基于神经网络的船舶油耗预测方法实现毕业论文
2020-03-26 14:49:52
摘 要
国际海事组织IMO于2016年将船舶能效管理计划纳入《1973年国际防止船舶造成污染公约》修正案,这是为了减少船舶的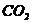 排放。而船舶在正常航行时会消耗大量燃油,从而释放大量有害气体,为了在一定程度上合理地控制住有害气体的排放,燃油的消耗就必然减少来投入未来的实际航行中。
排放。而船舶在正常航行时会消耗大量燃油,从而释放大量有害气体,为了在一定程度上合理地控制住有害气体的排放,燃油的消耗就必然减少来投入未来的实际航行中。
为了能够有效地符合船舶能效管理计划标准,就必须厘清船舶的耗油率与一些主要的外界因素的关系,并根据这些因素建立有效的船舶油耗模型。本文借助与船舶油耗相关的船舶航行的真实数据数据,如螺旋桨距、船速等,建立了多层神经网络模型,选取适合算法进行深度学习,从而对船舶油耗进行了精确度较高的预测,并且通过改变参数,如学习率、迭代次数、输入组合来对比提升船舶油耗预测模型的精确度。
研究结果表明,与船舶油耗相关度高的数据可以更高效率以及更精准地预测船舶航行时的油耗率,验证了本文实验所建立的船舶油耗模型的准确度与实用度,为将来的船舶航行减少油耗提供了初步理论解决方案,也为后续研究提供了借鉴基础。
关键词:船舶能效计划,预测模型,神经网络
Abstract
In order to reduce emission from ships, the International Maritime Organization IMO, in 2016, incorporated the Ship Energy Efficiency Management Plan into the 1973 International Convention for the Prevention of Pollution from Ships. And in the normal voyage, ships will consume a large amount of fuel, thus releasing a large number of harmful gases. In order to reasonably control the emissions of harmful gases to a certain extent , fuel consumption will inevitably be reduced to be put into the future of the actual voyage.
In order to effectively meet the standards of Ship Energy Efficiency Management Plan, the relationship between ships’ oil consumption rate and some main external factors must be clarified , based on which an effective fuel consumption model can be established. The article uses the real data of ship sailing related to the fuel consumption, such as propeller pitch, ship speed,etc. to establish multi-layers neural networks; chooses suitable algorithms for deep learning, so that to realize a relatively high accurate prediction; changes arguments, like learning rate, iteration numbers, input combination, to contrast and improve the accuracy of prediction model for fuel consumption of ships.
The research results show that data with high correlation to fuel consumption can be used more efficiently and accurately to predict the fuel consumption rate of ships when sailing. The accuracy and practicality of the model of ship fuel consumption established in this experiment are verified, which provides a preliminary theoretical solution for the future ship navigation reducing fuel consumption, and also provides a reference for the follow-up research.
Key Words:Ship Energy Efficiency Management Plan;prediction model;neural network
目录
第1章 绪论 1
1.1研究目的及意义 1
1.2神经网络国内外研究现状 1
1.3神经网络模型 2
1.4本文主要内容 2
第2章 总体设计 3
2.1预测对象特点分析 3
2.2开发平台选择 3
2.2.1 Anaconda 3
2.2.2 Python 3
2.2.3TensorFlow与keras的对比 3
2.3功能设计 4
2.4模型运行机制 4
2.5系统运行流程 5
2.6采用的神经网络预测方法 6
2.6.1神经网络预测方法的选择 6
2.6.2采用的神经网络预测方法的应用 7
第3章 系统具体实现 8
3.1预测对象关联度分析 8
3.1.1斯皮尔曼等级相关 8
3.2训练集和测试集 10
3.2.1数据的划分与组合 10
3.2.2训练集和测试集的获取 10
3.2.3训练模型和测试模型 11
3.3基于神经网络的船舶油耗预测方法实现 14
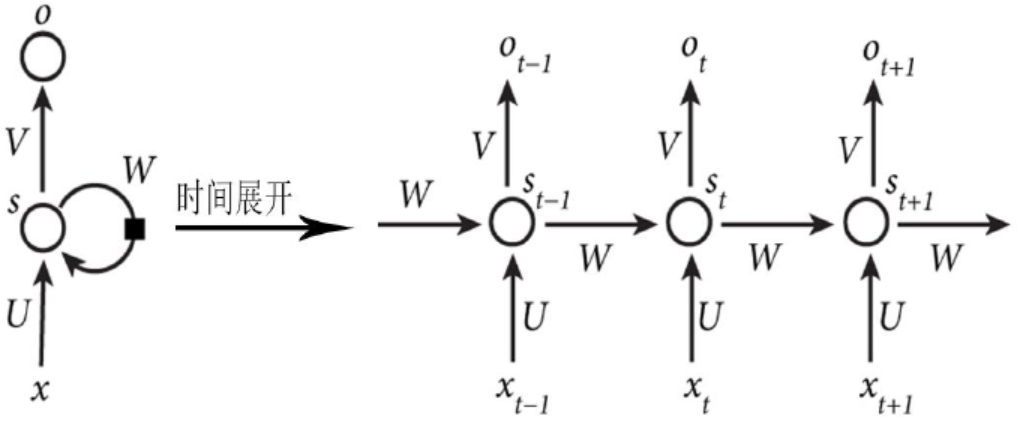
3.3.1循环神经网络(RNN) 14
3.3.2 RNN的前向传播算法和BPTT反向传播算法推导 15
3.3.3 长短时记忆网络LSTM 16
3.3.4 用LSTM模型预测船舶油耗 18
第4章 运行结果及测试 21
4.1运行结果分析 21
4.1.1训练损失和测试损失的分析 21
4.1.2 预测结果的分析 23
4.2测试 24
4.2.1采用不同的学习率测试 24
4.2.2采用不同的迭代次数测试 29
4.2.3采用不同的输入数据组合测试 32
第5章 结论与展望 36
5.1结论 36
5.2展望 37
参考文献 38
致谢 39
第1章 绪论
1.1研究目的及意义
从环境保护的层面上来说,船舶柴油机排放的废气对环境的影响十分严重。根据有关海事部门的统计,船舶排放的氮氧化物约占全球氮氧化物排放量的 7%[1],同时全球约70000条运营商船的排放量占当前总排放量的3%[2]。为了逐步控制和减少海上的等有害气体的排放总量,国际海事组织IMO在2010年将船舶能效管理计划SEEMP(Ship Energy Efficiency Management Plan)纳入《1973年国际防止船舶造成污染公约》修正案[3]。.它要求,在船舶和船队的加强减排前提下,船舶能效管理需进一步提升,并于2013年1月1日起强制实施。
从经济效益的层面上来说,船舶在正常航行时会消耗大量燃油,从而释放大量有害气体,但如果根据修正案的要求在一定程度上合理地控制了有害气体的排放,燃油的消耗就必然减少来投入未来的实际航行中。
厘清船舶的耗油率与一些主要的外界因素,如风速和风向、波高和浪向、船体吃水、纵倾角度、舵角,的关系,也即将这些外界因素作为出入量,改变它们的数值,观察耗油率的变化,建立合适的模型,实现精确的耗油预测方案,将会对环境保护和成本节约带来重要的影响。
1.2神经网络国内外研究现状
在国内,实际上早有使用神经网络进行与船舶耗油量等参数预测相关的研究。黄加亮等人利用广义回归神经网络(General Regression Neural Network, GRNN),把柴油机的各种参数如:转速、转矩等作为输入,而把船舶消耗的柴油作为预测的输出数据,使用交叉验证预测结果的准确性,试验结果表明所预测的基于GRNN算法网络对船舶柴油的消耗率的预测值与实际试验测得数据吻合较好[4];同时,叶睿等人,使用标准的神经网络,并使用多层感知机网络建立了船舶航速与油耗的静态预测模型[5],将左右舷螺距、舵角等作为输入的总共数据,再分别把总共输入的数据分组输入来预测船舶消耗的油量,得到用该模型预测的结果较为准确。
在国外,也有不少关于用神经网络预测耗油量的研究。A·Amer等人使用径向基函数神经网络(Radial Basis Function Neural Network,RBFNN),把车辆行驶的速度、车辆的重量等作为输入来预测耗油量,最终预测的耗油量与实际耗油量的误差不超过2%,证明吻合度很高[6]。
1.3神经网络模型
人工神经网络是由构成动物大脑的生物神经网络启发的计算系统。这些系统 通过考虑示例来“学习”任务。例如,在图像识别中,它们可以通过分析被手动标记为“有猫”或“无猫”的图像来识别包含猫的图像, 并使用结果来识别其他图像中的猫。人工神经网络这样做没有任何有关于猫的先验的知识,例如,猫有毛皮,尾巴,胡须和猫一样的脸。相反, 它从它所处理的学习材料中进化出自己的一套相关特征。
人工神经网络的基础是连接单元或节点的集合,称为人工神经元 (一种动物大脑中的生物神经元的简化版本)。在人工神经元之间,每个连接 (一个突触的简化版本) 可以将信号从一个传递到另一个,接收信号的人工神经元可以处理它, 然后向与它相连的人工神经元发出信号。
在常见的人工神经网络实现中,人工神经元之间的连接信号是实数,每个人工神经元的输出由其输入的总和的非线性函数来计算。神经元之间的连接称为边缘。人工神经元和边缘通常有一个权重用来调整学习进度,权重会增加或减少信号在连接中的强弱。人工神经元还可能有一个阈值,只有当聚集信号越过该阈值才会发送信号。通常,人工神经元在层上进行排列,不同的层可能在它们的输入上执行不同的信号转换。
人工神经网络的最初目标是使用与人脑的同样方式来解决问题。然而, 随着时间的推移, 人们注意力集中在完成特定的任务,以至于使人工神经网络偏离生物学。而今,人工神经网络已被用于各种任务,包括计算机视觉,语音识别,机器翻译,社会网络过滤,视频游戏和医疗诊断。
1.4本文主要内容
第一章主要从经济和环境层面阐述了建立船舶油耗模型的目的及意义,并大致概括了神经网络国内外研究的现状和人工神经网路的原理。
第二章主要简要阐明了预测对象的特点,说明了本论文的实验的开发环境,所采用的技术路线,所运用的神经网络的模型的运行机制以及最终实验会实现的功能。
第三章主要说明实验前,对数据进行的处理,训练模型和测试模型的主要流程,运用所选用的神经网络的运行模式以及它是如何应用于预测船舶油耗的。
第四章主要给出了模型预测的结果及分析,并采用了不同的方式,如改变学习率等来观察模型精度的变化。
第五章总结了本文实验的重要结论以及对未来该实验的展望。
第2章 总体设计
2.1预测对象特点分析
在船舶航行过程中,主机将消耗大量燃油,从而产生有害气体。而在现实生活中,燃油消耗跟船身阻力与推进效率有关,而这两个因素又受到螺旋桨距、船速、纵倾角度、船艏风大小、船侧风大小、吃水程度、舵角大小等多种因素的影响。如果需要建立一个预测模型,那么上述的各种影响因素就是这个预测模型的输入,消耗的燃油则为模型的输出。而建立预测模型就是要尽量用各种输入组合以及尝试不同的参数来精确地预测船舶油耗,为将来的合理控制能耗打下基础。
2.2开发平台选择
2.2.1 Anaconda
Anaconda是一种自由的和开源的Python和R编程语言的发行版本,用于数据科学和机器学习相关应用 (大规模数据处理、预测分析、科学计算)。在本实验中,选择Anaconda就是因为它已经内置了一些数据科学的包,就算没有也可以通过pip命令行进行下载,但是如果下载PyCharm,这个专门用于Python代码书写的平台,用户将要自主去下载一系列包或者是框架,显得较为麻烦。
2.2.2 Python
Python是一种为通用编程而设计的的高级编程语言, 包括面向对象、命令、功能和程序, 并具有一个大型的、全面的标准库,可以装入Tensorflow来进行神经网络模型的构建。其实C 也可以用来书写神经网络模型,但是Python中自带了各种诸如Numpy的标准库,具有广播等十分有用的功能,例如两个多维数组相加,但是它们的维数一个是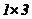 ,一个是
,一个是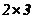 ,Python就可以把维的数组变为,再直接使它们相加,但C 却会直接报错。这就体现了Python的灵活性,也就是有利于用户更容易上手神经网络。
,Python就可以把维的数组变为,再直接使它们相加,但C 却会直接报错。这就体现了Python的灵活性,也就是有利于用户更容易上手神经网络。
2.2.3 TensorFlow与keras的对比
TensorFlow是一个开放源码的软件库, 用于跨一系列任务进行数据流编程。它可以用来进行神经网络的构建,并且由于其良好的函数封装,许多操作,如反向传播,都不需要用户自己实现,直接调用函数即可。TensorFlow是由 google大脑团队为谷歌内部使用而开发的。它是在2015年11月9日根据 Apache 2.0 开源许可证发布的。
TensorFlow的优点有:1.可扩展性强,轻松地表达许多机器学习思想和算法;2.可移植性高,因为需要在各种平台运行他们所需要运行的代码;3.再现性好,能够轻松地共享和复制研究;4.编译速度快,可以节约大量时间成本。
Keras虽然也使用python作为编程语言,后端支持TensorFlow,并且直接提供上层的框架,类似于TensorFlow,但:1.不支持seq2seq;2.编译速度较慢;3.不合适算法研究,因为算法的封装性太强。
2.3功能设计
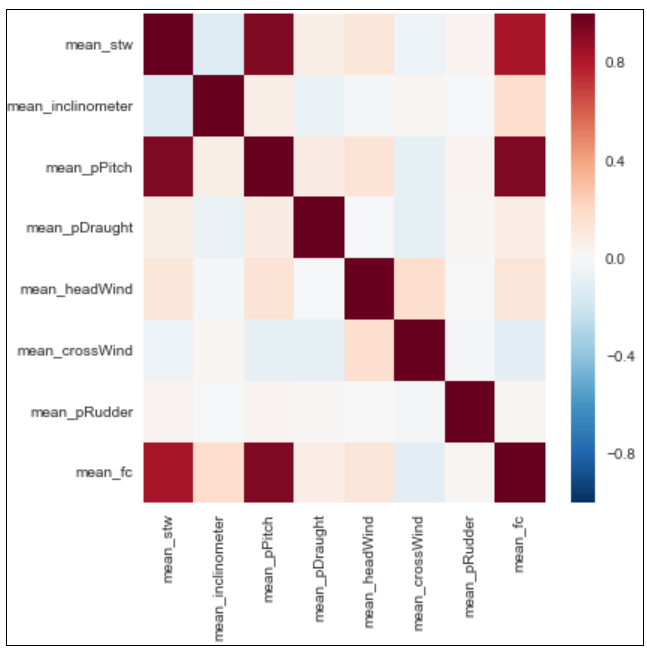
分析平均螺旋桨距(mean_pPitch),平均船速(mean_stw),平均纵倾角度(mean_inclinometer),平均船艏风大小(mean_headWind),平均船侧风大小(mean_crossWind),平均吃水程度(mean_pDraught),平均舵角大小(mean_pRudder)变量的不同组合对于船舶油耗预测的影响;改变学习率,改变迭代次数等参数,对比训练损失和测试损失的图片数据来评估模型的吻合度;显示测试数据的原始数据和预测数据的折线图,来得到训练好的模型的大致的准确率。
2.4模型运行机制
Tensorflow的运行机制可以概括为两个部分:“定义”与“运行”,而从操作层面可以抽象成两种:模型构建和模型运行。模型构建中的概念有:张量(tensor),变量(Variable),占位符(placeholder)和图中的节点操作(OP),这些内容都是在一个叫做“图”的容器中完成的,一个“图”就表示一个计算任务;而在模型运行的环节中,会话(session)中会启动“图”,并且将OP分发到如CPU或GPU等类似的设备上,将这些OP的方法执行后,系统将产生tensor并将其返回[7],如图2.1所示:
图2.1 session与图的关系
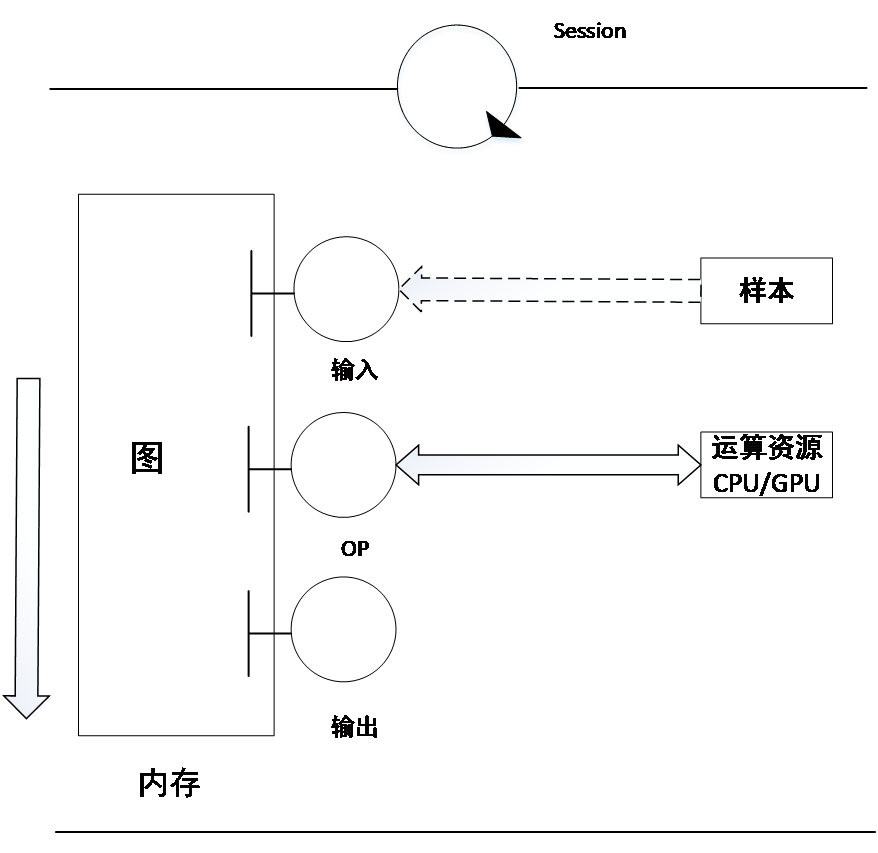
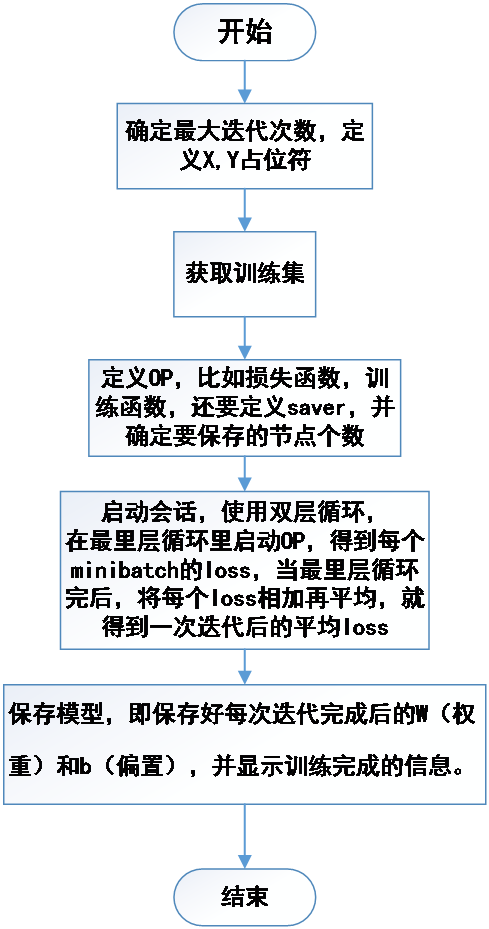
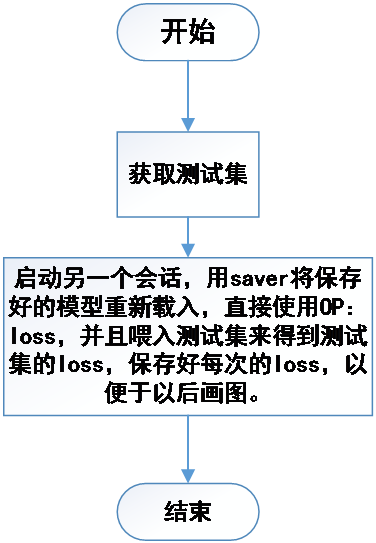
在实际环境中,这种运行情况会有三种应用场景:训练场景、测试场景、使用场景。训练场景是通过对样本的学习训练,调整学习参数,形成最终模型。其过程是将给定的样本和标签作为输入结点,通过大量的循环迭代,将图中的正向运算(从输入样本通过OP运算得到输出的方向)得到的输出值,再进行反向运算(从输出到输入方向),以更新模型中的学习参数,最终使模型产生的正向结果最大化地接近样本标签。测试场景和使用场景是利用图的正向运算得到的结果与真实值进行比较差别,实参就是输入样本,形参就是占位符,运算过程就相当于函数体,得到的结果相当于返回值。
2.5系统运行流程
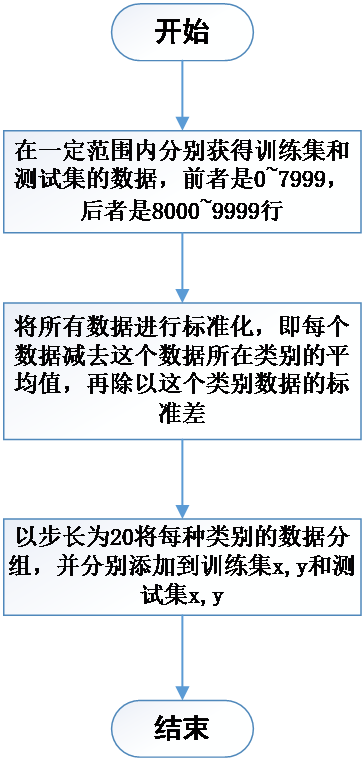
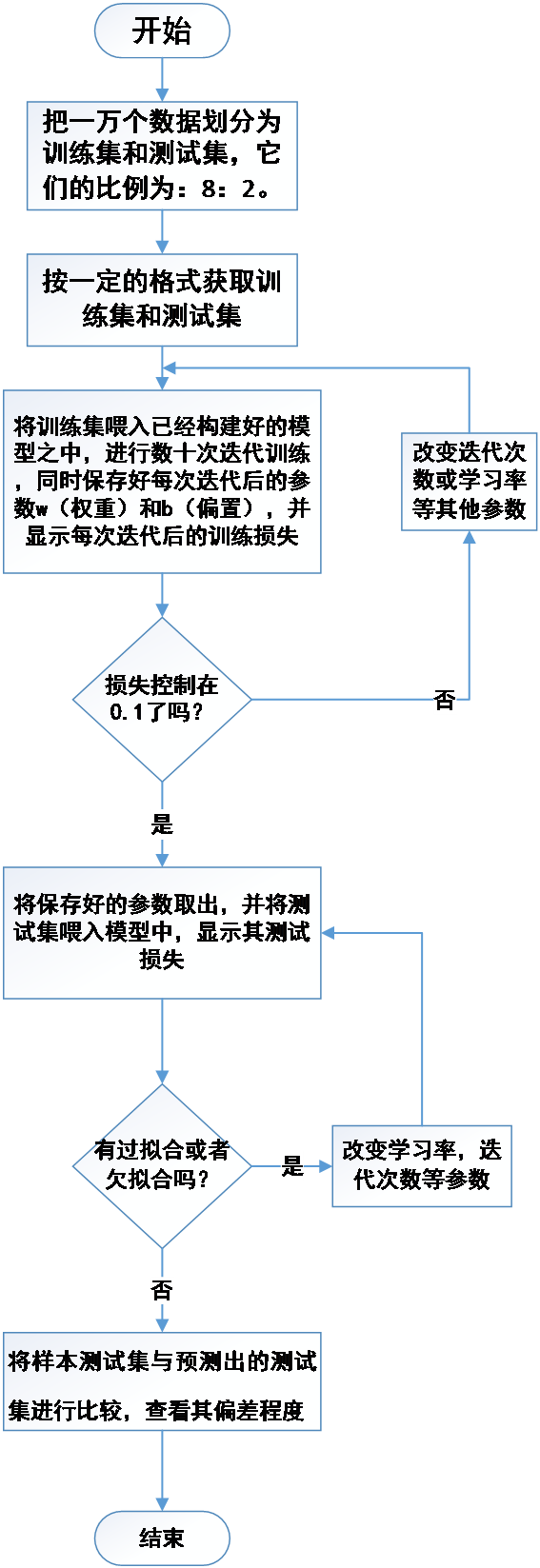
首先,把总共被提供的一万个数据划分为训练集和测试集,其中训练集占805,测试集占20%;接下来,以一定的格式分别获取训练集和测试集;然后,将训练集喂入已经构建好的模型之中,进行数十次迭代训练,同时保存好每次后的参数w(权重)和b(偏置),并显示每次迭代后的训练损失,直到把失控制在0.1以内;接着,将保存好的参数取出,并将测试集喂入模型中,显示其测试损失,确保无过拟合与欠拟合的出现;最终,将样本测试集与预测出的测试集进行对比,查看其偏差程度,如图2.2所示:
图2.2系统运行流程图
2.6采用的神经网络预测方法
常用的预测方法有:BP(Back Propagation)网络的预测方法,循环神经网络RNN(Recurrent Neural Network)预测方法,卷积神经网络CNN(Convolutional Neural Network)预测方法,在RNN神经网络基础上优化的LSTM(Long Short-Term Memory)预测方法等,而本实验将使用LSTM来进行预测。
2.6.1神经网络预测方法的选择
循环神经网络 (RNN) 是一类人工神经网络, 节点之间的连接沿序列形成有向图,这允许它展示时间序列的动态时间行为。与前馈神经网络不同, RNN 可以使用它们的内部状态来处理输入序列。这使它们适用于诸如机器翻译、连接的手写识别、语音识别等任务。LSTM是RNN的一个优秀的进化模型,它不但拥有RNN所有的优良特性,还解决了梯度反向传播时,由于逐梯度的不断缩减而可能产生的梯度消失的问题。并且,LSTM非常擅长于处理与时间序列高度相关的问题,如机器翻译、编码、解码等[8],它还更真实地模拟了人类的逻辑发展和神经组织的认知过程[9],因为它是根据此刻以及前面的数据来预测未来的数据,就类似于人类根据这一时刻的语句以及原来说过的语句来预测下一时刻的语句一样。所以本文选择LSTM神经网络作为预测选择。
2.6.2采用的神经网络预测方法的应用
对于序列化的特征的任务,都适合采用RNN网络来解决,如:情感分析、关键字提取、语音识别、机器翻译、股票分析等。
第3章 系统具体实现
系统的具体实现包含了对数据的多种处理,所选择的神经网络模型的预测原理和训练模型和测试模型的具体实现方法。
3.1预测对象关联度分析
本论文将采用多维预测的方法来对船舶油耗预测进行预测,与之相反的单维预测就是拿船舶油耗本身的前一段数据,去预测船舶油耗的后一段数据。而多维预测即输入若干个与预测目标——船舶油耗——相关的变量,建立适当的神经网络模型,实现对船舶油耗的预测。为了直观感受现有的若干种类数据,如船舶运行的平均速度,船的平均纵倾角度,船的平均螺旋桨桨距等,与船舶油耗数据的关联程度,接下来将采用斯皮尔曼等级相关和展现热图的方式对本文将用到的7个数据进行相关程度的排序。
3.1.1斯皮尔曼等级相关
斯皮尔曼等级相关系数可以用来测量两个变量的关联度的紧密程度,若数据中既没有重复值,这两个变量又完全单调相关时,斯皮尔曼相关系数为 1 或 -1,一般来说,一个变量与自身的斯皮尔曼相关系数为 1[10]。
3.1.1.1通过条形图展现斯皮尔曼等级相关系数
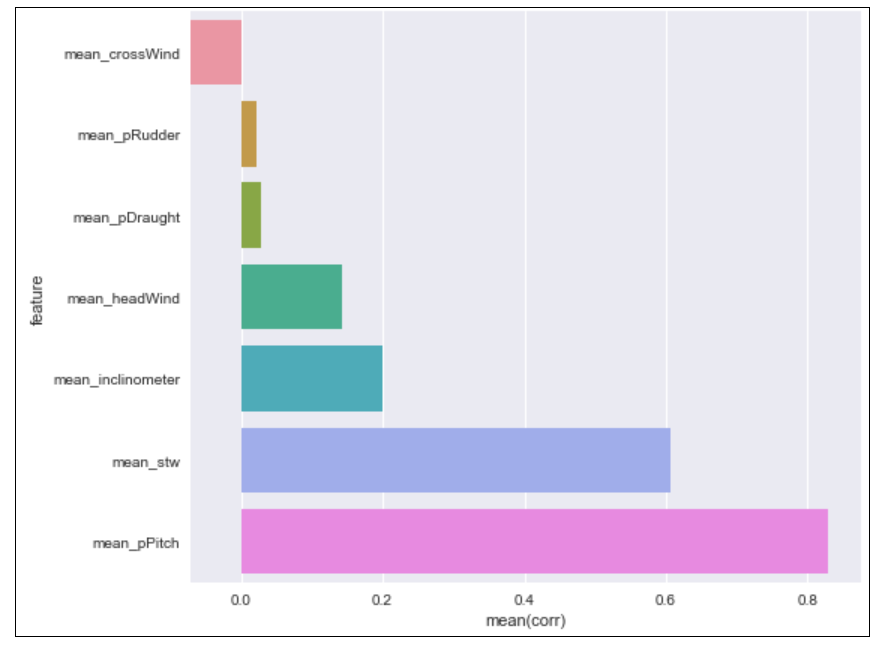 本论文读取已经写入Excel中的7种类别数据:平均船速,平均纵倾角度,平均螺旋桨距,平均吃水程度,平均船艏风,平均船侧风,平均舵角,然后分别查看他们与船的平均油耗的斯皮尔曼等级相关系数,来确定这些变量与平均船舶油耗的相关程度,如图3.1所示:
本论文读取已经写入Excel中的7种类别数据:平均船速,平均纵倾角度,平均螺旋桨距,平均吃水程度,平均船艏风,平均船侧风,平均舵角,然后分别查看他们与船的平均油耗的斯皮尔曼等级相关系数,来确定这些变量与平均船舶油耗的相关程度,如图3.1所示:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: