基于Crowdsourcing的用户需求挖掘与分析毕业论文
2020-04-01 11:01:42
摘 要
随着互联网的快速发展,以用户为核心的软件开发理念得到了越来越多的关注,基于众包(Crowdsourcing)的需求工程模式也越来越受欢迎。然而,在众包中,用户需求的原始文本多以自然语言书写,为了便于理解众包需求,需要将众包需求的原始文本映射为不同的需求分类。与此同时,近年来神经网络在自然语言处理领域也取得了显著的研究成果,本文将采用卷积神经网络的方法对众包平台(SourceForge,https://www.sourceforge.net)上的需求文本进行多分类,主要研究工作如下:
(1)制定了用户需求类别的划分方案。在广泛查阅需求工程相关文献的基础上,以经典的需求工程中用户需求类别定义的原理和方法为指导,本文定义了7种用户需求的类别,包括:Security (SE)、Reliability (RE)、Performance (PE)、Expansibility (EP)、Usability (US)、Capability (CA)、System Interface (SI)。
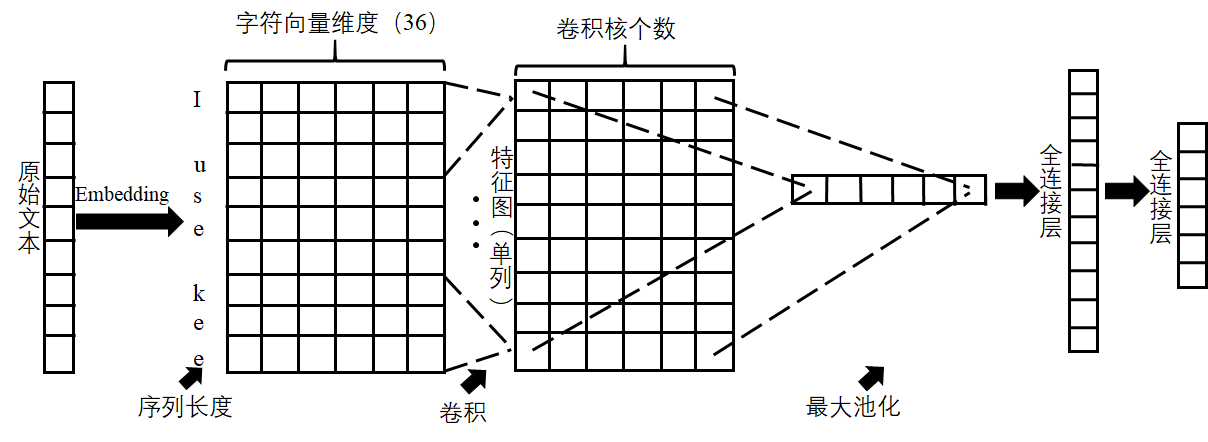
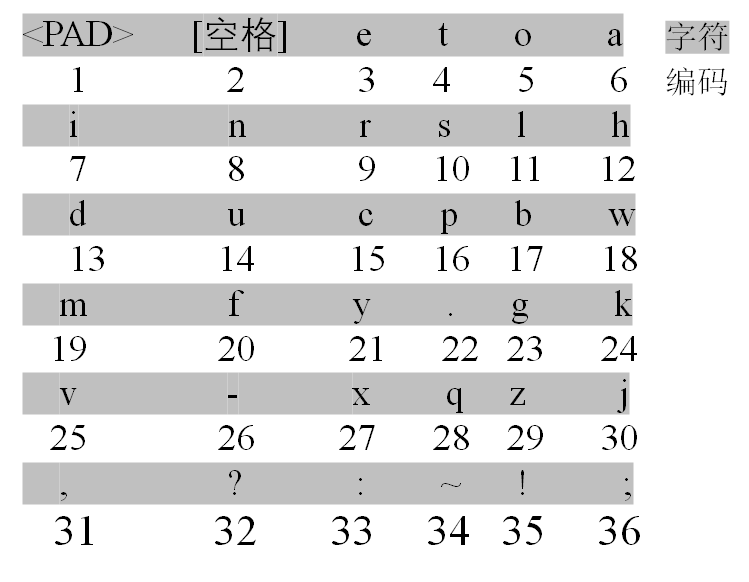
(2)提出了用户需求文本表示策略,使神经网络模型能识别用户需求文本数据。本文开展了神经网络在文本分类领域的应用研究,针对众包平台上用户需求文本的特点,提出了一种基于字符的One-Hot文本向量表示策略。所构建的字符字典由36个字符组成,以数据集中字符使用频率为序,大大提升了文本矩阵的稠密性,能够让神经网络更好地学习文本特征。
(3)设计了浅层字符级卷积神经网络结构,能够在样本数较少的情况下训练出一个较好的模型。为了设计用于用户需求分类的卷积神经网络模型,本文对传统的卷积神经网络模型进行了重构。模型的输入层和词嵌入层均由36个神经元组成,中间接单层卷积层、最大池化层,最后接两个全连接层,并在模型的输出部分用Softmax函数进行预测类别。模型使用Dropout正则化来对抗过拟合。
(4)设计了数据对比实验,实验表明去除一个样本数量过于稀少的类别,模型的召回率在33.4%到76.2%之间,精确率在59%到71.4%之间,平均综合准确率为67%,全面胜过传统的基于规则的分类方法。实验还表明字符级卷积神经网络在本文数据集上的分类性能优于词语级卷积神经网络。
本文提出的字符级卷积神经网络完全自主提取对分类有利的文本特征,不需要任何诸如规则建立与特征工程相关工作,模型泛化能力较强,这也是基于传统机器学习的方法所不具备的优点。
关键词:众包;需求工程;文本分类;卷积神经网络
Abstract
With the rapid development of the Internet, the user-centric concept of software development has been paid to more and more attention. Crowdsourcing, a new model of software requirements engineering, is becoming more and more popular. However, the original text of user requirements obtained from Crowdsourcing is written in natural language. To understand the requirements more clearly, it is necessary to divide the original text into different categories. At the same time, neural networks have achieved remarkable research results in the field of natural language processing in recent years. This thesis uses convolutional neural networks model to complete the multi-classification task of user requirements obtained from Crowdsourcing platform (SourceForge,https://www.sourceforge.net). The main content of this thesis includes the following work.
(1) This thesis adopts a strategy for user requirements classification. Guided by the classic principles and methods of the definition of user requirements categories, this thesis defines seven categories of user requirements, including Security (SE), Reliability (RE), Performance (PE), Expansibility (EP), Usability (US), Capability (CA) and System Interface (SI).
(2) To enable the neural networks model to identify the text data of user requirements, a text representation strategy is proposed. In this thesis, the application research of neural networks in the field of text classification is carried out. A character-level One-Hot text vector representation strategy is proposed for the characteristics of user requirements text on Crowdsourcing platform. The constructed character dictionary is composed of 36 characters. The order of the dictionary is determined by the frequency of characters, which greatly enhances the density of the text matrix and enables the neural networks to better learn text features.
(3) A character-level shallow convolutional neural networks model for text classification is designed to train a better model with fewer samples. In order to design a convolutional neural networks model for user requirements classification, this thesis reconstructs the traditional convolutional neural networks model. Both the input layer and the word embedding layer of the model consist of 36 neurons. The model has one convolutional layer, one max-pooling layer and two full-connected layers. The Softmax function is used to predict the categories. The Dropout regularization are also used to prevent overfitting.
(4) This thesis designs the comparative experiments. Except for a category with too few samples, the results show that the model's recall is between 33.4% and 76.2%, the precision is between 59% and 71.4% and the average overall accuracy is 67%, which is better than that of traditional rule-based classification methods. In respect of the data set used in this thesis, the character-level convolutional neural networks model performs better than word-level convolutional neural networks model.
What makes this thesis different from others is that the character-level convolutional neural networks model proposed in this thesis automatically extracts text features which are favorable for classification. That means it does not require any extra work such as rule establishment and the work of feature engineering. And the model has great generalization ability. The methods based on traditional machine learning algorithms do not have this advantage.
Key Words:Crowdsourcing;requirements engineering;text classification;convolutional neural networks
目录
摘 要 I
Abstract II
第 1 章 绪论 1
1.1 研究背景 1
1.1.1 Crowdsourcing 1
1.1.2 用户需求挖掘与分析 1
1.2 研究现状 2
1.3 本文主要工作 3
1.4 本文组织结构 3
第 2 章 神经网络在文本分类中的应用研究 4
2.1 词袋模型 4
2.2 词向量表示 5
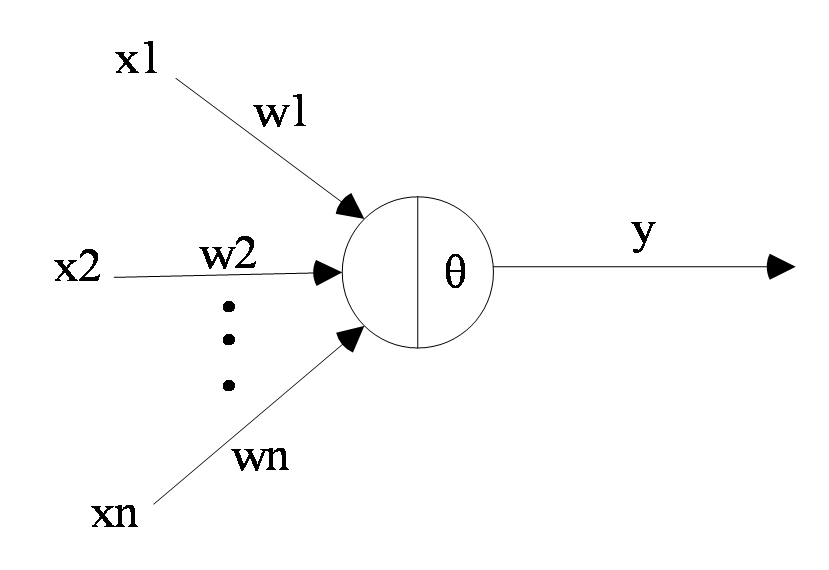
2.3 普通神经网络 6
2.4 卷积神经网络 7
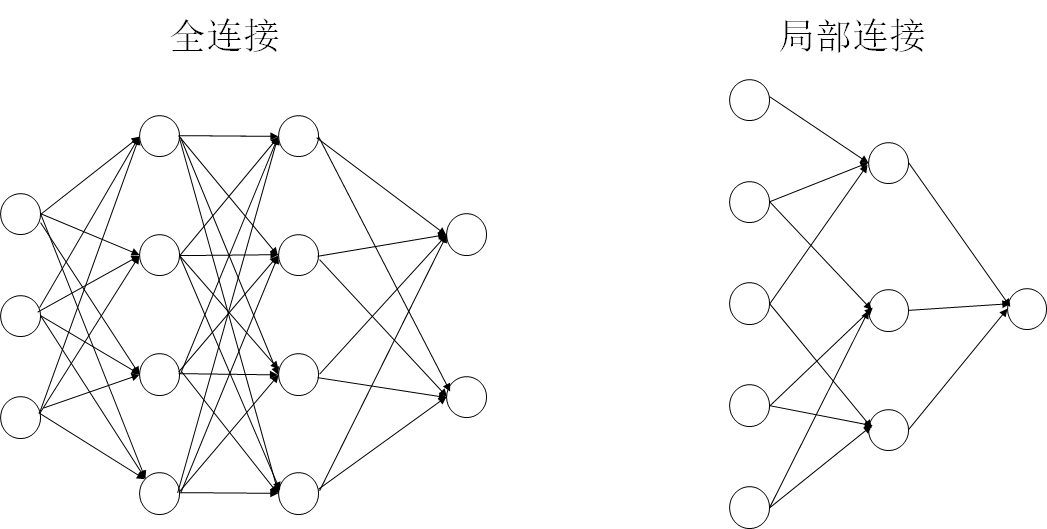
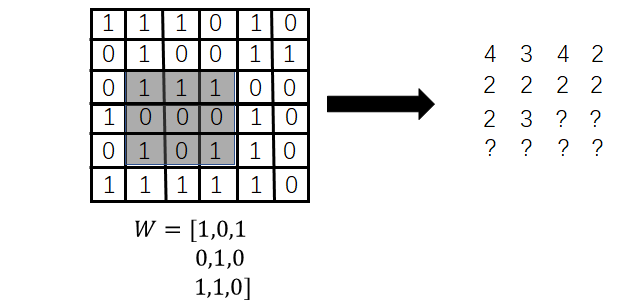
2.4.1 局部感知域 7
2.4.2 权值共享 8
2.4.3 池化 9
2.5 本章小结 9
第 3 章 用户需求类别定义 10
3.1 众包平台上的用户请求与用户需求 10
3.2 用户需求类别 10
第 4 章 基于字符的卷积神经网络的分类框架 13
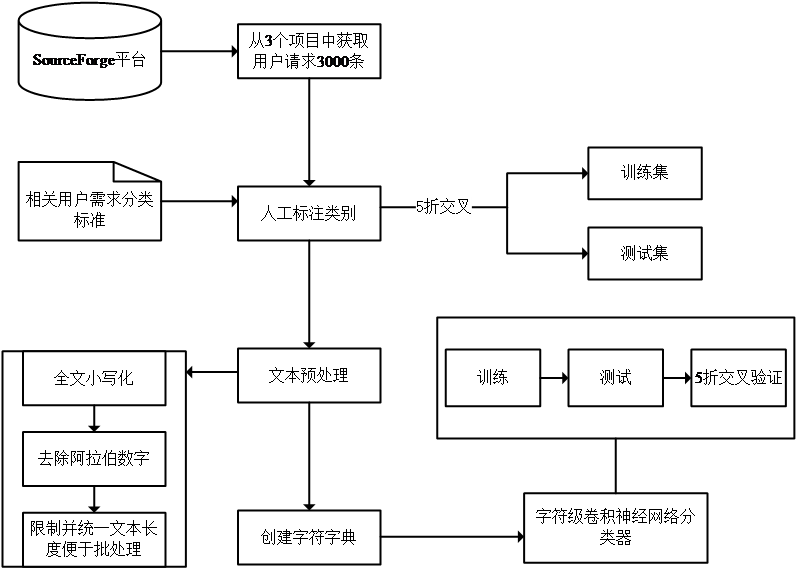
4.1 整体框架流程概述 13
4.2 文本数据预处理 14
4.3 卷积神经网络模型架构 14
4.3.1 输入层和词嵌入层 15
4.3.2 卷积层和池化层 17
4.3.3 全连接层以及输出层 18
4.4 模型训练过程 18
第 5 章 实验及分析 20
5.1 评估指标 20
5.2 实验环境 20
5.3 数据集 21
5.4 实验及结果分析 23
5.4.1 字符序列长度选择 23
5.4.2 字符级与词语级卷积神经网络 24
5.4.3 训练过程分析 25
5.4.4 模型与特定项目相关性论证 26
5.5 结果分析 29
5.6 模型测试 30
第 6 章 总结与展望 32
参考文献 34
致 谢 35
绪论
1.1 研究背景
1.1.1 Crowdsourcing
Crowdsourcing即众包,指的是一种能够有效获取资源的特定模式,具体来说是一种从广泛群体,特别是在线社区,获取所需想法、服务或内容贡献的实践。在计算机领域,借助Crowdsourcing模式,工程项目的信息来源不再单单是开发者,而是网络上的大量个人或组织,他们可以通过网络表达自己对服务的需求和想法。众包(Crowdsourcing)和外包(Outsourcing)的一个重要区别就是众包的对象并不是一个特定的群体。对于计算机软件的开发而言,这是意义重大的,因为特定群体的智慧总是有限的,总是存在意料之外的错误和考虑不周的功能,使得开发维护的周期变得冗长而繁杂,开发者在这个过程中也常常会迷失方向。Crowdsourcing解决了这个问题,只有真正深入到使用者身边的软件才能是一个健壮的、友好的、功能全面的软件。近年来,众包模式在需求工程中越来越活跃,成为了一个比较受开发者和使用者欢迎的模式。近年来,在国内外,已经涌现了一批优秀的众包平台。SourceForge(https://www.sourceforge.net)、开源中国众包平台(https://zb.oschina.net)与汇新云平台(https://www.huixinyun.com)等等都是近年来人气较高的众包平台。其中SourceForge是全球最大的开源软件开发平台和仓库之一,同时该网站采用了Crowdsourcing模式,也正因为如此,SourceForge上拥有许多优秀的开源软件,这些软件在经过了一段时间的迭代更新之后,已经完全能够替代市场上的一些商业软件。
1.1.2 用户需求挖掘与分析
在1.1.1节中提到,Crowdsourcing平台采用集思广益的想法,将真正用户的需求收集起来作为软件开发和下一次迭代更新的依据。为了区别于需求工程中“用户需求”,本文将软件产品的利益相关者或者客户提交的数据称为用户请求(如SourceForge上的用户请求,即用户上传的类似于评论的自然语言)。而用户需求是基于用户请求进行挖掘,产生对软件开发切实有指导意义的结构化数据。用户上传的以自然语言形式表达的用户请求显然是缺乏规范性的,并且涉及各个方面的用户请求很难精准传递给对应的开发者。因此需要借助一些手段来从这些自然语言中提取到有用的信息,即对用户需求进行挖掘与分析。本文主要关注对用户请求进行有效分类,采用数据挖掘基本理论对用户请求进行分析,将其划分到具体类别中,可以精准传递到不同的开发者团队,同时也提高了软件开发和迭代效率,这样那些不规范的用户请求就被转化成需求工程中对软件开发生命周期具有重大意义的用户需求。对用户请求进行分类,即预先定义一些需要用到的类别,然后通过各种各样的技术方法,将特定的用户请求划分到特定的类别中去。
1.2 研究现状
(1)众包需求挖掘现状。基于众包的研究在近年来已经层出不穷。Hosseini等人研究了项目的主要结构性特征与通过众包产生的需求质量之间的关系,他们认为众包需求启发能够提高需求启发的质量和效率,甚至经济可行性[1]。Adepetu等人引入了一个通用的需求工程众包平台CrowdREquire[2],在这个平台中对一些相关概念如目标、利益相关者、背景等都进行了很好的定义。Breaux等人做了一系列具体实验,通过将提取分析需求的任务扩展到人群中来评估众包的质量[3]。李瑞雪应用众包理念,构建了一个建筑行业众包平台,同时构建了新的适合于建筑行业众包平台的建筑行业业务模式[4]。
(2)适用技术的应用现状。基于众包平台用户请求进行挖掘与分析,从本质上来讲是采用数据挖掘的思想解决自然语言处理的问题。本文主要关注自然语言文本分类问题。近年来,一系列基于机器学习的方法在自然语言文本分类任务上取得了不错的成果,例如k-最近邻算法[5]、朴素贝叶斯算法[6]以及支持向量机算法[7],都被广泛用于文本分类。另外,一些主题模型算法如Blei提出的潜在狄利克雷分配(LDA,Latent Dirichlet Allocation)[8]也被用于自然语言处理,Galvis等人利用LDA算法从用户评论中提取出不断变化的用户需求[9]。也有一些学者开展了需求工程上的用户需求分类问题的研究,如Vlas等人提出了一种基于规则的用户请求分类方法[10],Li等人采用了基于机器学习的方法对用户请求进行分类[11]。Vlas的方法依赖于人为定义的规则,而Li的方法是基于项目特定和非项目特定的特征提取、用户启发式属性的定义,从某种意义上来说需要的人力劳动并不少,并且模型的泛化能力也不强。
近年来,随着神经网络在计算机视觉领域的崛起,它在自然语言处理领域也渐渐崭露头角,越来越多基于神经网络进行文本挖掘的方法被提出。Kim提出了一种能够用于文本分类的经典卷积神经网络(CNN,Convolutional Neural Networks)模型[12],它为后面的基于神经网络的文本分类研究打下了坚实的基础。Ahn提出了一种使用递归神经网络(RNN,Recurrent Neural Networks)语言模型和知识图谱的神经知识模型[13]。Zhang提出了一种用于理解文本的字符级卷积神经网络模型[14],Zhang提出的网络结构较深,模型参数过多,难以适用于训练集不是太大的情况。本文借鉴了Zhang所提出的的字符级卷积的思想,采用了一种字符级浅层的卷积神经网络模型用于用户请求分类,结合Dropout正则化,能在一定程度上对抗小数据集过拟合问题。
1.3 本文主要工作
针对基于Crowdsourcing的用户需求分类问题,本文提出了一种字符级的浅层卷积神经网络用于英文文本分类任务。具体来说,主要工作有以下四点:(1)制定了用户需求类别的划分方案,以经典的需求工程中用户需求类别定义为基础。能够将所有的用户请求划分到7个类别中的一种;(2)提出了用户请求表示策略,使神经网络模型能识别用户请求数据;(3)设计了浅层卷积神经网络结构,能够在数据量较少的情况下训练出一个较好的模型;(4)比较了词语级卷积神经网络和字符级卷积神经网络的性能。
本文数据来源于SourceForge平台上的三个开源项目:KeePass、Mumble与WinMerge,每个项目提取1000条用户评论数据,并进行人工标注类别。本文提出的基于神经网络的方法一方面可以很好地结合Crowdsourcing平台,对需求工程产生极大帮助,将关心不同方面的用户请求精准定位到不同的开发者团队;另一方面相较于传统的机器学习方法和基于规则的方法,本文提出的基于神经网络的方法除了人工标注训练数据以外,不需要任何的人力劳动,同时模型的泛化性能也比较好。
1.4 本文组织结构
本文组织结构如下:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: