个性化服装搭配方案的研究毕业论文
2020-04-01 11:01:46
摘 要
如今,随着电商系统的不断发展,越来越多的人选择在线购买商品,人们在选择商品时的可选项大大增加。各个电商平台也为了能够给人们提供更好的购物体验,在种类繁多的商品中为用户提供高效准确的推荐方案。目前,个性化服装搭配在电商推荐中也越来越被重视。本项目主要研究内容包含以下几个方面:(1)基于商品内容的模型构建算法实现个性化的服装搭配。通过商品内容的特征值寻找相似商品,进而从其搭配套餐中获取相似商品集合,找到相似商品集合的搭配套餐中的商品,即与待测商品搭配。从而获取与商品搭配的商品集合。(2)基于用户行为的模型构建算法实现服装搭配。分析用户一段连续时间内的购买历史行为,挖掘用户的偏好类别,找出在同一购买日期上的商品的搭配的可能性。从而推断出服装的搭配情况。
本项目使用了两种推荐模型来实现个性化的服装搭配推荐,并分析了在模型构建中各种实现方式的优缺点。本项目假设,通常情况下人们购买的商品的搭配是符合大众的主流搭配的。最后在实验上本项目提出了一些关于python进行数据挖掘的性能优化方法。
关键词:推荐系统;服装搭配;商品相似;用户行为分析;模型融合
Abstract
Nowadays, with the continuous development of the Electronic Business system, more and more people choose to buy goods online, and the selection what people can choose are greatly increased. Every Electronic platform also provides to users with efficient and accurate recommendations which use a wide range of items in order to provide people, for a better shopping experience. At present, personalized clothing matching is increasingly important in bussiness recommendations. The main research contents of this project include the following aspects: (1) The model use algorithm which based on item content realizes personalized clothing collocation. The similar item is found through the feature value of the item content, and then the similar item collection is obtained from its matching package, and the commodity in the matching package of the similar item collection is found, that is, it is matched with the item to be measured. In order to obtain a collection of items that are collaborated with the item. (2) A model-building algorithm based on user behaviors to achieve garment matching. Analyze the user's purchase history behavior over a continuous period of time, tap the user's preference category, and find out the possibility of collocation of goods on the same purchase date. In order to infer the matching of clothing.
This project uses two kinds of recommendation models to achieve personalized clothing matching recommendations, and analyzes the advantages and disadvantages of various implementations in model building. This project assumes that the collocation of goods purchased by people is usually in line with the mainstream of the public. Finally, in the experiment, this project proposes some performance optimization methods for data mining in python.
Key words: Recommend System; Clothing Collocation; Commodity Similar;
User Behavior Analysis; Model Fusion
目 录
第一章 绪论 1
1. 1 研究背景及意义 1
1.1.1 目的及意义 1
1.2 研究现状 1
1.3 关键问题和研究内容 2
1.4 进度安排 2
第二章 项目数据集 4
2.1 赛题介绍 4
2.2 数据集介绍 4
2.2.1 用户购买行为表 4
2.2.2 商品详情表 5
2.2.3 商品搭配表 6
2.3 数据预处理 7
2.3.1数据不完整 8
2.3.2 数据简化 8
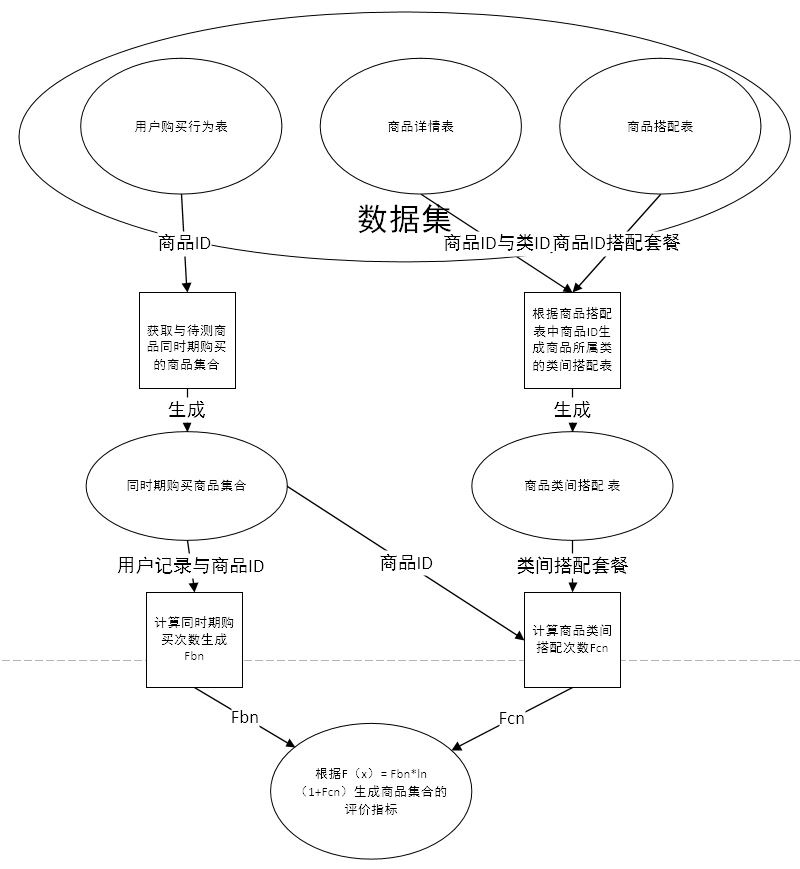
第三章 推荐模型构建 10
3.1 购物分析 10
3.2 基于商品内容模型 10
3.3 基于用户行为模型 12
3.4 模型融合 14
第四章 数据实验与结果 16
4.1 实验环境与运行工具 16
4.2 主要运行库介绍 16
4.2.1 Numpy 16
4.2.2 Pandas 16
4.2.3 Jieba 16
4.3 模型实现程序 17
4.3.1 数据预处理模块 17
4.3.2 基于商品内容模型 18
4.3.3 基于用户行为模型 19
4.3.4 多模型融合模块 20
4.4 实验结果及算法优化 21
4.4.1 实验结果 21
4.4.2 算法优化 21
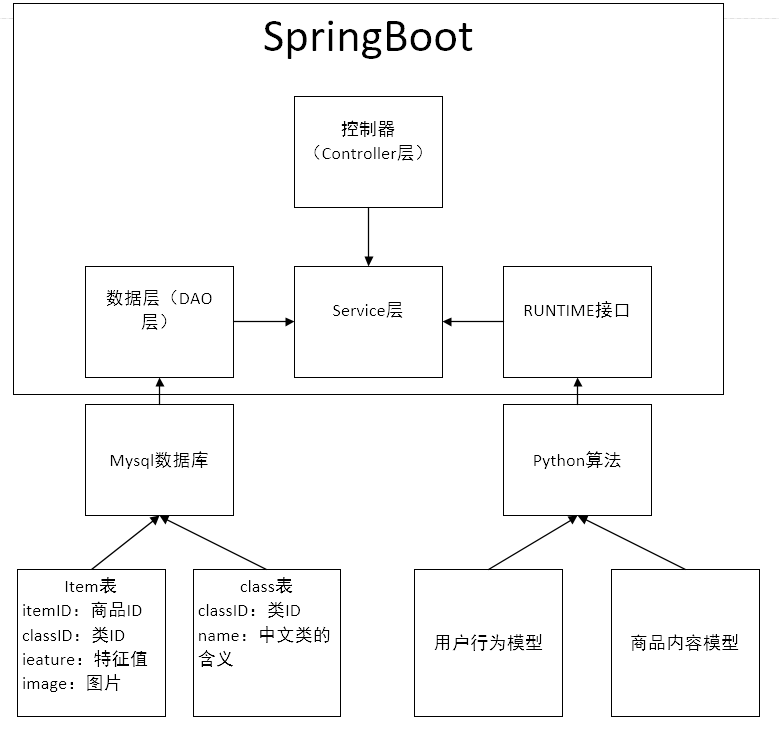
第五章 展示系统设计 23
5.1 功能概述 23
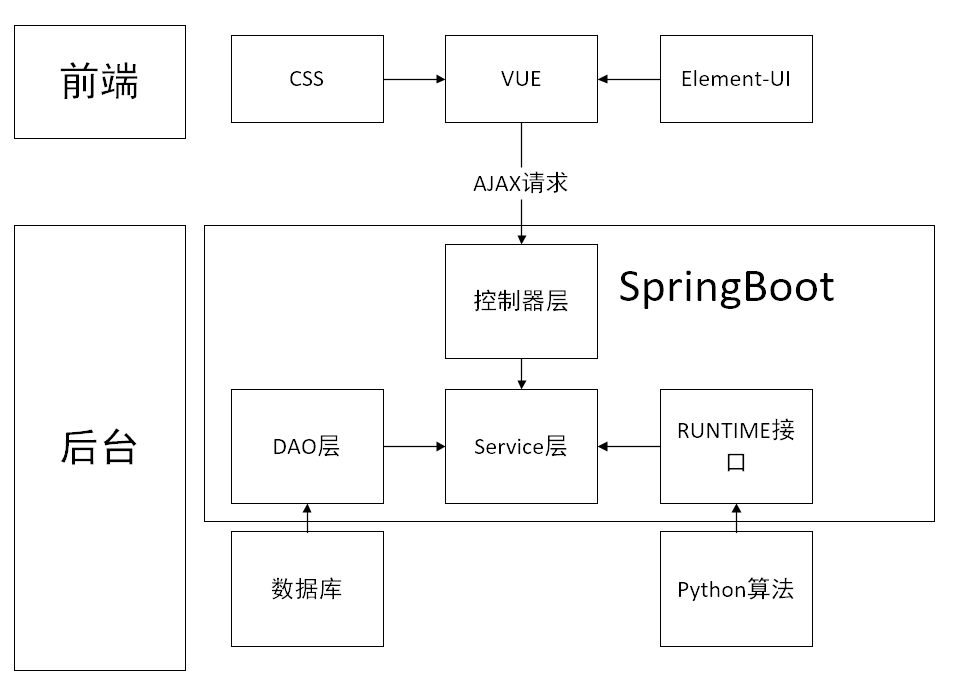
5.2 架构设计 23
5.2.1 相关平台介绍 24
5.3 展示系统实现 26
5.3.1 后台系统 26
5.3.2 前端界面设计 27
第六章 结论 31
致谢 32
参考文献 33
第一章 绪论
1. 1 研究背景及意义
1.1.1 目的及意义
随着移动互联网的发展和电商系统的深入连接到每一家每一户,让人们做到“在家买尽世界”。电子商务平台方便了人们的商品购买,通常会给出一个较为全面的商品说明,其中包含图片、评论和文字简介。但是由于平台上同一类别的商品众多,相似产品数量过大,以至于用户挑选商品时花费大量时间来筛选出想要的产品。例如:淘宝上搜索“牛仔裤男”的商品数目都达到上万。这种看似为人们提供了更多的选择但其实也带来很多“信息过载”的问题。为了解决信息过载,一般的平台都是采用信息检索的方式来筛选用户所需要的商品,或者采用推荐系统去分析用户特征和用户的需求来解决这个问题。
其次,电子商务平台无法提供像实体店类似的导购员的服务,一个好的导购员能根据用户的喜好和风格来个性化推荐服装的搭配。为了能够提供更好的购物体验,电子商务平台应向客户提供和实体店类似的个性化服装搭配的推荐服务,以便能更好的扩张和方便人们购物。
个性化服装搭配的研究不仅能够帮助用户在搜索时节省发现商品的时间,还能做到类似实体店导购员的个性化搭配,帮助用户搭配出适合自己的方案。
1.2 研究现状
在电商平台越来越普及的时候,人们开始对个性化推荐服务重视了起来。以智能推荐系统为服务热点的平台也越来越多了。例如:亚马逊,淘宝,京东等展示商品时使用的都是综合排序或者智能排序。当前对于人们的个性化推荐系统的发展也十分迅速。
推荐系统的非形式化概念是在1997年Resnick 和 Varian提出来的:“它是利用电子商务 网站向客户提供商品信息和建议,帮助用户决定应该购买什么产品,模拟销售人员帮助客户完成购买过程”[2]。现有的推荐方法如下几种:
- 基于内容的推荐:根据用户选择的对象的内容,对对象的属性进行分析。推荐和其属性类似的对象,是一种Item-to-Item Correlation 方法[4]。获取对象的内容特征是一种信息检索方法[6],比如文本特征在信息检索中最经典的是词频-倒排文档频率(TF-IDF)[5]。获取相似属性的对象通常使用贝叶斯分类算法、神经网络、基于向量的表示方法等[7]。基于内容的其他研究方向还包括自适应过滤[8]和阈值设定[9]等。
- 基于用户行为的推荐(协同过滤推荐):基于用户的协同过滤推荐是近十多年来发展很快的推荐技术。最早的研究有有 Grundy system[10]等。大概有两种此领域的算法,启发式和基于模型的方法。启发式[11]用一个和待推荐用户相似用户的对一个对象行为来预测该待测用户对此对象的行为 。基于模型的方法[11]。把对对象的行为放入一个模型中,用概率的方式进行处理。
随着技术的进步,推荐系统的不断发展和应用,用户的要求变高了,导致兼备多样性和准确性的推荐系统受到人们的喜爱,做到这一点的只有模型混合推荐。Rojsattarat E 和 Soonthornphisaj N 提出一种基于支持向量机的内容预测与协同过滤推荐的解决方案,能够较好的实现推荐[13],而对于推荐技术的融合,Zhang Hurley是通过暴力融合的方式把重合度最低的两个部分的推荐结果进行融合[15]。
1.3 关键问题和研究内容
- 基于用户行为的模型构建
本项目使用的数据为百万级用户,千万级行为的量,平均下来每位用户购买行为10,对于根据用户的购买行为进行分析,发现用户购买商品占所有的可以选择的商品的比率是十分低的,数据十分稀疏。所以解决数据稀疏,通过计算用户行为是当前研究推荐算法的问题之一。
- 基于商品内容的模型构建
商品搭配里面的数据是有一套或者多套的,而且在同一个搭配中还可以在相似产品中进行替换。例如假设待测商品a,计算与商品b的相似度(已知与b搭配的商品有c,d,e)这便有两个问题:
- 如何计算两个商品的相似度?
- 根据ac,ad, ae的相似度如何确定a与c,d,e之间的搭配度。
- 多推荐模型融合问题
如何把上面的多个推荐模型进行融合获取最佳匹配是一大问题。每种推荐模型都有其各自特点,且其模型的依据都不相同。
1.4 进度安排
- 2018/1/14—2018/2/28:确定选题,查阅资料和文献,外文翻译和撰写项目开题报告;
- 2018/3/1—2018/4/30:完成解决方案合理性、科学性认证,包含算法的设计与实验结果分析;
- 2018/5/1—2018/5/25:撰写及修改毕业论文;
- 2018/5/26—2018/6/6:准备答辩
第二章 项目数据集
本章介绍本项目使用的数据集的来源和数据结构等内容。对原始数据的预处理的方法和基本处理思路。
2.1 赛题介绍
本项目的数据集采自阿里天池大赛—“阿里巴巴大数据竞赛”,是阿里主办的大数据比赛,是基于淘宝上海量的真实用户的访问数据的推荐算法大赛[23]。主要目的就是为了让高校的学生利用阿里巴巴的大数据平台,解决实际问题。
本项目是天池大赛的题目“ 淘宝穿衣搭配-挑战Baseline”。淘宝网是阿里巴巴旗下的中国最大的网购零售平台,其中服装鞋包等商品占据绝大的市场份额。个性化服装搭配是服装鞋包导购中非常重要的研究课题。淘宝的穿衣搭配算法竞赛参提供搭配专家建议的搭配组合数据,初赛还提供了百万级别的淘宝商品的文本和图像数据及用户的脱敏行为数据。目的就是为用户提供个性化的穿衣搭配方案[19]。
2.2 数据集介绍
共有三个txt文件用以保存数据。每个文件是一个数据表。
2.2.1 用户购买行为表
文件user_bought_history.txt用以保存用户购买历史记录,文件大小为329M字节,共13611038条记录。格式为:“用户ID 商品ID 购买日期”,以空格为分隔符表示了用户购买行为中的信息,如图2.1示例。
表2.1 用户购买行为表结构说明
名称 | 类型 | 说明 |
|---|---|---|
用户ID | Int | 用户编号 |
商品ID | Int | 商品编号 |
购买日期 | Int | 用户购买商品的日期 |

图2.1 用户购买行为的数据格式
图2.1中第一行数据的含义为:“用户ID为1465121在20140822的这个时间购买了ID为3269934的商品”。本表中的数据用户ID和商品ID皆为脱敏数据,通过用户ID在淘宝网上是无法查到用户。此数据表中的商品ID和以下的数据表中商品ID也是对应的。
2.2.2 商品详情表
文件名dim_items.txt用以保存商品的详细信息。大小为50M字节,一共499984行。表示包含近50万个商品的信息。格式为:“商品ID 商品所属类ID 特征值”以空格为分隔符,一行数据表示商品的详细信息。如图2.2示例。
表2.2 商品详情表结构说明
名称 | 类型 | 说明 |
商品ID | Int | 商品编号 |
商品所属类ID | Int | 该商品所属类的编号 |
特征值 | String | 该商品的特征号的集合 |
如图2.2的数据的含义为:“商品ID为29,商品所属类ID为155,商品特征值为123950,53517,106068,59598,7503,171811,25618,147905,203432,123580,178091,154365,127004,31897,82406”。其中123950,53517等表示商品ID为29的商品的某些属性标签,由于使用脱敏数据,无法进行猜测其具体指代。商品所属类ID表示此商品所属的类别,多个商品可以属于同一商品所属类,即它们拥有相同的类ID。虽然商品类ID不唯一但是商品ID在此数据表中是唯一。

图2.2 商品详情表数据结构
由图2.2可以看出,此数据表的商品特征值数目不固定,维度不统一,无法进行下一步计算。因此为了统一特征值的维度接还要进行维度统一化。
2.2.3 商品搭配表
文件名dim_fashion_matchsets.txt用以保存商品的搭配信息。 大小为753K字节,一共23105行。格式为:“行号 商品ID;商品ID;商品ID ”,以空格来分割行号与商品ID,并用分号和逗号分隔表示一行表示商品的搭配套餐信息。如图2.3示例。
表2.3 商品搭配表结构说明
名称 | 类型 | 说明 |
行号 | Int | 表示为当前搭配的下标 |
商品ID | String | 一组商品搭配的集合 |

图2.3 商品搭配表数据结构
图2.3第一行数据表示:“ID为160870的商品和ID为3118604的商品是搭配的”。商品搭配表的数据结构说明如下:其中使用分号进行分割的表示可以搭配的,使用逗号进行分割的表示这是同一类商品只能相互进行替代不能相互搭配。例如图2.3的第三行数据“893028;993019,1375599,1913565,3036503”表示商品ID为893028的商品可以和商品ID为993019的商品搭配,也可以与商品ID为1375599的商品搭配,但是商品ID为993019和1375599就不能搭配。
综上,本项目的数据集包含三张数据表,三张数据表是通过商品ID进行关联的。但数据表中的商品ID并不是全部都存在于每一张数据表中的。例如:用户购买行为表里面的商品ID在商品详情表中不一定存在,商品搭配中的商品ID并不一定存在于用户购买行为中,因此要进行数据预处理。
2.3 数据预处理
数据预处理是数据挖掘中的处理数据时的一个重要步骤。为了在项目中能获取想要的数据。就应该为其提供干净,准确,简介的数据。但通常获取到的数据集的原始数据都是“脏”的,其主要表现在如下几个方面:
- 杂乱性:由于原始数据的获取渠道不同,不同渠道有着不同的标准。导致数据缺乏统一的定义和标准。导致数据不一致,无法直接使用数据。
- 重复性:数据集中的数据存在相同的描述。由于大部分的数据集中都存在着信息冗余的现象。
- 不完整性:数据集中的数据的某些属性值出现不确定或者缺失,当必要的数据出现缺失造成了数据的不完整,进而导致数据集无法使用。
在本项目中由于以上的三个数据表全部都是原始数据,在使用时可能还要获取中间数据,以方便进行数据输入。并且通过上面数据表的介绍得知,数据表的原始数据量较大,拖慢程序运行速度。因此为了达到以下的目的,要进行数据预处理。
- 清洗无用的数据:有些数据在构建模型时用不到,例如在商品详情表中没有的商品ID,却能在用户行为表中找到这个ID,但是这个ID对模型来说是没有用的。在搭配表中也没用。
- 实现数据的完整性:在数据初始阶段进行数据缺失的补全,这样可以减少程序实现阶段的数据判断,提高性能。
2.3.1数据不完整
通常使用删除或者赋予0值得方式处理不完整的数据。直接删除:适合缺失值数量较小,并且是随机出现的,删除它们对整体数据影响不大的情况。常用以下方法。
- 填充法:使用一个全局常量填充,譬如将缺省值用“NaN”等填充,但是可能还要进一步处理,算法可能会将其识别为新的类,还要判断,这个效果不是很好。
- 插补法:是对缺失数据进行补充,其中随机插补法是从总体中随机抽取某个样本代替缺失样本,多重插补是通过变量之间的关系进行预测然后进行插补[18]。
通常都是对不同的场景采取不同的策略,例如这个商品集中的特征值是一个向量的形式缺省时便将其置为0,0,0 这样保证接下来的求余弦相似时,这个结果是为0的,保证不影响其结果。
2.3.2 数据简化
为了处理多余数据要进行数据简化,由于样本数据量太大,所以要减少运算量。一般常用的处理使用类似SQL进行交集处理。在第四章的算法实现中将进行具体实现。在本项目中,先去掉缺失的商品表中的ID,保证商品表中的商品ID是一定存在于用户行为表或者搭配表中的。然后再用商品表清洗用户行为表,通过此种方法来完成多余数据的筛选。
第三章 推荐模型构建
本章用于介绍项目中用到的主要的个性化服装搭配推荐算法。包括对数据的处理、模型构建、参数设置及多个模型融合输出。主要是基于商品内容模型和基于用户购买行为模型两个部分的构建。
3.1 购物分析
人们购买商品时,一般都是考虑很久,有很多考虑的方面。尤其是要购买一些要搭配的衣服商品时,这种难度随着搭配数量上升而上升。通常都有如下几种情况来考虑如何购买商品。

图3.1 购物原因
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: