基于协同过滤的推荐系统研究与设计毕业论文
2020-05-24 12:33:46
摘 要
随着信息技术的发展,网络渗透到人们学习生活的各个领域,各种文字、图片、音乐、视频等大量信息的创建与分享变得越来越容易,大数据时代也使人们进入到了一个信息过载的时代。如何让用户在信息的海洋中找到有用的信息,不被大量的无关信息淹没,成为人们关注的热点。
推荐系统是一种帮助用户从海量信息中快速发现有用信息以及潜在感兴趣信息的工具。推荐系统不需要用户提供明确的需求,它通过收集用户的历史行为并结合其它相关信息为用户的兴趣建立模型,从而找出用户可能会喜欢的物品并推荐给用户。因此,推荐系统作为一种解决信息过载的重要方法,被应用在越来越多的领域里。
基于协同过滤的推荐系统利用用户以往的偏好信息进行个性化预测,预测的内容包括一些主题、人或者单个用户可能喜欢的物品。近几年来,随着互联网上可访问信息数量的增长和活跃用户的增加,在大型数据集上进行快速准确的计算推荐变得越来越难。
本项研究主要介绍了Spark平台上音乐推荐系统的设计与实现,通过在Spark平台上并行化实现协同过滤算法来实现该推荐系统。同时与该算法在Hadoop平台上的分布式开发作对比,得出该框架上的算法可以与不断增长的用户数量呈线性比例关系。同时,我们也研究了几种经典的协同过滤算法,包括基于用户的协同过滤、基于项目的协同过滤,并对这两种算法进行了对比。
关键词:信息过载 推荐系统 协同过滤 Spark
Research and Design of Recommendation System based on
Collaborative Filtering
Abstract
With the development of information technology, network has penetrated into all areas of learning and life. It’s getting more and more easily to create and share a variety of text, pictures, music, video and other large amounts of information. The age of big data is also the age of information overload. It has become a hot topic that how to help people to find information useful in the ocean of information without being overwhelmed with large numbers of extraneous information.
The recommendation system is a tool to help users quickly find useful and potentially interesting message from the mass of information. Recommendation system does not require the user to provide a clear demand, it collects historical behavior of users and combines it with other relevant information to establish the user interest model, so as to find out the items that the user might like and recommend them to the user. As an important method to solve the information overload, the recommendation system has been applied in more and more fields naturally.
Collaborative filtering based recommendation systems use information about user preferences to make personalized predictions about content, such as topics, people, or products that an individual user might like. As the volume of accessible information and active users on the World Wide Web has grown tremendously in recent years, it becomes increasing difficult to compute recommendations quickly and accurately over a large dataset.
In this study, we mainly introduce the design and implementation of Music Recommendation System on Spark. Meanwhile, we will introduce an algorithmic framework built on top of Apache Spark for parallel computation of the collaborative filtering problem, which allows the algorithm to scale linearly with a growing number of users unlike distributed development on Hadoop.
We also investigate several different approaches to the classic user-based collaborative filtering algorithm including item-based collaborative filtering, correlation-based and vector-based similarity calculations, and regression-based techniques for prediction computation.
Key words: Information Overload; Recommendation Systems; Collaborative Filtering; Spark
目录
摘 要 I
Abstract II
第一章 绪论 1
1.1课题背景 1
1.2 推荐系统的发展历史及研究现状 1
1.2.1 基于协同过滤的推荐系统 1
1.2.2 大规模协同过滤面临的挑战 2
1.2.3 集群计算环境下的协同过滤 3
第二章 相关理论及技术简介 4
2.1 基于用户的协同过滤推荐算法 4
2.1.1 问题陈述 4
2.1.2 数学表述 4
2.1.3 顺序排列 5
2.1.4 算法特性 6
2.1.5 基于物品的协同过滤推荐算法 6
2.2 Spark 7
2.2.1 Spark概述 7
2.2.2 Spark特点 9
2.2.3 Spark生态系统 10
2.2.4 Spark程序模型 10
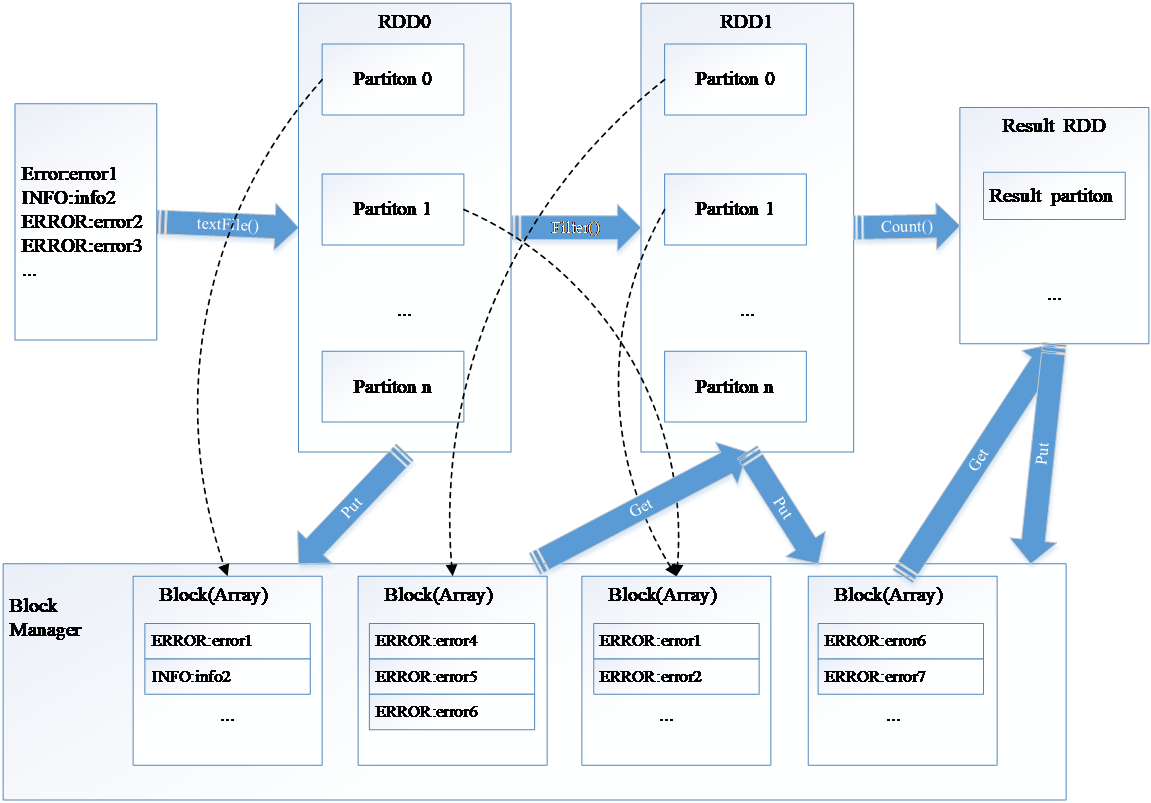
2.2.6 弹性分布式数据集(RDD) 11
2.2.6.1 RDD创建 11
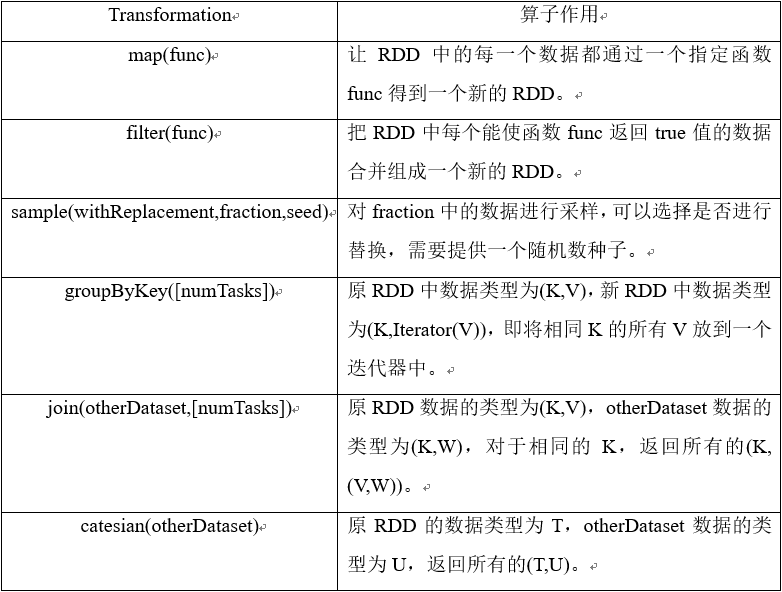
2.2.6.2 RDD转换操作 12
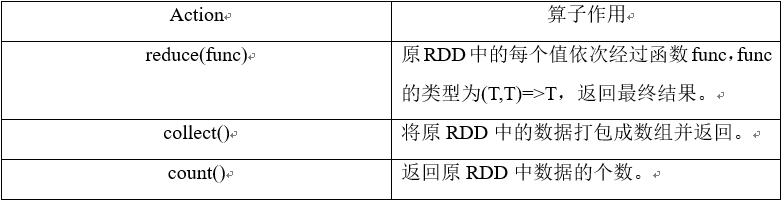
2.2.6.3 RDD动作操作 13
2.2.6.4 RDD惰性计算 13
2.2.6.5 RDD持久化 14
2.2.6.6 共享变量 14
第三章 总体设计 15
3.1 音乐推荐系统在Spark上的并行化设计与实现 15
3.1.1 基于项目的协同过滤推荐算法 15
3.1.1.1 物品近似度计算 15
3.1.1.2 top-N个推荐值计算 17
3.1.2 基于用户的协同过滤推荐算法 17
3.1.2.1 用户相似度计算 18
3.1.2.2 top-N个推荐值计算 19
3.1.3 相似度计算方法 20
第四章 系统关键技术实现 22
4.1 用户近似度的计算 22
4.2 top-N推荐值的并行化计算 23
第五章 实验及结果分析 26
5.1 实验环境 26
5.2 实验运行流程 29
5.2.1 启动Spark集群 29
5.2.2 运行程序 32
5.3 实验数据集 32
5.4 实验结果与分析 33
第六章 总结与展望 36
参考文献 37
致谢 39
第一章 绪论
1.1课题背景
信息技术经过60余年的发展,已经渗透到国家治理、经济运行、民用生活等各个角落。政治、经济活动中很大一部分的活动都与数据的创造、采集、传输和使用相关,随着网络应用日益深化,大数据应用的影响日益扩大。在这个大背景下,从公司战略到产业生态,从学术研究到生产实践,从城镇管理乃至国家治理,都将发生本质的变化。
互联网的出现和普及伴随着用户可获取的信息量的爆发式增长,这使得在信息时代下用户对信息的迫切需求得到了满足,但随之而来的是,用户在面对纷繁的巨量的信息时无从下手,不知道如何获取自己真正需要的有效信息,反而导致信息的使用效率愈发的低下,这就是所谓的信息超载问题。
相关图片展示: