网页正文自动提取方法研究毕业论文
2020-02-19 18:16:42
摘 要
伴随着万维网的发展,在其中蕴藏的信息资源也愈加丰富。因此,网页已成为信息检索和数据挖掘技术所需要的数据资源的一个新的源头。然而,一个网页通常会包含很多部分,并且不是所有的部分都是有价值的资源。因此需要一个能确认并提取正文的方法来解决这个问题。
本文实现并比较了两种使用不同输入的网页正文提取方法的优劣。整个实验工作中,本文首先通过使用开发工具实现了这两种方法,然后将方法应用于数据集上得到提取内容,最后针对提取内容进行了评估与检测。
在实验的基础上,本文在召回和精度两方面对于两种方法的优劣进行了比较,得出了两种方法在这两个方面存在显著差异但各有优劣的结论,并就差异出现的原因进行了分析,同时对于分析结果提出了混合方法、单独优化等几个未来工作的方向。
关键词:内容提取;DOM树;HTML标签;混合方法
Abstract
With the development of the World Wide Web , resources of the WWW are becoming more and more abundant . Therefore , webpage has come to be a new source of the data resources that information searching and data mining technology need . However , a webpage is usually contained of many part and not all parts are valuable resources . For this reason , a method which can identify and extract main content is needed to solve the problem .
The thesis propose and compare two webpage main content extraction methods with different inputs . Throughout the experimental work , the thesis first implements these two methods by using development tools . Then , these methods are applied to dataset and extracted contant will be got . Finally , extracted will be evaluated and tested .
Based on the experiment , the thesis compare these two methods in recall and precision and come to comclusion that the difference between two methods is significant . The author also analyses the reason of the difference and suggest some orientations of the future work such as hybrid method and optimizing single method .
Key Words:contene extraction;DOM tree;HTML tag;hybrid method
目 录
第1章 绪论 6
1.1 研究目的及意义 6
1.2 国内外研究现状 6
1.2.1 Crunch 7
1.2.2 Document Slope Curve 7
第2章 数据处理与提取 8
2.1 数据处理 8
2.2 内容提取 9
2.2.1 DOM节点标签提取法 9
2.2.2 最大文本提取法 10
2.3 小结 11
第3章 实验及结果分析 12
3.1 实验数据集选择 12
3.2 评估指标与方法 12
3.3 统计显著性检验 13
3.3.1 T-检验 13
3.3.2 McNemar检验 14
3.4 实验设计和流程 14
3.5 评估和检验 15
3.6 结果分析 16
3.7 小结 17
第4章 结论 18
4.1 总结 18
4.2 未来的工作 18
参考文献 20
致 谢 20
绪论
研究目的及意义
从20世纪90年代初诞生之后,万维网——WWW,从最初的一个由CERN设计的用于访问多种不同的文件格式的超文本系统,成长为了一个公众可以通过web浏览器进行访问的服务。伴随着万维网的成长,在其中蕴藏的信息资源也愈加丰富。因此,网页已成为信息检索和数据挖掘技术所需要的数据资源的一个新的源头。
然而,拥有海量数据的网页通常会包含许多不同的部分,并且这些部分通常并不都是有价值的数据资源。举个例子,一个新闻网页里,除了报道的文章部分外,还包括用户评论、导航菜单、其他新闻的链接以及广告等等部分,而通常只有报道文章对于我们是有价值的。一般来说,对于人类,忽略无用的部分并将注意力集中在有用的地方是非常简单的,但是人类并不能快速处理大量的数据。而对于能够处理大量数据的软件来说,又很难快速而精确地区分一个网页中有用和无用的部分。比如说,搜索引擎常常会把一个网页的全部文本编入索引。软件不加区分的保留全部信息的结果便是无用的部分(即干扰内容)会降低搜索结果的质量和精度。
综上所述,为了解决这个问题以更好地开发网页的数据资源,就必须开发一个能够从网页中提取有用的部分(即正文)的方法。
国内外研究现状
因为网页内蕴藏的资源的丰富性和网页正文提取方法的必要性,国内外在这一方向上均有着相当多的研究。这些研究总结出了不同网页类型的之间的共同点和区别,并且面向这些共同点和区别,有针对性地开发出了针对不同特征、分别适应不同类型的多种网页正文提取方法[8][9][10][15]。例如有针对网页文档的DOM节点并利用节点内HTML标签特征进行提取的方法、有针对网页文本密度并利用行块分布规律进行提取的方法等等。
虽然在这一研究方向上已经存在相当丰富的研究和方法,但是由于HTML的快速发展和网页类型的不停增加,对于网页正文提取方法的需求依然存在。比如:由于HTML5 [7][12]的使用新增了一些标签,而其中部分标签就用于定义网页文档结构,因此针对这部分新增的标签,那些利用HTML标签特征进行提取的方法便需要进行更新,甚至于将直接吸收之前方法的思想进行重构。
以下,将介绍两种侧重点不同的网页正文提取方法。
Crunch
Crunch [2]是一个由Gupta和Kaiser等人开发的网页正文提取方法。Crunch的主提取器的输入为Web文档的DOM树,而非HTML的源代码。因此,在HTML代码输入Crunch后,将会经过因此数据处理,HTML代码被分析并构造成DOM树,最终由主提取器递归遍历DOM树节点、过滤干扰内容并提取正文。
Crunch的主提取器一般包含两层。第一层会过滤特定的HTML标签,比如样式、链接、图像等。第二层包含有广告移除器、链接列表移除器、空表格移除器和移除链接寄存器,这一层的各个移除器主要用于过滤嵌在文本标签内的干扰内容,各自使用的方法不一,如广告移除器包含一个广告服务器地址列表,用于检查DOM节点是否包含广告;链接列表移除器会计算链接字符和非链接字符之间的比例,并将该比例和移除器内预设的阈值相比较;空表格移除器则是通过查看字符数来简单地移除在其中没有实质性信息的表格元素。
通过执行以上一系列的构造、过滤和传递,Crunch最终会输出提取结果,而提取结果可以自定义为纯文本格式或转换好的HTML文档。
Document Slope Curve
Document Slope Curve [3]不同于前文提到的Crunch,是一种直接使用HTML源代码来提取正文的提取方法,由Pinto和Branstein等人开发。Document Slope Curve会分割并标记HTML源代码并统计每一段的标签数量,最终根据统计的标签分布来识别web文档中的正文。
举个例子,有一个任意的HTML文档,Document Slope Curve分割并标记这个文档,然后统计每一段的标签数量并保存在标记内,这一过程之后每一段的标签数量和标记将会形成一个对应关系。根据经验,相比于其他内容,正文往往会包含较少的标签数量,因此可以认为标签数量较少的标记位于正文内。Document Slope Curve的开发者们将小于标记内平均标签数量一半的标记标签数量认为是较少的,当然这个阈值可以根据被提取的文档实际情况来确定。
数据处理与提取
数据处理
在第一章中,我们提到了网页正文提取方法具有不同的针对性,也因此有着不同的输入,比如:HTML文档的DOM树、HTML源代码等。以HTML源代码为输入的网页正文提取方法只需要直接读取HTML源文件并将内容存入字符串即可开始提取工作,而以DOM树作为输入的网页正文提取方法则需要进行数据处理,分析HTML代码并构造DOM树,再开始提取工作。
在本次实验中,将会使用到以DOM树为输入的网页正文提取方法(即2.2.1节将会介绍的DOM节点标签提取法),所以需要对数据集的HTML代码进行数据处理。以下将介绍对HTML代码进行数据处理的过程。
本次实验的数据处理,即是分析HTML源代码并构造DOM树。
首先,我们需要了解DOM树是什么。根据W3C规范[1],DOM是有效的HTML文档和格式良好的XML文档的应用程序编程接口,它定义了文档的逻辑结构以及访问和操作文档的方法。通过使用DOM,可以构造文档并浏览文档结构,还可以执行如添加、修改、删除元素属性等操作。
如图2.1所示,在DOM中,一份Web文档的逻辑结构被表示为树结构,每一个在浏览器中呈现的HTML元素都对应着DOM树上的一个节点。
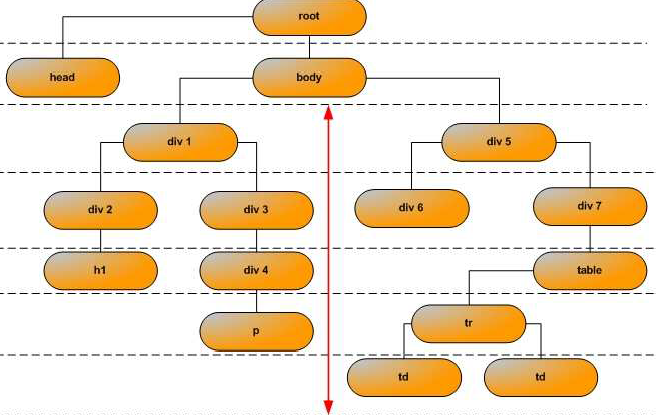
图2.1 DOM树
然后,我们将介绍分析HTML源代码并构造DOM树的工具——NekoHTML [4]。NekoHTML是由J. Andrew Clark使用Java开发的一个应用程序编程接口,它是一个简单的HTML扫描器和标签补偿器,可以让程序解析HTML文档并用标准的XML接口来访问其中的信息。
数据提取的全流程是构造HTML解析器gt;读入HTML文件gt;解析gt;获取解析后的DOM树。
内容提取
内容提取是网页正文提取方法的主体,网页正文提取方法之间的侧重点和针对性的不同往往也体现在内容提取之中。以下将介绍本次实验中实现的两种网页正文提取方法,以DOM树为输入并针对HTML标签及其属性进行提取的DOM节点标签提取法,以HTML源代码为输入并针对标签内文本字符串长度进行提取的最大文本提取法。
DOM节点标签提取法
DOM节点标签提取法是以DOM树为输入并利用HTML的标签的特征进行提取的网页正文提取方法。
在2.1节中,我们已经介绍过DOM的相关内容,本节不再赘述。下面将简要介绍HTML标签的功能及相关应用。标签,即tag [13],是HTML最基本的单位,其主要功能是定义元素属性和进行结构布局。HTML使用了数十种不同的标签来对元素进行定义以支持和展示多样的网页内容,head和body两个标签即是html文件的基础,前者定义了页面的标题、说明、脚本、样式等等内容(除标题外,其他内容均不展示在页面内,但是会通过影响网页效果来支持网页内容),而后者包含了页面显示的所有实际内容,这些内容同样都通过标签来定义,比如button标签定义按钮元素、img标签定义图像元素、table标签定义表格元素等等。标签除了本身能够定义元素属性和划分结构之外,还可以通过标签属性为元素赋予额外的信息。
因为在HTML文档中,标签定义了元素的属性,所以通过分析标签名及其属性,我们可以获取标签所定义的元素的信息。例如标签为img且标签属性为href=’1.jpg’的元素即是在网页中显示的一张存于和html文件同文件夹的使用相对路径定位的命名为1,后缀为jpg的图片。对于网页正文提取来说,正文通常是文本元素,因此我们的目标应集中于文本元素的标签,即p、br、h1…..h5等等标签。
2.1中提到,本方法在提取之前需要进行数据处理,即事先分析HTML源代码并构造DOM树。而在经由NekoHTML [4]解析并构造后的DOM树的每个节点里,都含有和节点对应的HTML文件的某个标签的所有信息,包括标签名和标签属性,因此只要我们遍历DOM树,每到达一个节点,便检查DOM节点的信息,判断其对应的元素标签是否属于正文常用的文本元素标签,如果属于,则将其提取出来暂存于一个以节点为成员的数组内,然后再继续遍历,如果不属于,则直接继续遍历工作。
在整个DOM树遍历完成之后,我们将会得到一个由以包含正文常用文本标签的节点为成员的数组,接下来只要根据正文的一些额外信息,改变选择标签属性的条件,进一步筛选节点,最后即可得到最终的输出结果,即被提取的正文。
最大文本提取法
最大文本提取法是直接以HTML源代码为输入的网页正文提取方法。
2.2.1中提到,HTML使用标签来定义元素属性以及进行结构布局。在HTML源代码中,为了方便布局和修改,不论是正文还是其他内容,往往都会使用相同的内容由同一个标签定义(存在正文被分段标签分割的可能性,这种情况会在后面讨论),不同的内容尽量使用不同的标签来定义的样式。如此一来,对于区分正文和其他内容,便有了一个很好的前提条件,由于相同内容集中且不同内容分离,所以一个标签内的所有字符都是与同一内容相关的(定义修饰该内容或是该内容本身)。
此外,标签定义元素属性以及进行结构布局这一特点反映在HTML源代码里的一大体现,便是标签通常和元素的代码字符串一同出现,从另一个角度来说,即是标签分隔了不同的元素,所以我们可以将HTML代码粗略地看成是“……标签,元素,标签,元素……”这种结构的一段字符串。这种“标签”和“元素”交错出现的结构为我们分割源代码的字符串提供了天然的锚点。只要能准确定位标签的位置,便能定位到标签对应的被标签定义的元素的位置。而利用不同标签定位的元素分别描述着不同内容,以标签为锚点“切断”,就可以得到只描述一种内容的子字符串。
要以标签为锚点,就必须获得一些标签在HTML代码里的特征。首先标签的形式是以“lt;”和“gt;”符号包围的关键词;其次大部分标签成对出现,第一个被称为开始标签,第二个被称为结束标签,结束标签会在关键词前多一个“/”符号;最后存在不成对出现的标签,标志结束标签的“/”符号在“gt;”符号前。根据以上三个特征,使用“lt;”、“gt;”以及“/”这三个符号作为锚点将会是一个很不错的选择。
根据上文的描述,将源代码的字符串以标签作为锚点分割形成描述不同内容的子字符串是可以做到的,下一步的任务便是需要在这些子字符串中找到代表正文的子字符串。而这一步很简单,因为正文往往具有最丰富的信息量,这也代表着描述正文的子字符串通常有着最大的文本量,所以理论上我们只需要提取最长的子字符串便能够提取出正文了。
最大文本提取法的流程如下:首先需要读取HTML文件,将HTML的源代码以字符串的形式读入,接下来建立一个对应锚点的一维数组并按顺序对字符串进行判断和计数,每遇到一个锚点则数组后移一位,每遇到一个非锚点则数组存储的数加一,对字符串计数完毕后,比较各锚点对应的字符串文本量的大小,并标记有着最大文本量的字符串对应的锚点,最后根据标记从原字符串内提取出对应的内容。
此外,对于上文提到的正文被标签分割的情况,本方法目前的解决方案是寻找锚点时,跳过如br、span等的用于在大量的文本内进行换行的标签,保证相同的内容尽量处于同一锚点内。
小结
在本章中,本文说明了网页正文提取方法中的两个内容,即数据处理和内容提取。数据处理部分对DOM节点标签提取法所必需的数据处理,即分析HTML源代码并构造DOM树进行了说明。内容提取部分对本次实验实现的两种网页正文提取方法,即DOM节点标签提取法和最大文本提取法的原理和流程进行了说明。
实验及结果分析
实验数据集选择
本次实验最初的实验数据集的备选来源主要有新闻、博客、论坛、微博等含有丰富信息的网页类型,在经过几次筛选后,最终选定了新闻页面作为实验数据集的来源。
第一个原因,根据平时的观察,新闻和博客这两种页面类型的数据在“正文-干扰内容”这种结构的划分中是十分相似的,都是正文(新闻文章或博客帖子)被干扰内容(广告、导航、链接等等)包围的形式,而论坛和微博则不同,这两者的正文经常会以“串(threads)”的形式出现,也即是正文的内容不只一个,并且虽然在逻辑和显示上包含在正文内的这些内容是集中的,但它们实际出现的位置有可能是分散的。所以根据第2章2.1节中对于提取方法的描述,本次实验实现的网页正文提取方法并不适合于论坛和微博这种形式的页面类型的提取,因此这两种页面类型被排除。
第二个原因,博客相较于新闻,近年来影响力持续下降,数据丰富程度也不如新闻,加上二者在“正文-干扰内容”结构上的相似性,网页正文提取方法适应新闻页面的优先程度应在博客之上。
所以,结合以上两点,新闻页面被选作实验数据集的来源。
在确定了实验数据集的来源后,我们计划从互联网上获取了数家媒体的不同页面。这些媒体包括: AGERPRES(罗马尼亚新闻社)、ANGOP(安哥拉国家通讯社)、BTA(保加利亚通讯社)、HKTDC(香港贸易发展局)、CN UNDP(联合国开发计划署-中国)、CSRS Kabul(战略和区域研究中心-喀布尔)、The Globe and Mail(环球邮报)等。
评估指标与方法
为了比较本次实验实现的网页正文提取方法间的性能差异,一个合适的评估方法和若干直观的评估指标是必需的。
在评估方法方面,有非常多的针对不同结构、不同类型和不同尺寸的评估方法[11]。比如针对DOM节点的评估方法,通过计算方法所提取出来的DOM节点数量和正文所在的DOM节点数量这二者间的各种数量和比例关系(如提取出来的正文节点、未能提取出的正文节点、提取出来的干扰节点等等),来对网页正文提取方法的性能进行评估。



