手写体数字识别技术研究毕业论文
2020-04-10 16:58:25
摘 要
手写体数字识别被广泛应用于金融,税务,普查,邮政等方面,所以对准确率的要求比较高。本文设计的神经网络是以图像的灰度作为输入。
神经网络式是近年的研究热点,因为本身具有高冗余度,非线性等特点,已经变得越来越受到人们的关注。选择卷积神经网络来识别数字图像。卷积神经网络网络能够用于识别移位、缩放和其他的扭曲不变的二维或者三维图像。特征提取参数用于训练和学习可以避免人工提取。本文的卷积神经网络总共分为5层,包含一个输入层,一个输出层和三个隐藏层。
本文采取的算法是BP(Backward Propagation),在BP的基础上使用权值更新学习效率等超参数,在保证梯度下降速度的同时减少了震荡的概率。在激励函数的选择上,tanh函数均值为0的特性比sigmoid更加适合作为激励函数,这提高了训练的效率。
在正式识别图像之前,图像经过预处理以消除图像中的噪点,并将其转换为更清晰和易于绘制的点线图。包括对图像进行像素亮度、几何、滤波、复原等等操作。然后将字符分解按顺序通过神经网络。
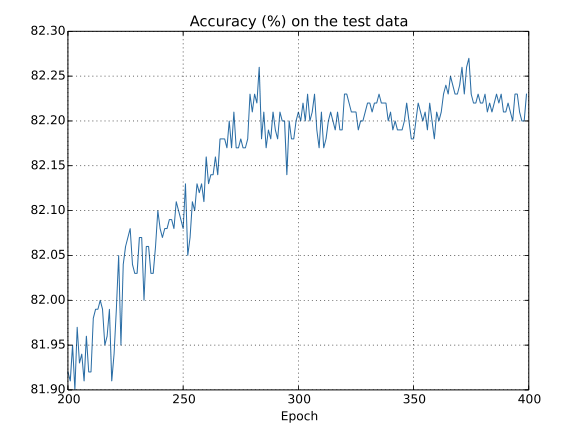
研究结果表明: 本文采取的方案对MNIST数据集的识别具有较高的准确率,从整体来说对数字图片取得了比较好的识别效果。
关键词:手写体数字;卷积神经网络;方向传播;正向传播;反向传播
Abstract
Handwritten digit recognition is widely used in finance, taxation, census, postal, etc., so the requirement for accuracy is relatively high. The neural network designed in this paper takes the gray level of the image as input.
Neural network is a research hotspot in recent years. Because of its high redundancy and nonlinearity, it has become more and more popular. Convolutional neural networks are selected to identify digital images. Convolutional neural network networks can be used to identify shift, scale, and exotic distortion-invariant 2D or 3D images. Feature extraction parameters are used for training and learning to avoid manual extraction. The convolutional neural network in this paper is divided into five layers, including one input layer, three hidden layers, and one output layer.
The algorithm adopted in this paper is BP (Backward Propagation). The use of weights to update learning efficiency and other hyperparameters on the basis of BP reduces the probability of oscillation while ensuring the speed of gradient descent. In the selection of the excitation function, the property that the tanh function has an average value of 0 is more suitable as an excitation function than the sigmoid, which improves the training efficiency.
Before the image is officially recognized, the image is pre-processed to eliminate noise in the image and convert it to a sharper and easier-to-draw dotted line graph. Including the pixel brightness, geometry, filtering, restoration and other operations on the image. The character decomposition is then passed through the neural network in order.
The research results show that: The scheme adopted in this paper has a high accuracy in the identification of MNIST datasets. Overall, digital images have achieved better recognition results.
Key Words:Handwritten digits; Convolutional neural networks; Directional propagation; Forward propagation; Directional propagation.
