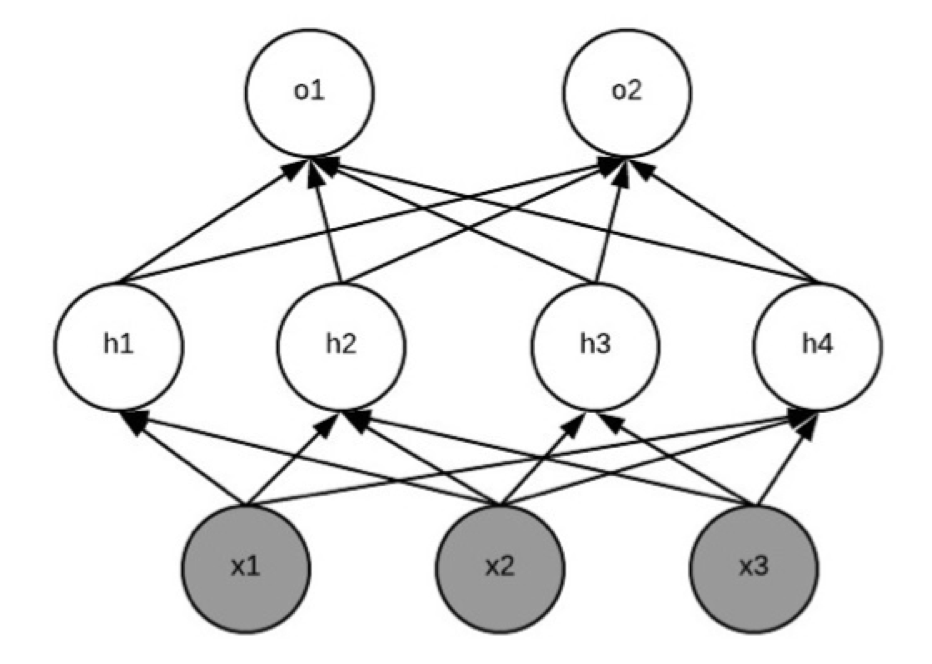
图2-1 前向神经网络
2.2 卷积神经网络概述
卷积神经网络是一种专门设计来处理具有网络状拓扑形状数据的神经网络,通常可以简称为CNNs或者ConvNets。这种神经网络在计算机视觉任务中获得了非常大的成功,几乎带动了这几年计算机视觉领域的大部分进展。
2.2.1 卷积操作
卷积神经网络就是一种对输入应用卷积操作的简单神经网络。在数学上,卷积定义为作用在两个函数与以产生第三个函数。通常可以表示为
一个通常的解释就是卷积的输出是的加权和,通过改变的大小,权重函数对输入函数的不同定义域也会给予不同的权重。再次角度上,一般被看做是输入函数,则被成为核函数,输入则可以看做是特征图。在计算机数据中,输入的时间和空间大多数都是离散化的,因此我们可以定义离散的卷积
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: