相似案件智能检索方法研究毕业论文
2020-02-19 18:16:40
摘 要
大数据时代,要从数以千万计的裁判文书中,找到真正想要的内容,并非易事。在保持精度的情况下快速检索相似法律文书,获取对应判决,是一项值得探讨的问题。
本文介绍了课题研究的背景、目的和意义。概述了系统从系统分析、系统设计、系统实现到实验测试的完整流程,并着重分析了文本相似度计算方法,并比较了两种关键词提取方式和两种文本相似度计算方法,选择了合适的文本相似度算法应用在本系统中。本系统采用B/S架构,基于Elasticsearch实现了本系统的检索功能。希望能为法律从业者提供一个高效的法律信息减速平台,同时也能使普通大众的法律检索更加简单。
关键词:法律;Elasticsearch;文本相似度计算;自然语言处理
Abstract
In the era of big data, it is not easy to find what you really want from tens of millions of refereeing documents. Quickly retrieving similar legal documents while maintaining accuracy and obtaining corresponding judgments is a question worth exploring.
This paper introduces the background, purpose and significance of the research. The complete process of system analysis, system design, system implementation and experimental test is summarized. The text similarity calculation method is analyzed emphatically, and two keyword extraction methods and two text similarity calculation methods are compared. The text similarity algorithm is applied in this system. This system adopts B/S architecture and realizes the retrieval function of this system based on Elasticsearch. It hopes to provide legal practitioners with an efficient legal information deceleration platform, and at the same time make the legal search of the general public easier.
Key Words:Law; Elasticsearch; text similarity calculation; natural language processing
目 录
第1章 绪论 1
1.1 选题背景与研究意义 1
1.2 国内外研究现状 1
1.2.1 特征提取研究现状 1
1.2.2 文本相似度计算研究现状 2
1.3 论文的基本结构 3
第2章 相关技术概述 4
2.1 Word2vec简介 4
2.2 Elasticsearch简介 5
2.3 Flask简介 5
2.4 前后端分离模式 6
2.5 本章小结 6
第3章 法律文书检索系统的设计 7
3.1 系统架构 7
3.2 性能分析 7
3.3 技术难点 8
3.4 本章小结 8
第4章 法律文书检索系统的实现 9
4.1 预处理模块 9
4.2 关键词提取模块 9
4.2.1 基于TextRank抽取关键词 9
4.2.2 基于k-means聚类抽取关键词 10
4.3 相似度计算模块 10
4.3.1 使用TF-IDF计算文本相似度 10
4.3.2 基于word2vec计算文本之间的余弦相似度 11
4.4 本章小结 11
第5章 实验结果与分析 12
5.1 数据集及预处理 12
5.2 评价标准 12
5.3 实验结果与分析 12
5.3.1关键词个数对查询结果的影响 12
5.3.2 不同相似度算法性能评估。 13
5.3 本章小结 13
第6章 总结与展望 14
参考文献 15
致谢 17
第1章 绪论
选题背景与研究意义
在互联网的“大信息库”中,法律信息资源占有重要的一席之地。裁判文书,记载着人民法院的诉讼流程和结果,是记录诉讼活动结果的媒介,也是人民法院明确和分配当事人实体权力,义务的唯一凭证。一份条理清晰,元素齐全,逻辑清楚的裁判文书,既是当事人享有权力和负担义务的保障,也是上级人民法院监督下级人民法院民事诉讼活动的重要凭证。在实际办理案件的过程中,作为诉讼律师,通过检索裁判文书,为当前办理的案件提供思路,是一个较为常规的方案。然而,案例检索是一项繁杂,系统,甚至是十分繁琐的工作,要从浩如烟海的裁判文书中,找到真正想要的内容,如海底捞针,并非易事。因此,如何在保持精度的情况下快速检索相似法律文书,获取对应判决,是一项值得探讨的问题。
文档相似度计算是裁判文书检索系统设计中的核心问题,旨在比较文档对的相似度。文档相似度计算在诸如机器翻译,信息检索,自动问答等多种自然语言处理场合,都有广泛的应用。自然语言处理任务,在通常情况下,其核心问题,都是文档相似度计算问题。例如,在裁判文书检索中,可以归结为查询项与数据库中文档的相似度。
和普通文档相比,裁判文书在整体书写格式和用词上具有一定的特殊性,对文本的预处理要求更高。传统的文档相似度计算方法,需要根据专家经验,对文字实体进行人工定义,对特征进行抽取。在此条件按下,自然不能单纯得将其他领域内任务的文档相似度计算方法引用到裁判文书相似度计算中。但是,如果借助神经网络模型的方法,从训练集中自动抽取特征,那么,就可以忽略裁判文书的特殊性吗,降低时间成本和人力成本。
通过融合传统的相似度计算策略和神经网络模型的特征提取,则可以兼顾精度和效率两个方面。因此,拟设计一个法律案例检索系统,融合以上提到的方法,希望可以在保持较高精度的情况下,也可以更快的对相似案例进行检索,从而能够减少法律从业人员的工作内容,降低普通民众检索案例的门槛,极大的提高效率,产生一定的社会价值。
国内外研究现状
1.2.1 特征提取研究现状
当前,国内外对于特征提取技术的研究不断成熟,并在自然语言处理的各个领域已经有了广泛的应用。上世纪60年代,特征提取的方面的研究逐渐出现在大众视野中,当时主要将其视为统计学领域的问题进行研究,涉及的特征通常而言较低,并且通常而言对特征之间的联系不予考虑,仅仅将特征项看作互不相关的个体看待。从20世纪90年代开始,由于机器学习的突破性进展,特征选择开始融入机器学习研究中,原有的知识理论不再适用于大数据文本的处理,性能高效的特征提取方法被很多专家学者提出
常用的特征选择算法主要包括:文档频数(DF),信息增益(IG),CHI统计(GHI)等,当下,对于特征提取算法的研究主要包括以下两种途径,一种是致力于研究出新的特征提取算法,另一种是针对现有的传统算法的改进,或算法之间相互组合应用。
新的特征提取算法。如,Liu等人对遗传算法进行了仔细研究,通过对特征提取特性的研究,根据最新的适应度函数以及交叉规则,研究出一种基于遗传的特征提取算法,并与动态获取的KNN算法结合以提高效果。Zahran等人研究了一种新的特征提取算法——基于粒子群优化的特征提取方法,在这种算法中,Zahran使用了径向函数作为分类器,经过实验,其算法在性能方面优于DF,TF-IDF。
对现有的特征选择算法进行改进和组合应用。如,Shi等人认为传统方法信息增益中对于特征频数的考虑稍有不足,据此提出了一种与词项频率相结合的信息增益算法,在此算法中,Shi等人分别从特征项的类内次数,类间分布,位置等方面对信息增益算法的参数进行修正,从而提高了分类精度。
对特征词之间联系的研究。传统的特征选择研究中,研究者主要研究的对象主要包括特征项的词频,特征词的分散度等因素,而缺乏对特征词之间联系的研究。但是,近年来,通过对特征词之间的语义,句法,语言层次,词语分布等信息进行研究,从而确定特征的方法逐渐得到主流的认可。通常情况下,在特征词项之间以及其上下文中常存在冗余,张文良等人依据这种特点,提出了通过聚类进行特征提取的算法。通过对特征词项进行聚类,之后去除掉簇类中和文本主题相关性不大的类,并再结合IG进一步提取特征。
1.2.2 文本相似度计算研究现状
信息检索是研究如何从大规模原始数据中快速准确全面的获取用户所需信息的一门学科,最初起源于图书馆的文献查找需要,现在已经扩展各种信息处理领域,成为一门跨学科,跨领域的交叉学科,对信息检索技术的研究也达到了前所未有的高潮。不好顶级学术会议都收入了不少关于信息检索的论文。
目前,相关学者也提出了一些与法律相关的信息检索技术,包括传统方法下的文档相似度计算和基于深度学习模型的文档相似度计算。
传统的文档相似度计算方法主要基于大规模文本统计和语义计算,作为统计学中的内容进行研究。相关学者在这方面由有了不少应用。Lau在其开发的法规相关分析系统中,通过向量空间模型进行法律文档信息匹配,Carnrero等人在研究从法律裁决文档中检索出论据有关的信息时,对于系统中涉及的文档相似度计算问题,采用了基于词项频频的贝叶斯统计法,也有一些学者,对于案例中的文档相似度计算问题,采用以关键特征为基础的最近邻算法。
深度学习模型主要包括基于卷积神经网络(Convolutional Neural Network, CNN)的文档相似度计算方法,基于循环神经网络(RNN, Recurrent Neural Networks)的文档相似度计算方法和基于全连接网络(fully connected neural network)的文档相似度计算方法。基于深度学习的文档相似度计算时目前主流的途径,有不少学者在此方面卓有成效。例如,Shen等提出了基于单词序列的卷积深度语义结构模型(CDSSM),Palangi等提出基于长短时记忆网络的文档相似度计算方法(LSTM),也有其他学者提出了基于多层双向长短期记忆网络(BiLSTM)的文档相似度算法。
。
论文的基本结构
本文组织结构如下:
第一章:绪论。主要介绍了本课题选题背景及研究意义,对国内外的文本相似度算法以及特征算法的研究现状和现状进行了分析总结,概述了本文的主要工作和论文结构
第二章:相关技术概述。对词向量训练框架word2vec进行了简要介绍,并重点阐述了word2vec中词向量训练模型skip-garam的基本原理。之后简要介绍了elasticsearch全文搜索引擎,之后需要将elasticsearch组建添加到web项目中,因此也简要介绍了构建web后台的框架Flask。
第三章:系统设计。主要介绍了系统设计中需要实现的功能,系统的性能要求以及技术难点,在此基础上,对除了系统的基本框架。
第四章:系统实现。主要对第三章中系统的每个模块的实现细节进行了介绍,包括预处理模块,关键词提取模块,相似度计算模块。
第五章:实验结果与分析。为了选择合适的文本相似度计算,对实验进行了设计,并对结果进行了分析,根据实验结果选择了合适的文本相似度计算方案
第六章:总结与展望。总结了本文对法律裁判文书检索系统实现的相关细节。指出研究中尚存在的一些不足以及对下一步的研究工作做了分析。
第2章 相关技术概述
Word2vec简介
传深度学习的自诞生以来,就在机器学习领域得到了广泛的关注和应用。该方法在人工神经网络的基础上,可以将底层特证抽取为高层特征,而高层特征相比于底层特征,在普通的机器学习方法中可以获得更好的效果。得益于人工神经网络的通用性,深度学习被广泛得应用在各个领域。
在此背景下,语言建模工具word2vec由谷歌开源,横空出世,在自然语言领域得到了广泛应用。Word2vec本质上由处理文本的双层神经网路构成。它的输入是一个文本语料库,输出的是该语料库中单词的特征向量。这些特向量可以被应用到其他的自然语言处理各个领域的问题中,同时,使用确定维数的特征向量,避免了词语表示出现的“维度灾难”现象。需要注意的是word2vec并不是一个深度神经网络,它的工作是将文本语料库转换为深度神经网络可以理解的数值表示方式。
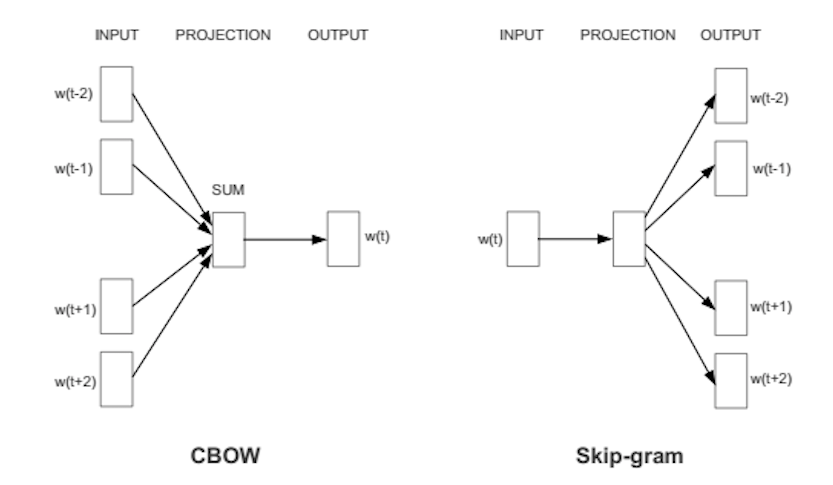
Word2vec是对神经网络概率语言模型的实现,是一个浅层双层的神经网络。Word2vec将概率模型与人工神经网络相结合,使用已汇总类似于自动编码器的方式对矢量中的每个单词进行编码。word2vec实现了CBOW(continue bag of word)模型和skip-gram结构来计算词向量,从而完成对矢量中的每个单词进行编码的任务。
在本系统中,我们使用skip-gram模型来计算词向量,因为此方法在大型数据集上训练出的结果更加精确。
Elasticsearch简介
Elasticsearch(以下简称ES)是一个基于Apache Lucene库的搜索引擎,由Shay Banon在2010年首次发布,它采用Java编写并使用Lucene构建索引,提供索引功能,ES的目标是让全文搜索变得简单。此外,ES还实现了简明的Restful接口,可以由任何应用以接口的当时进行调用,因此,相较于复杂的Lucene,ES可以轻松的实现搜索功能。更值得一提的是,ES能够轻松的通过添加节点进行大规模的横向扩展,对于PB级的结构化和非结构化海量数据的处理也不在话下。现如今,ES已经成为众多公司的搜索引擎选项,如GitHub使用ES来检索用户提交的代码,还有很多投行使用ES对股票市场走向进行分析。
本课题选择ES搜索引擎,主要是因为ES具有以下特性:
(1) 天生集群。ES默认工作模式为集群模式,每个ES服务器视为一个节点。在此模式下,所有ES节点都会被视为ES集群的一部分,而且当ES服务器启动时,会自动连接到ES集群中。
(2) 自动容错。ES通过P2P网络进行通信,这种工作方式有助于消除单点故障。节点启动后,将会自动连接到ES集群中的其他节点,在系统支持下,自动进行数据交换以及节点之间的相互监控,当一个ES节点出现故障时,将自动替换为自他ES节点。
(3) 扩展性强。通过增添新的节点,可以对系统的处理能力和数据容量进行简单的扩展。
(4) 近实时搜索。在ES和磁盘之间,设置了一层称为FileSystem Cache的系统缓存,这使得ES拥有近乎实时的搜索相应能力。
Flask简介
Flask是一个使用Python编写的,支持插入式组建的轻量级Web应用框架。其底层主要基于WSGI工具箱和Jinja2模板引擎。WSGI(Python Web Server Gateway interface)是Python应用程序或框架和Web服务器之间的一种接口,已经被广泛接受,具有很高的可执行性。Jinja2是python中一个优秀的模板语言,由于其高速,安全,可继承的特点,被各种框架广泛使用。
Flask也被称为“microframework”,即微型框架,这主要归功于其轻便,自主的设计思想,最初的源码只有仅仅一千行。基于其设计思想,Flask没有为用户内置默认使用的数据库以及其他常用的web组件。这在一定程度上,减少了用户的学习门槛,同时,通过这种方式,Flask保留了无限扩展的可能性,可以用Flask-extension加入这些功能:ORM,窗体验证工具,文件上传,各种开放式身份验证技术,以及任何用户想要添加的模块,都可以通过flask社区找到对用的源码库。
前后端分离模式
传统的开发模式是前端工作人员提供静态HTML代码,后端工作人员使用JSP等技术通多对HTML代码的修改来完成项目的开发和需求的实现。一方面前后端工作紧密耦合在一起,严重影响开发效率,另一方面是后端人员必须懂得前端代码,增加开发人员的工作难度。而前后端分离模式是指在Web应用开发过程中,将后端业务逻辑和前端美工设计完全分离,通过API的形式进行数据的交互。前端只需要调用后端提供的接口即可得到数据,完全不必再考虑后端的逻辑,而后端也不需要在懂得前端的页面,更加专注于自己业务的开发和实现,大大提升了工作的效率。
本章小结
本章主要针对法律文书检索系统所涉及到的开发技术进行了阐述。主要介绍了在相似度计算中常用的语言建模工具word2vec。之后介绍了开源的搜索引擎ES,这是系统中搜索模块的基础,一切功能在此基础上进行搭建。接着,介绍了Flask,这是一个轻量的Web应用框架,系统的后端将使用此工具搭建,通过基于Flask开发的接口,可以将ES与Flask相结合。最后,介绍了web将使用的模式,将采用前后端分离的形式,来完成整个工程。
第3章 法律文书检索系统的设计
系统架构
系统整体框架为图1所示,实现形式为web程序,后端使用flask框架,功能模块包括数据预处理模块,关键词提取模块,相似度计算模块以及搜索模块。搜索模块基于Elasticsearch开发,通过自定以的相似度计算模块来计算待检索文本与数据库中文本的相似度。对于前端输入的法律文书,在后台使用文本相似度算法计算相似度并获取topK,返回topk中对应的法律文书。获取前端输入的法律文书,通过数据预处理模块处理之后,得到词项集合,之后通过关键词提取模块,获取带检索文本对应的关键词,之后通过搜索模块与带检索文档相似的K个结果。
相似度计算模块
结果集
关键词提取模块
Elasticsearch
预处理模块
法律文书
系统处理模块
前端
前端
图1 系统整体框架
性能分析
在裁判文书检索系统中,主要包括以下检索任务:
1. 全文检索。给出一个案例描述,返回与给定的案例描述最相关的K的结果。