。
目录
第1章 绪论 - 1 -
1.1课题研究背景 - 1 -
1.2国内外研究现状 - 2 -
第2章 神经网络 - 4 -
2.1神经元与神经网络 - 4 -
2.1.1神经元 - 4 -
2.1.2激活函数 - 5 -
2.1.3神经网络 - 6 -
2.2神经网络学习方法 - 7 -
2.2.1损失函数 - 7 -
2.2.2前向传播与反向传播 - 8 -
2.2.3过拟合和梯度消失 - 9 -
第3章 优化算法与模型训练 - 11 -
3.1 优化 - 11 -
3.1.1 dropout正则化 - 11 -
3.1.2 momentum梯度下降 - 11 -
3.1.3 RMSprop算法 - 12 -
3.1.4 Adam优化算法 - 12 -
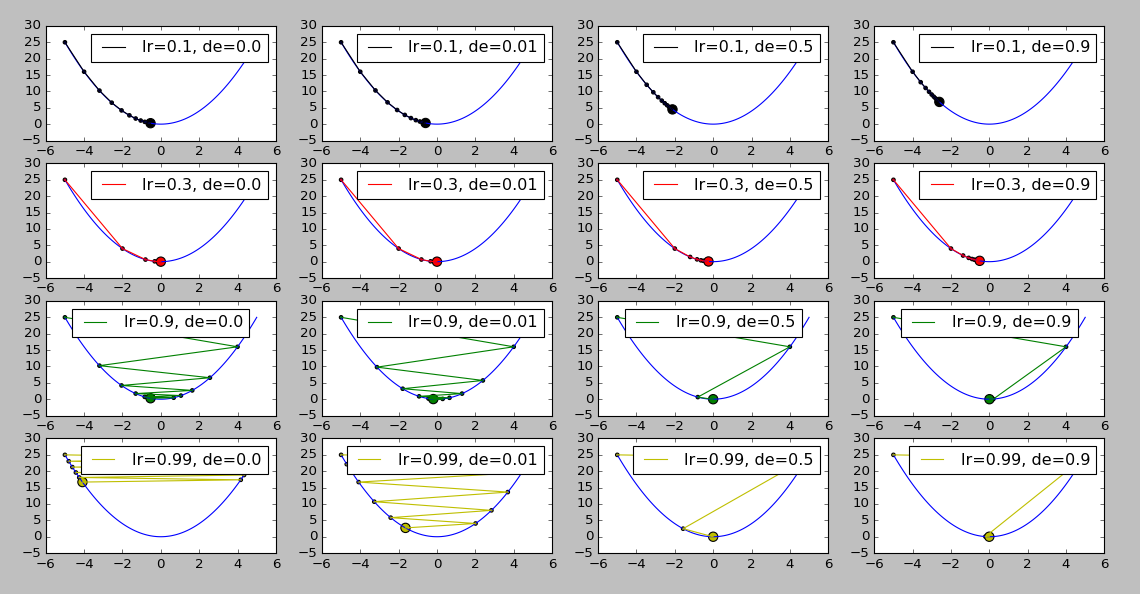
3.2 学习率衰减 - 12 -
3.3 卷积神经网络 - 13 -
3.3.1 单层卷积网络 - 13 -
3.1.2 多层神经网络 - 14 -
3.2基于全连接层的手写数字识别模型的训练 - 15 -
3.2.1 模型的搭建 - 15 -
3.2.2 模型的调参与评估 - 16 -
3.2.3实验结果总结 - 16 -
3.3 基于CNN的手写数字识别模型的训练 - 17 -
3.3.1 模型的搭建 - 17 -
3.3.2 模型的调参与评估 - 20 -
3.3.3 实验结果总结 - 23 -
3.4 检测系统的整体搭建 - 24 -
3.4.1 训练好的模型的选择 - 24 -
3.4.2 搭建输入图片的预处理系统 - 25 -
3.4.3 搭建系统的Inference网络 - 25 -
3.4.4 识别结果 - 26 -
3.4.5 样本数量对CNN的影响 - 26 -
第4章 总结 - 27 -
参考文献 - 28 -
致谢 - 29 -
第1章 绪论
本文介绍了研究背景和研究意义以及国内外的主要研究现状,主要为深度学习以及卷积神经网络对于手写体数字识别的优点,介绍了手写体数字识别中的一些主要问题,于最后概述本文的主要工作。
1.1课题研究背景
AI全称Artificial Intelligence,通常称为人工智能,这是人类今天追求的最美好的梦想之一。尽管与计算机发展初期相比,它取得了重大进展,计算机在人类以及大数据的支持下,表现十分抢眼,但是距离真正意义上的智能还是有很大的差距。仍旧没有达到图灵实验的标准。
但是2006年,深度学习异军突起,机器学习已经在AI等领域取得了突破性的进展,可以利用机器学习算法,让计算机在海量的数据中去获得训练,掌握相应的规律,之后自主识别新的样本,而这样一个历程经历了两个阶段,浅层学习与深度学习。
手写体数字识别技术通常可以分为两类——在线识别和离线识别,就字面意义而言,在线识别更容易。它使用平板将数据手动的输入计算机,这是将笔尖移动的坐标转化为电信号的方法,需要处理的有笔画数,走向,速度等。相对于联机数字识别,脱机手写体数字识别处理的对象则是一个个矩阵图像。本文讨论的主要问题也是脱机手写体数字识别。
关于阿拉伯数字,有0-9十个数字,显得十分简单,但实际上,手写体数字的识别精度仍有待提高。阻碍手写数字识别的难点有以下几点:
1.数字笔画简单,由于个体手写习惯的差异导致差别各异,个别数字在识别时容易混淆。
2.阿拉伯数字使用广泛,不同人的书写习惯,着笔,书写顺序等会有较大不同,即使同一个体对0-9的书写也会有些微不同,造成虽然只有十个数字,但是需要识别系统兼顾的各种书写方法阻碍了其准确率进一步的提高。
3.由于数字识别不像语言文字识别那样有语境的帮助,没有上下文的提示,语义没有关联,具有极大的随意性,而且数据中的每一位都是非常重要的。另外数字与金融,税务,邮政等方面有着千丝万缕的联系,其重要性不言而喻。
4.特征维数过多。
在现代社会,手写体数字识别主要有以下三个应用场合。
1.在自动邮件分拣中的应用
在邮件的自动分拣中,手写体数字识别与人工识别是相互结合的,但在一些大城市和特殊的节假日,日处理量依旧相当庞大,业务量的急剧上升也促使数字识别准确率以识别速度的改进。
2.在财务,税务等领域的应用
随着我国经济的发展,每天等待处理的各项财务,税务,支票,账单越来越多,但是涉及金融这个敏感的的领域,对数字识别精度的要求是非常苛刻的。而且财务方面需要处理的模板,表格往往不止一种,所以对算法的要求也非常高。
3.在大规模数据统计中的应用
数字统计在人口普查,年检等国家层次的数据统计中起着重要的作用,如果继续以往的手工输入,费时费力。目前各行业对书写规范的要求日趋统一,所以对算法的要求是比较低的。
手写体数字识别今后还将应用于更多的领域,也会更加普及。比如学生成绩录入。所以其研究意义也是很重要的。
1.2国内外研究现状
深度学习的早期应用是图像处理。早在1989年,加拿大教授Yann LeCuu就提出了一种常用的深度学习网络模型——卷积神经网络(CNN)。在初始阶段,CNN在小数据上取得了超乎想象的成果,但是对于大规模数据集,在接下来的很长一段时间里都没有任何大的突破。直到2012年,Hinton和他的学生采用的一个多层CNN模型在著名的ImageNet数据集上取得了当时世界最好成绩,之后图像识别技术获得极大发展,而CNN在深度学习中备受瞩目。
美国IBM公司在1960s已经开始了手写体字符领域的研究,到70年代末,脱机手写体字符研究引起了广泛的关注。
就目前来说手写体字符研究的方法主要有以下几种:
(1)模板匹配法
模板匹配是模式识别中较为常用的方法之一。是对印刷字体反馈到模板的一种方法,有些类似于活字印刷的反操作。但是由于本身的限制,这种方法不适应脱机手写。
(2)统计决策
这是模式识别中一个十分经典的方法。基于概率论与数理统计的严格数学推导,使用严苛的数学推导来识别字符使它们不受干扰。但是在提取特征和精确反应模式等方面显得有些不足。
(3)句法结构法
这是一种产生于自动机和形式语言上的,能够反映模式具体的结构特征,多用于联机手写体数字识别。但是对于抽取字符的基本单元略有不足,因此对于脱机识别不是一种适合的方法。
(4)模糊判别法
模糊判别法以模糊数学为理论基础,将模式类别分为若干子集,然后根据择近原则进行分类,该方法能够反映训练和测试样本的整体特征,并且允许样本有一定程度上的变形和干扰,但是隶属度函数并不容易建立。
(5)逻辑推理法
以AI为基础,运用知识库中的规则进行推理得到结果,这是一种待识别字符的构成规律的知识。缺点是难以得到待识别字符。
(6)神经网络法
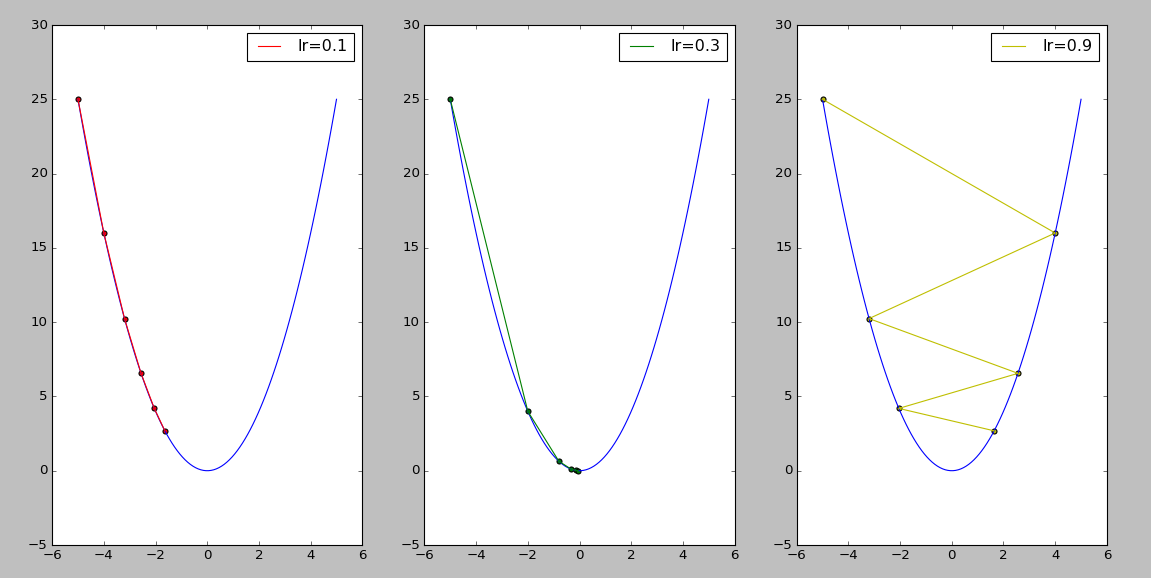
神经网络法利用神经网络学习训练的功能,通过对数据集的训练,掌握样本点特征,之后与待识别的数字进行对比,进而确定所属类别。缺点是依赖特征向量的选取,需要从不同方面选取统计特征,参数以及超参数的选择也是比较重要的,否则梯度下降太慢将导致学习效率低下,下降过快有可能引起震荡。但是从理论上来说,这是比较好的一种方法。
近年来,对于手写体数字识别研究主要集中在两个方面。一种是通过神经网络,以 CNN为佳,本文会在下面进行论述。另一种是对书写数字的特征提取,并针对特征利用不同的方法进行筛选,但是适应性不强。
第2章 神经网络
本章由神经元为引逐步展开对神经网络的论述,它涉及激励函数的选择、可能的问题和相应的解决方法。
2.1神经元与神经网络
2.1.1神经元
对神经元的研究这个课题由来已久,早在1904年,生物学家已经知道了它的结构,单个神经元通常具有多个树突和一个轴突用于接收传入信息并将信息传递给其他神经元。轴突终端连接到其他神经元的树突并传输消息。这种结构在生物学上被定义为“突触”。
图2.1简要描述了人脑中的神经元:
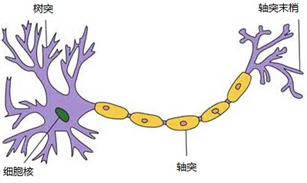
图2.1 神经元
基于这项研究,数学家Pitts和心理学家McCulloch提出了一种抽象神经元模型MP。就像传统意义上的神经元一样,神经元模型是包含输入,输出和计算功能的模型。输入数据可以与树突和输出数据与轴突进行比较。
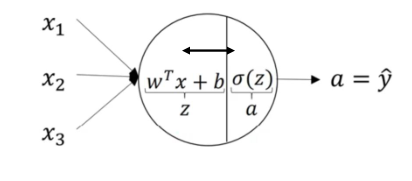
图2.2 神经元模型
图2.2是一个简单的神经元模型,它包括三个输入,一个输出以及相应的计算功能[9]。
2.1.2激活函数
当使用神经网络时,需要确定在隐藏层上使用哪个激活函数(Activation Function)及哪个激活函数应用于输出节点。以下描述了sigmoid和tanh激活函数。
激活函数应用于逻辑回归(Logistics Regression)中,输出的的线性函数作为自变量输入到sigmoid函数中,将线性函数转化为非线性函数。
下图是sigmoid函数图像,定义水平轴为z轴,那么关于z的sigmoid函数可以描述为一条平滑的从0走到1的曲线,曲线与纵轴的截距是0.5,通常用z表示。
关于sigmoid的函数公式,
其中z是一个实数。它用在前向传播中,被称为激活函数。
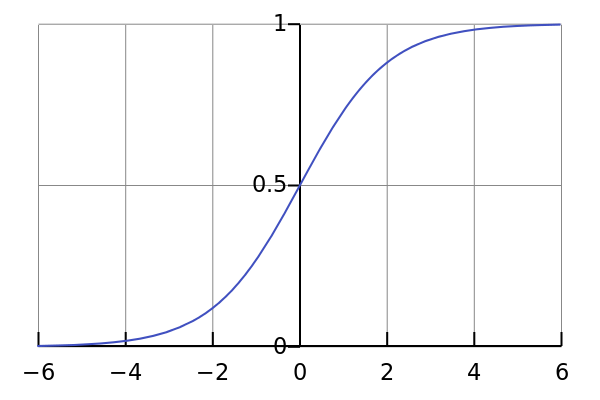
图2.3 激活函数
事实上,有时候有些激活函数更好,例如tanh函数,它在总体上都优于sigmoid函数的激活函数。
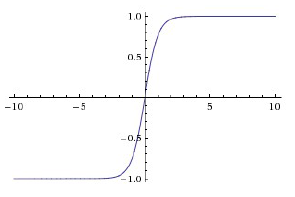
图2.4 激活函数
它是一条位于±1之间的平滑曲线。
事实上,sigmoid函数可以在平移和放缩之后获得tanh函数。
观察sigmoid和tanh函数曲线。当sigmoid函数的输入的值在[0,1]时,函数值的变化非常敏感。当输入在边界值时,间隔的灵敏度将大大降低,并且会饱和,这会影响神经网络预测的准确性;tanh函数的输入和输出保持单调的非线性上升和下降关系,这与BP网络梯度算法一致,具有更好的容错性。同时,由于tanh函数的平均值为0,所以它在许多领域优于sigmoid函数[11]。
2.1.3神经网络
在有关神经网络的参考文献中,会看到ReLu(Rectified Linear Unit)激活函数,rectify可以理解为max(0,x)。
图2.5 ReLu函数
图2.6 函数模型
图2.6中的每个小圆圈都可以成为ReLu的一部分,它是一个修正线性单元,其中x表示输入,y表示输出。这样x将表示所有的这三个输入,把下图的单个神经元叠加在一起,就得到一个稍大一些的神经网络。输入x,得到相应的y。因为隐藏层可以自己计算训练集中的样本数目以及所有的中间过程。
简单的神经网络,在逻辑回归模型中,涉及图2.7的模型。
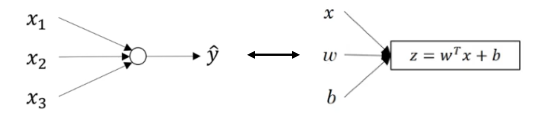
图2.7 逻辑回归模型
如上图所示,输入特征值X,以及参数W和b,通过可以得到输出z,带入σ=σ(z)就可以得到a,然后得到损失函数ℒ(?,?)
过程如图2.8所示:
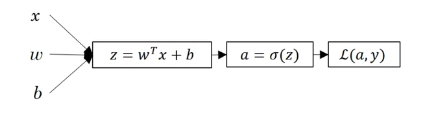
图2.8 逻辑回归模型
前面的负号表示,当训练学习算法时,算法的输出必须是最大值,或者说以最大的概率预测到这个值[12][13]。但是在逻辑回归当中,损失函数是需要最小化的,所以最小化损失函数与最大化条件概率对数可以关联起来,这就是损失函数的表达式。
2.2神经网络学习方法
2.2.1损失函数
损失函数ℒ(?,?),如果y=1,p(y|x)=;y=0,p(y|x)=1-。综合以上两个表达式,得到:
两边同时取对数log,得到:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: