旅游信息检索系统设计与实现毕业论文
2020-03-24 15:22:39
摘 要
垂直搜索引擎作为一种面向主题或行业的网络信息检索工具,索引数据趋于结构化,检索范围趋于行业化,能够快速、精确地定位与查询相关的文档。本文主要围绕基于信息检索工具Lucene的垂直搜索引擎展开研究工作。使用网络爬虫Heritrix 抓取旅游网页文档,以 Lucene 信息检索框架为基础,与PageRank链接分析技术相结合,并考虑用户点击,构建了一个旅游信息的检索系统。本文的研究内容如下:
(1)分析了Heritrix爬虫的整体架构以及其工作流程,对其部分组件进行了扩展,以便在信息采集的过程中过滤掉一些不与旅游相关的网页。
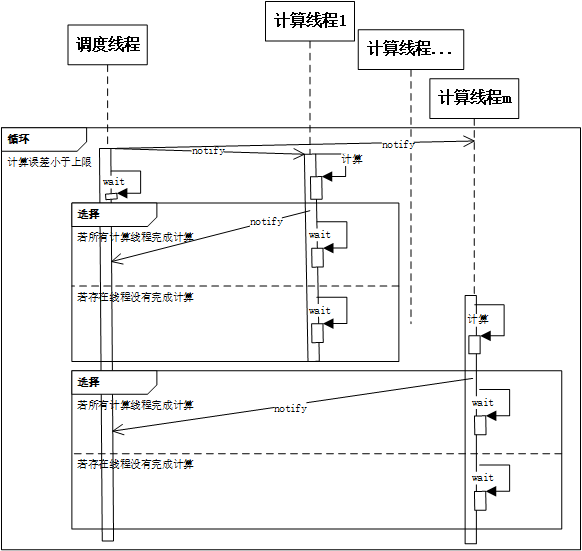
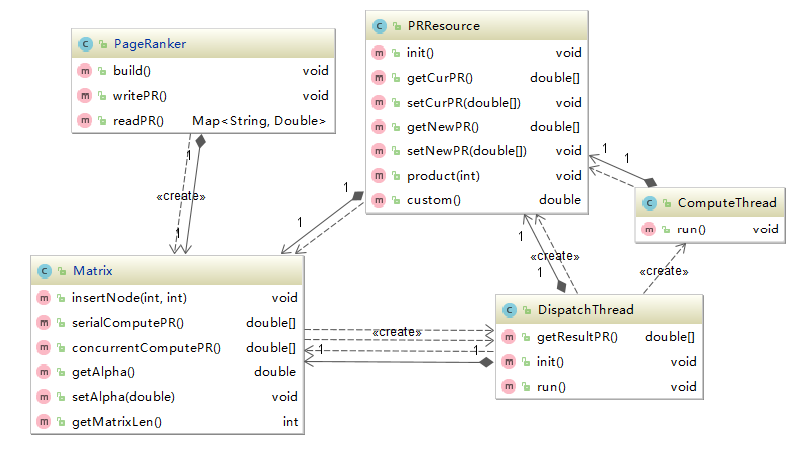
(2)研究了PageRank链接分析方法及马尔科夫链等相关理论,以多线程的方式实现了PageRank计算的幂迭代计算法。
(3)分析了一个完整检索系统的模块结构,理解了从开始查询到结果展示的整个流程,并实现了一个旅游信息检索系统的系统原型。
将PageRank链接分析方法和用户点击分析技术整合至Lucene的排序算法中后,实现了旅游信息检索系统的系统原型。系统具有清晰的架构,为后续更新和完善系统各模块提供了方便。
关键词:旅游信息;检索系统;Lucene;PageRank;
Abstract
Vertical search engine as a subject or industry oriented network information retrieval tools, index data tend to be more structured, scope of retrieval tends to be more professional., can quickly and accurately locate documents related to the query. This thesis focuses on the research work of the vertical search engine based on the information retrieval tool Lucene. Using web crawler Heritrix fetching travel web document, based on the Lucene information retrieval framework, combined with PageRank link analysis technology, and considering the user clicks, constructed a tourism information retrieval system. The research contents of this thesis are as follows:
(1) Analyzed the overall structure of the Heritrix crawler and its working process, and expanded some of its components so as to filter out some tourist-related websites during the process of information collection.
(2) Studied the link analysis method of PageRank and related theories of markov chain, and implemented the power iteration calculation method of PageRank calculation by multi-threading.
(3) Analyze the module structure of a complete retrieval system, understand the whole process from the beginning of query to the result display, and implement a system prototype of the tourism information retrieval system.
After the link analysis of PageRank and user's click-analysis technology are integrated into the sorting algorithm of Lucene, the system prototype of tourism information retrieval system is realized. The system has a clear architecture, which provides convenience for the subsequent updating and improvement of the system modules.
Key Words:Tourism Information; Retrieval System;PageRank;Lucene
目录
第一章 绪论1
1.1 研究背景及意义1
1.2 国内外研究现状1
1.3 主要研究内容2
1.4 论文组织结构2
第二章 信息采集及预处理3
2.1信息采集3
2.1.1 Heritrix爬虫工作原理3
2.1.2 Heritrix爬虫功能扩展3
2.2文档预处理5
2.2.1 文档集结构分析5
2.2.2 文档有效数据提取6
2.3 本章小结7
第三章 PageRank链接分析8
3.1 PageRank简介8
3.1.1 PageRank原理8
3.1.2 马尔科夫链8
3.2 PageRank计算9
3.2.1 数据结构设计9
3.2.2 多线程实现9
3.3 本章小结13
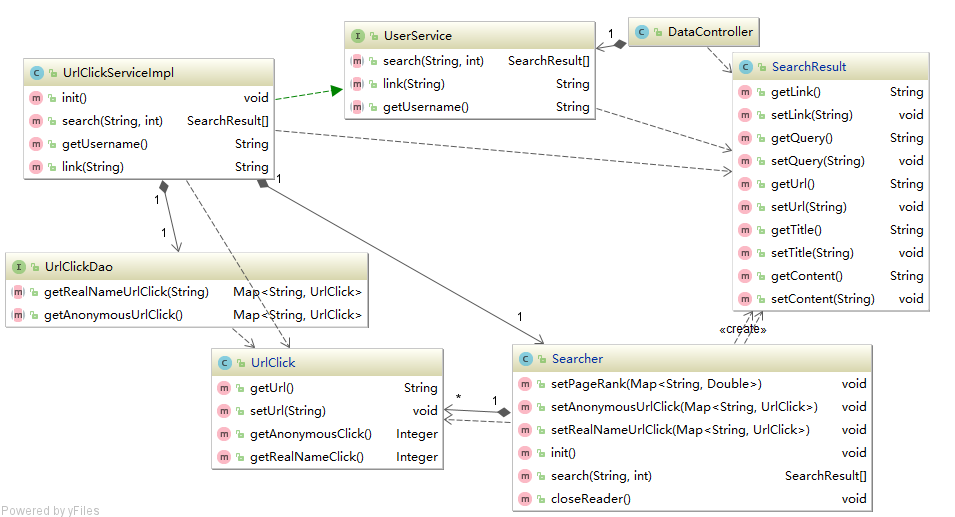
第四章 Lucene索引及检索14
4.1 Lucene简介14
4.1.1 索引过程14
4.1.2 检索过程14
4.2 索引构建模块15
4.3 信息检索模块17
4.3.1 服务端设计17
4.3.2 用户界面设计19
4.4 本章小结20
第五章 总结与展望21
参考文献22
致谢23
第1章 绪论
1.1研究背景及意义
随着生活水平的逐渐提高,旅游已成为很多人的休闲活动之一,且在当今信息技术快速发展的趋势下,用户在制定旅游计划时,一般会通过检索平台去查询相关的旅游信息。但随着网络信息内容的爆炸性增长,传统的全文搜索引擎已经无法满足用户的需求。 垂直搜索引擎是针对通用搜索引擎的信息量大、查询不准确、深度不够等问题提出来的新的搜索引擎模式,研究旅游行业的垂直搜索引擎有以下重大意义:
(1)更加专业、精确的旅游信息
面对网上海量的旅游相关信息,搜索者往往需要花费更多的时间来获取到对他们有用的信息,因为这些信息可能在搜索结果页的第10页或者更后面。而旅游行业的垂直搜索引擎能够集成网上旅游相关的信息,过滤掉与用户查询相关度较低的内容,提供更加专业、精确的服务。
(2)规范行业秩序
目前,旅游市场普遍存在着无序、不正当的竞争现象,甚至还有一些欺诈、坑害消费者的不良商家。这就需要有信息平台来监督并发布关于景区、旅行社、商家等旅游服务提供者的相关信息。网上存在很多游客对于景区、旅行社、商家等的评价信息,通过垂直搜索引擎可以将这些信息收集并提供给其他游客,从而提供旅游行业的信息利用率,利用市场竞争规范化旅游行业的行业秩序。
1.2国内外研究现状
国外对垂直搜索引擎的相关技术研究较早。文献[1]使用Lucene在大型数字化文档档案上实现了搜索功能。文献[2]采用构建单词树的方法,提出了一种基于词汇实现的词汇分割算法。文献[3]将概率模型 BM25/BM25F 整合到Lucene的检索模块中,对Lucene 的排序算法进行了针对性的改进。
国内对于垂直搜索引擎的探索还处于初级阶段。文献[4]使用Java爬虫工具Heritrix抓取Web页面作为信息源,并使用Lucene实现了一个轻量级的垂直搜索引擎。文献[5]提出了基于贝叶斯分类器实现主题爬虫的方法,介绍了基于贝叶斯分类器的主题爬虫的系统结构。文献[6]针对垂直搜索引擎反馈信息主题相关度低的问题,提出了将遗传算法与基于内容的空间向量模型相结合的搜索策略。文献[7]利用PageRank算法对原有的Lucene网页排序进行了改进,设计并实现了关于手机信息搜索的个性化搜索引擎。
综上所述,虽然国内对于垂直搜索引擎技术的研究已经有了一定的成果,但是由于中文本身的复杂性,导致国内垂直搜索引擎的搜索质量并不高。因此,国内的垂直搜索技术还有很大的发展空间。
1.3主要研究内容
本文的目标在于构造一个面向旅游信息的检索系统,用户在输入检索内容后,迅速将与检索内容相关的网页按相关度排序并返回给用户。本文的研究内容主要如下:
(1)对垂直搜索引擎的研究背景和发展现状进行基本介绍,通过分析垂直搜索引擎的基本工作原理及其架构,明确本文的研究目的与意义。
(2)分析Heritrix爬虫的整体架构以及其工作流程,对其部分组件进行了扩展,以便在信息采集的过程中过滤掉一些不与旅游相关的网页。
(3)研究了PageRank链接分析方法及马尔科夫链等相关理论,以多线程的方式实现了PageRank计算的幂迭代计算法。
(4)分析了一个完整检索系统的模块结构,实现了一个旅游信息检索系统的系统原型。
1.4论文组织结构
全文共有五个章节,分别是:
第1章绪论:主要介绍了系统的研究背景及意义、国内外研究现状及大致需要实现的功能,并介绍了本系统的主要研究内容及章节安排。
第2章信息采集及预处理:说明如何通过网络爬虫收集相关信息并提取有效内容。
第3章PageRank链接分析:讨论了PageRank算法的设计与实现,通过该算法可离线对网页集中各个网页的重要程度进行排序,这个排序结果将被整合到后续对网页相关度评分的计算过程中,改进搜索结果。
第4章Lucene索引及检索:基于全文检索框架Lcuene进行详细的系统设计及实现,同时整合PageRank链接分析以及用户点击日志分析的结果,得到旅游信息检索系统的系统原型。
第5章总结与展望:对整个论文的工作进行总结,指出不足之处和下一步的工作展望。
第2章 信息采集及预处理
2.1信息采集
本节利用开源的Java爬虫Heritrix对携程旅游网(www.ctrip.com)和中国旅游信息网(www.cthy.com)两个网站下的网页进行爬取,同时对爬取的结果网页集进行有效数据的提取,以供后续的Lucene索引模块使用。
2.1.1Heritrix爬虫工作原理
Heritrix维护一个待爬取的优先级队列,通过一个初始URL种子(Seed)集合来开始网页的爬取,当爬取至某个URL时,下载该URL对应的文档,同时提取文档中新的URL并放入优先级队列中,然后从队列中移除当前已爬取的URL,继续爬取队列中下一个URL。依次循环,直到优先级队列为空或人为终止程序。
Heritrix主要由三个部件构成[8]:总控制器(Crawl controller)、边界控制器(Frointier)、处理器链(Processor chains)。
(1)总控制器是整个爬虫的总控制者,控制整个抓取工作的起点,决定整个抓取任务的开始和结束。总控制器从边界控制器中获取URL,传递给线程池中的ToeThread线程处理。
(2)边界控制器主要确定下一个将被处理的URL,负责访问的均衡处理,避免对某一Web服务器造成太大的压力。边界控制器保存着爬虫的状态,包括发现但未处理的URL、正在处理中的URL和已经处理过的URL。
(3)处理器链由一系列部件组成,包括:预处理链(Pre-fetch processing chain),主要根据robot协议,DNS以及下载范围控制信息判断当前URL是否应当处理;抓取处理链(Fetch processing chain),主要负责从远程服务器获取数据;抽取处理链(Extractor processing chain),当提取完成时,从感兴趣的HTML文档和JavaScript脚本中抽取新的的URL;写处理链(Write/index processing chain),负责把数据写入本地磁盘;后置处理链(Post-processing chain),做和此URL相关操作的最后处理。检查哪些新提取出的URL在抓取范围内,然后把这些URL提交给边界控制器,以便进行下一轮的爬取。另外还会更新DNS缓存信息。
2.1.2Heritrix爬虫功能扩展
在爬取携程旅游网(www.ctrip.com)和中国旅游信息网(www.cthy.com)两个网站时,不能只是简单的将Heritrix爬虫的初始URL集合设置为这两个网站的首页,这样会导致有大量的无用网页被爬取下来。以携程旅游网为例,其首页如图2.1所示,可以看到首页中不仅包含了“酒店”、“旅游”等含有大量有效信息的网页链接,也包含了“客服中心”、“礼品卡”这种与本文无关的网页链接,因此在使用Heritrix爬虫爬取该网站时,必须要了解网站下各个子网页的组成结构、内容以及相互间的链接关系,并有选择地进行爬取。
图2.1 携程旅游网首页
携程旅游网首页
在了解了携程旅游网和中国旅游信息网两个网站下网页的基本结构之后,本文对Heritrix爬虫进行了如下扩展:
(1)仅爬取URL对应协议为Http协议的网页,而不爬取Https协议的网页。一是因为在访问远程服务器网站时,会涉及到用其他一些网络协议传输的报文,如DNS域名解析,而这些报文的内容显示是不需要的;二是因为有些网站会对部分网页提供两种访问方式,即Http协议与Https协议,因此我选择相对较为简单的Http协议来获取网页集,相比需要加密的Https协议来说,爬取网页的效率会高很多。
(2)仅爬取网页MIME(Multipurpose Internet Mail Extensions)类型为超文本标记语言文本(text/html )的网页,因为本次信息采集的有效数据仅为HTML网页中包含的文本内容和网页链接,所有在爬取的过程中舍弃了图片、CSS样式表、JavaScript脚本等等一些文件。
(3)不爬取在“站内搜索”获取到的部分网页,这部分网页如图2.1所示。这些网页的URL往往都是类似的,如“http://vacations.ctrip.com/whole-0B126/?searchValue=古镇amp;searchText=古镇 ”,可以看到这类URL后面都跟有查询参数,且每个查询参数的命名都一致。这类URL对应的网页都是动态生成的查询结果,且有两个特征:一是数量接近于无限(若以URL来区分网页),二是其中包含的正文内容没有太多的对本文直接有用的信息。因此可以在边界控制器中将包含“searchValue”、“searchText”的URL过滤掉。
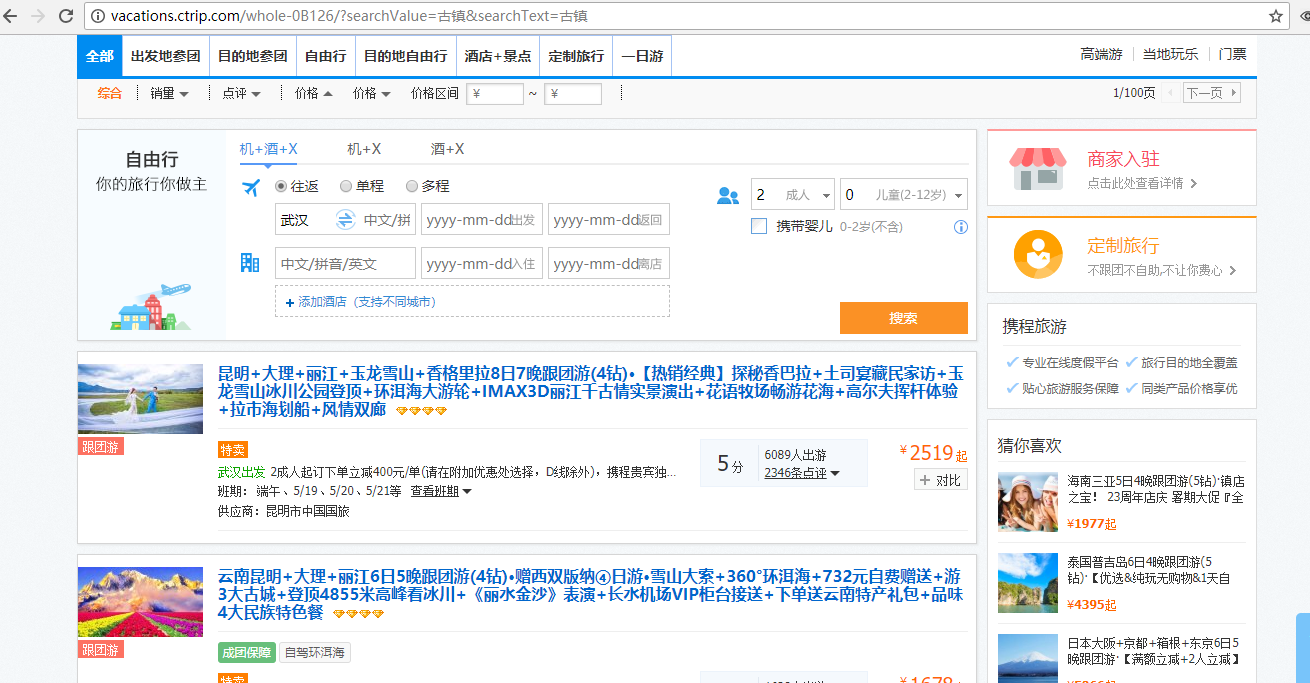
图2.2 “站内搜索”结果页面
(4)Heritrix在构建URL链接队列时,是先给予每个链接一个Key,然后将那些Key值相同的链接放在一起, 成为一个队列,爬取的过程中一条线程负责爬取一个队列中的URL[9]。在Heritrix中,为每个链接赋上Key值的默认策略是以链接的Host名称为Key值。也就是说,相同Host名称的所有URL都会被置放于同一个队列中间。当仅对某个单独网站的网页进行抓取时,会造成有一个队列的长度非常长,而其它队列几乎都处于空闲的情况,这使得在多线程抓取的情况下,效率得不到提高。因此对该策略进行扩展,以链接的整个URL为Key值,这样不同的URL就可能被放在不同的队列中,网站的爬取也由单线程变为多线程,极大的提高了爬取的效率。
2.2文档预处理
本节分析Heritrix爬虫爬取的文件集,结合Heritrix日志对这些文件集进行预处理,以便后续进行PageRank链接分析以及Lucene索引构建。
2.2.1文档集结构分析
Heritrix爬虫中写处理链负责将网页文档写入磁盘中,本次爬取采用的写处理器为Heritrix提供的MirrorWriterProcessor组件。顾名思义,该组件将URL对应的文档以镜像方式写入磁盘中。例如URL为“http://vacations.ctrip.com/tours/d-shennongjia-147/grouptravel”的网页文档,其在文件夹中的相对路径为“/vacations.ctrip.com/tours/d-shennongjia-147/grouptravel”,与URL中的各级路径一一对应。同时对于每个文档的爬取Heritrix都会记录相应的日志,日志每一行对应一次网页文档的爬取,样例日志行如图2.2所示,其每一行的各个列以空格分隔,结构如下:
(1)第1列,写入该行日志的时间 。
(2)第2列,抓取状态码,这个标识码记录了在抓取网页文档时Http header的返回状态。例如404-Not Found,、200-OK等。
(3)第3列,下载的网页文档的大小 。
(4)第4列,下载的网页文档的URL。
(5)第5列,一个标志字符串,记录到达当前页面的途径。该标志字符串有很多,但对本课题有用的只有“L”,代表Link,即该网页文档被第6列URL对应的网页所链接。
(6)第6列,直接链接到当前网页文档URL的URL。
(7)第7列,文档类型 。
(8)第8列,下载当前文档的线程ID 。
(9)第9列,时间戳 。
(10)第10列,网页内容的SHA1摘要。
图2.2 样例日志行
样例日志行
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: