基于深度学习的图像复原方法研究毕业论文
2020-02-19 07:57:01
摘 要
本文的任务是基于深度学习的图像复原方法研究,我针对课题任务要求查阅了大量的资料,了解了图像复原的一些方法和深度学习方法,发现卷积神经网络比较适用于图像复原领域,所以采用卷积神经网络这种深度学习方法来完成图像复原工作。同时,也对评价图片质量的标准有了一定的了解,决定采用峰值信噪比这一评价标准。然后,我采用Matlab软件完成了基于超分辨率的卷积神经网络(SRCNN)的图像复原,并且在SRCNN的基础上对其网络结构加以改进,搭建了FSRCNN和VDSR这两种网络模型,并对这3种模型加以训练和仿真,获得3组评价图片质量的峰值信噪比的数据。通过对这3组数据的对比分析和图片复原前后的比较发现,这3种网络模型复原图像的质量相差不多,但FSRCNN和VDSR这两种模型在运行速度上有着明显的提升。
关键词:深度学习;卷积神经网络;超分辨率;峰值信噪比
Abstract
The task of this paper is to study the method of image restoration based on deep learning. I have consulted a large amount of data for the task requirements, and learned some methods of image restoration and some methods of deep learning. It is found that the convolutional neural network is more suitable for image restoration, so it is adopted. Convolutional neural network is a deep learning method to complete image restoration. At the same time, we also have a certain understanding of the criteria for evaluating picture quality, and decided to adopt the peak signal to noise ratio evaluation standard. Then, I completed the image restoration based on Super Resolution Convolutional Neural Network (SRCNN) by using Matlab, and improved the network structure based on SRCNN, and built two network models, FSRCNN and VDSR. These three models were trained and simulated to obtain three sets of peak signal-to-noise ratio data for evaluating picture quality. By comparing the three groups of data and comparing the pictures before and after the restoration, it is found that the quality of the restored images of the three network models is similar, but the two models of FSRCNN and VDSR have a significant improvement in the running speed.
Key words: deep learning; convolutional neural network; super resolution;peak signal to noise ratio
目录
摘要 I
Abstract II
第1章 绪论 1
1.1课题研究背景和意义 1
1.2国内外研究现状 2
1.3研究的基本内容 3
1.4本文结构 4
第2章 图像复原理论基础 5
2.1图像盲复原 5
2.2图像退化 5
2.2.1图像的退化过程 5
2.2.2常见的退化函数 6
2.3图像盲复原过程模型 8
2.4噪声类型 9
2.5图像质量评价标准 9
第3章 基于超分辨率卷积神经网络的图像复原 11
3.1卷积神经网络简介 11
3.1.1输入层 12
3.1.2卷积层 12
3.1.3激活函数 13
3.1.4池化层 14
3.1.5全连接层和输出层 15
3.2 SRCNN 15
3.3 FSRCNN 17
3.4 VDSR 18
第4章 基于卷积神经网络的图像复原的仿真 20
4.1 Matlab环境的搭建 20
4.2 SRCNN仿真分析 21
4.2.1流程图 21
4.2.2 SRCNN仿真结果分析 22
4.3 FSRCNN仿真分析 25
4.3.1流程图 25
4.3.2 FSRCNN仿真分析 26
4.4 VDSR仿真分析 29
4.4.1流程图 29
4.4.2 VDSR仿真结果分析 30
4.5本章小结 32
总结 33
致谢 34
参考文献 35
第1章 绪论
1.1课题研究背景和意义
图像,在我们的现代社会中发挥着无可替代的作用,广泛应用与天文拍摄和预测、交通安全监控、生物医学成像等领域。而在日常生活中,人们经常使用手机、摄像机等设备拍摄照片来记录生活中值得记念的瞬间,以便于以后的回忆。而在日常生活中毕竟只有少部分专业的摄像师,而大多数人则是普通人,在照片拍摄后,往往会发现照片的质量不能达到自己的期待,往往会出现一些自己无法想象的模糊[1]。这是因为在图像的形成、传输、存储、记录和显示过程中,由于各方面的因素,比如光线、设备晃动和存储设备太差等,会造成图像的模糊和变形,从而造成图像的退化[2]。图像的信息会部分甚至完全丢失,从而影响正常的使用。但我们在使用图像时对图像的质量有着较高的要求,要想得到一副高质量的原始数字图像,在很多情况下,我们需要对图像进行复原处理,使其和原图像尽可能的贴近,达到我们的使用需求。
点扩散函数(Point Spread Function, PSF)[3-4]是否已知,是衡量图像复原类别的标准:当点扩散函数已知时,复原图像为非盲复原;当点扩散函数未知时,复原图像称为盲复原[5-6]。非盲复原方法[7]一般有逆滤波、维纳滤波法和最小二值法等传统方法,但这类方法需要大量的先验知识(比如PSF和噪声函数),需要先对退化图像的模糊核进行估测,而且稳定性不够强,复原的图像具有伪迹效应。而且我们在现实中不可能知道太多的先验知识,不可能拿到一张退化图片就知道它的点扩散函数和噪声函数,所以,就需要找到一种不需要太多先验知识的方法了。而盲复原方法则正是在大量先验条件未知的情况下进行图像复原,而图像盲复原方法存在两种:一种是先估测模糊核,然后用经典的算法估计出原始的清晰图像,另一种则是对模糊核和清晰图像同时进行估计,两者交替进行学习。而这几年,在图像复原领域比较适合深度学习的方法就是卷积神经网络(Convolutional Neural Networks,CNN)[8-9],它的权值共享网络结构与生物神经网络更加类似,降低了网络模型的参数复杂度。它的优点在于可以直接将图片作为网络结构的输入,减少了网络模型的运算量。同时,图像盲复原是一个病态的逆问题,是一个端到端的问题,这里,我们采用近年来比较热门的超分辨率技术[10](Super-resolution, SR),直接实现图像从低分辨率到高分辨率。所以,我采用基于超分辨率的卷积神经网络[11](Super resolution using convolution neural network,SRCNN)的图像复原方法作为我们的研究对象,来实现设计要求。
1.2国内外研究现状
图像复原在最近几十年里取得了长足的进步,由传统的逆滤波法、维纳滤波法和最小二乘法这类需要各种先验条件的方法,但这类方法所需要的限制条件太多,且复原的效果不算太好。所以,图像复原领域的学者们就一直在研究着新的方法。到后来的各种算法,包括贝叶斯复原法[12]、遗传进化法[13]和BP神经网络[14]。我们复原图像主要是为了复原图像的细节,即图像的高频信息。最后,经过查阅资料,决定采用当下比较热门的超分辨率技术结合卷积神经网络来实现图像复原。下面我来介绍一下图像超分辨率研究现状。
首先提出了基于序列或多帧图像的超分辨率重建问题[15]的是Tsaiamp;Huang。1991年和1992年,B.R.Hunt和PJ.Sementilli在贝叶斯分析的基础上,提出了泊松最大后验概率复原方法[17],并于1993年对超分辨率的特性进行了分析和定义,图像超分辨率的能力由物体的空间限制、噪声和采样间隔共同决定。
2016年香港中文大学的Dong Chao首先将卷积神经网络引入到SR技术领域[18],提出并设计了基于卷积神经网络的超分辨率图像复原方法,该方法以深度学习与传统稀疏编码之间的关系作为基础,网络结构搭建用3个卷积层表示图像块的特征提取、非线性映射和图像重建,构成网络结构,实现图像重建。这种网络结构的层数比较浅,收敛速度较慢。
之后,香港中文大学的Dong Chao, Xiaoou Tang等人又在SRCNN的基础上,对三层卷积层重新做了调整,提出了FSRCNN这种改进后的模型。
在SRCNN的基础上,用极深的网络结构VGG[19]和残差网络[20]的思想相结合,设计了网络层数为20层的SRCNN网络,简称VDSR[21]。只需训练HR图像与LR之间的细节残差,采用较高的学习率加快收敛速度,提升了网络的性能。
西安交通大学的Liang提出了整合先验信息的超分辨率复原方法[22]。图像的先验信息也是图像的重要组成部分,首先通过SRCNN网络模型进行不同尺寸图像的结构相似性学习;然后,在SRCNN末端连接一个特征提取层,得到图像的梯度信息;最后,采用信息融合的策略得到重建图像。
1.3研究的基本内容
本文研究的基本内容是基于深度学习的图像复原方法研究。我先介绍了图像复原方法方面的一些基本知识,比如图像的退化函数、噪声函数[23]和评价图像质量的标准[24-25],最后选用峰值信噪比来衡量图片复原效果。我在经过查阅大量资料和文献后,对深度学习方法也有了一些简单的认识,发现卷积神经网络是比较适合做图像复原的。并且由于我们所做的图像复原是一个病态的逆问题,是将退化图像复原成为清晰图像。我决定采用可以将低分辨率图像重建成高分辨率图像的超分辨率技术。所以我最后决定采用基于超分辨率的卷积神经网络设计一种有效的图像复原方法,然后在这种网络结构的基础上加以改进,搭建了FSRCNN和VDSR这两种网络模型,然后使用大量的图像数据集对这3种网络模型进行训练,得到可供调用的网络模型进行图像的复原处理。最后,我用这3种方法对这19张图片进行复原仿真,并且在网络放大因子为2,3,4的情况下,得到9组峰值信噪比数据,最后进行分析比较这3种网络模型的性能优劣,得出相应的结论。
1.4本文结构
本文大致可分为5个部分,具体结构如下图1.1所示。
第1章,绪论。本章首先描述分析了图像复原技术研究的背景以及在现今社会发展中发挥的重要作用,然后总结了图像复原技术的发展历史以及国内外的发展现状,继而指出本文研究的基本内容,最后对用一张结构框图对本文的组织结构进行一个大体的概括。
第2章,图像盲复原理论基础。本章主要对图像盲复原进行较为详细的介绍,先介绍了什么叫图像盲复原,然后对图像的退化和重建过程做了大体的介绍,最后对影响图像的噪声类型和评价图像质量标准的指标做了简单的介绍。
第3章,基于超分辨率卷积神经网络的图像复原。本章主要介绍了CNN的几个常用的网络层和我采用的SRCNN、FSRCNN和VDSR 这3种基于超分辨率的卷积神经网络模型的各自特点和相对于SRCNN的改进点和复原步骤。
第4章,基于卷积神经网络的图像复原的仿真。本章主要介绍了Matlab环境的搭建[26],以及SRCNN、FSRCNN和VDSR这3种网络模型各自的流程图、仿真获得的复原图像和以及在网络放大因子为2、3、4的情况下,9组图片的峰值信噪比,然后对这些数据进行分析得出结论。
最后,对全文的研究内容进行总结,指出这3种方法的优劣并做出分析,然后写出自己在这段时间的收获需要改进的地方。
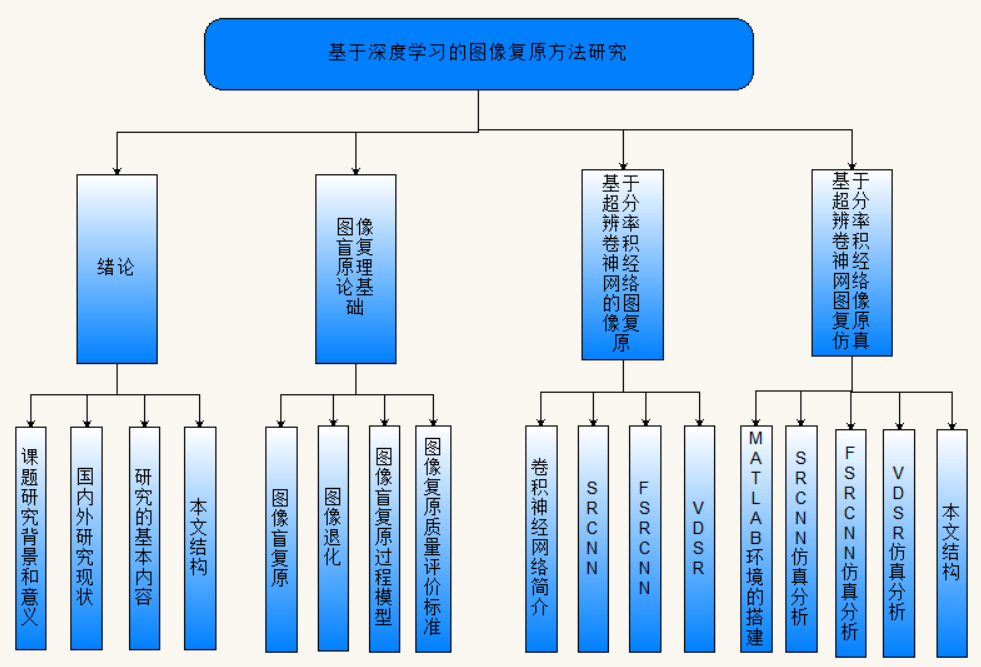
图1.1 本文结构图
第2章 图像复原理论基础
图像复原是一个较为复杂的过程,为了更好的了解图像复原过程和特点,下面我将简单的介绍一下图像复原的理论知识。
2.1图像盲复原
模糊图像形成的实质上是一个卷积的过程,即点扩散函数与清晰图像卷积得到模糊图像。图像复原的主要目的就是将退化后的图像恢复成清晰的图像,是一个解卷积的过程。传统的图像复原方法(如逆滤波法、维纳滤波法和最小二乘法等)是在成像系的点扩散函数已知或者可以估算出来的情况下,直接对退化图像进行复原,这一类方法也称之为非盲复原。但在实际处理问题时,我们往往无法获取较多的先验知识(即点扩散函数和噪声函数),所以我们只能这些条件未知的情况下进行图像复原,所以这类问题被称之为图像盲复原。
2.2图像退化
2.2.1图像的退化过程
图像在形成、传输、存储、和调用过程中,往往由于光线、设备抖动和系统噪声的影响,会造成图像的变形和模糊,从而导致图像的退化。这些造成的主要是图片的退化,而我们在实际中除了成像系统本身的原因之外,往往还会遇到噪声的干扰。
所以,图像退化一般是看出模糊算子和加性噪声的干扰。过程如下图2.1所示:
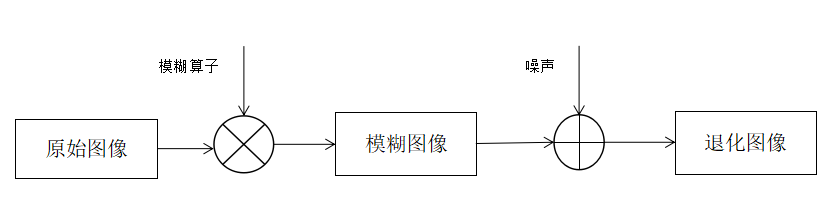
图2.1 图像的退化过程
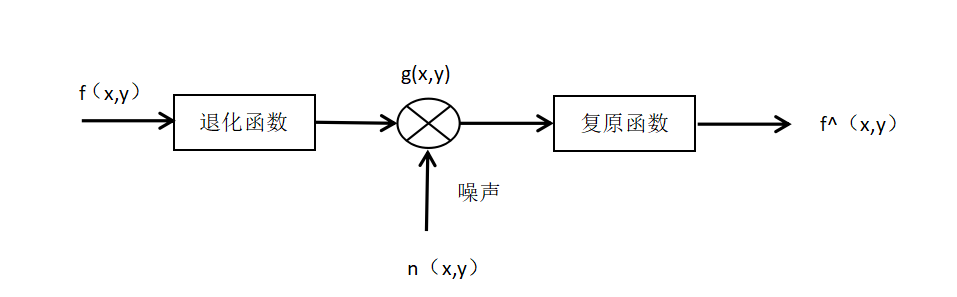
图像盲复原是指在点扩散函数未知的情况下,从退化图像中复原出清晰图像,因此我们需要分析是什么原因导致了图像的退化。我们需要建立一个适当的数学模型,然后从建立的数学模型中反解出清晰图像。在我们的实际生活中,一般有两种原因会导致图像的退化,主要因素是退化函数,次要因素是随机的加性噪声。一般情况下,想建立一个通用的数学模型对所有退化图像进行复原,难以实现。一般情况下,大部分图像的退化过程都可以近似看做一个线性过程。所以,在实际工程中,基本采用线性不变系统再加上噪声来模拟图像退化的过程。图像的退化模型如下图2.2所示。

图2.5 图像的退化模型
由此可知图像退化模型函数表达式如下式(2.1)所示:
 (2.1)
(2.1)
这个过程也可以在频域内进行表示,如下式(2.2)所示:
 (2.2)
(2.2)
式中各函数意义如下所示:
- f(x,y)——为成像系统的输入函数,即原始图像;
- g(x,y)——为成像系统的输出函数,即退化图像
- n(x,y)——表示加性的观测噪声函数;
- H ——可表示为H(u,v),称为点扩散函数或者模糊函数。其中(u,v)为退化函数所对应的像素点位置的空间坐标。运动模糊(Motion Blur)
2.2.2常见的退化函数
退化函数是指在不加噪声函数的情况下,造成图像退化的主要因素,即图像退化后的点扩散函数。常见的退化函数有以下几种:
1、运动模糊是指被拍摄物体相对于摄像装备的快速运动而导致的。运动模糊图像如下图2.2所示,运动模糊的退化函数可用下式(2.3)表示:
其中vx和vy分别是水平和垂直方向上的镜头和运动物体的相对运动速度,当水平或者垂直方向上有一个速度为0时,该模糊函数退化为一维运动模糊函数。


图2.2 运动模糊图片
2、散焦模糊(Dfocus Blur)

图2.3 散焦模糊图片
散焦模糊是由于在拍摄过程中被拍摄物体与镜头的距离的不同,散焦模糊无可避免。在该模糊中,由于摄像头光圈的影响,会使输入的光点扩散成为圆形的模糊圈,所以也称之为镜头模糊。散焦模糊图像如下图2.3所示,摄像机的完整成像模型包括许多参量,如焦距、光圈大小、形状、物距、入射光波波长和衍射作用等。对于一张给定的图像,我们往往不知道这些参数。所以,当聚焦不良造成的模糊较大时,光学系统散焦造成的图像退化对应的模糊函数是一个分布均匀的圆形光斑,圆形光斑的半径为R,散焦模糊的退化函数可用下式(2.4)表示:
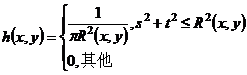 (2.4)
(2.4)
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: