网络舆情分析算法研究与实现毕业论文
2020-07-02 22:38:18
摘 要
舆情是指在一定的时间和范围内,社会民众对社会出现的特定事件包括事件的发生、发展和变化过程所表现的社会政治态度、个人世界观价值观和个人想法的集合。
今天,互联网规模以难以想象的速度在急剧的膨胀,互联网中存在的数据也以惊人的速度在急速增长,互联网成为了用于各种数据存储的在线存储库。在这之中,积极的网络舆情或消极的网络舆情话题或者中立的舆情话题在互联网网民之间相互传播,所以网络舆情对社会发展产生极大的影响。作为数据分析的研究者有必要利用数据挖掘方面的知识和数据统计方面的知识,对网络舆情进行分析和处理。文章在对网络舆情进行分析时,考虑了实现网络舆情分析的手段,明确提出该论文的研究背景及意义,国内和国外现阶段的研究现状,网络舆情分析的研究目标等相关内容,介绍了工业界广泛使用且不断完善的Apache Hadoop软件框架,网络舆情所需的数据源的获取方法,在网络舆情分析中文本聚类算法以及舆情分析的具体实现方法。论文主要分为数据的获取,数据的预处理,数据的聚类,舆情的分析,结果呈现,实现了网络舆情分析所要求的各个步骤。第一部分,数据的获取部分即根据社交平台或网站的特点通过编写网络爬虫来正则匹配特定字段;数据的预处理就是对数据进行空值处理或奇异值处理,使数据符合要求;数据的聚类就是使用python科学数据库的包实现数据的聚类;舆情的分析是采用Python 的SNOWNLP包进行包括中文分词处理,情感分析,关键字提取等相关处理来实现了用户教育状况的分析、用户网络评语情感的分析、用户地理分布分析,显示用户影响力分析舆情指标;在结果呈现模块,利用python图形用户界面显示网络舆情分析之后的结果。本文通过对网络舆情分析的结果进行图形化展示显示网络舆情分析的结果,结果的正确度依靠算法的准确度。最后本论文考虑了舆情分析时的不足,对未来的研究工作做了规划。
关键词: 舆情分析 爬虫 ubuntu Hadoop
Research and Implementations of Network Public Opinion Analysis Algorithm
Abstract
Lyric refers to the collection of social and political attitudes, individual worldview values, and personal thoughts that are manifested by certain social and public events that occur during the course of a given period of time, including the occurrence, development, and change of events.
Today, the scale of the Internet is expanding at an unimaginable rate. The data that exists on the Internet is also growing at an alarming rate. The Internet has become an online repository for various data storage. Among these, active Internet public opinion or negative Internet public opinion topics or neutral public opinion topics are spread among Internet users. Therefore, Internet public opinion has a great influence on social development. As a data analysis researcher, it is necessary to use data mining knowledge and data statistics knowledge to analyze and process the Internet public opinion. In the analysis of the Internet public opinion, the article considers the means to achieve the analysis of the Internet public opinion, clearly puts forward the research background and significance of the paper, the current research status at home and abroad, the research objectives of the Internet public opinion analysis and other relevant contents, and introduces the industry The widely used and continuously improved Apache Hadoop software framework, the method for obtaining the data source required by the Internet public opinion, the text clustering algorithm in the public opinion analysis of the network, and the concrete implementation method of the public opinion analysis. The paper is mainly divided into data acquisition, data preprocessing, data clustering, public opinion analysis, results presentation, and the various steps required for network public opinion analysis. In the first part, the data acquisition part is based on the characteristics of the social platform or website by writing a web crawler to match a specific field; the data preprocessing is to perform null value processing or singular value processing on the data, so that the data meets the requirements; data clustering The use of Python scientific database package to achieve data clustering; public opinion analysis is to use Python's SNOWNLP package to include the Chinese word segmentation, sentiment analysis, keyword extraction and other related processes to achieve the user education status analysis, user network comment emotion The analysis, user geographical distribution analysis, display the user influence analysis public opinion index; in the result presentation module, the result of the network public opinion analysis using the python graphical user interface is displayed. This paper graphically displays the results of the online public opinion analysis of the results of the online public opinion analysis. The accuracy of the results depends on the accuracy of the algorithm. Finally, this paper considers the shortcomings of public opinion analysis and plans for future research.
Keywords: lyrical analysis; reptile; ubuntu; Hadoop
目录
摘要 I
Abstract II
第一章 绪论 1
1.1研究背景及意义 1
1.2国内外舆情理论研究现状 2
1.3研究内容 3
1.4本文组织结构 4
第二章 基于爬虫的数据获取 5
2.1 社交平台数据获取 5
2.1.1数据的来源 5
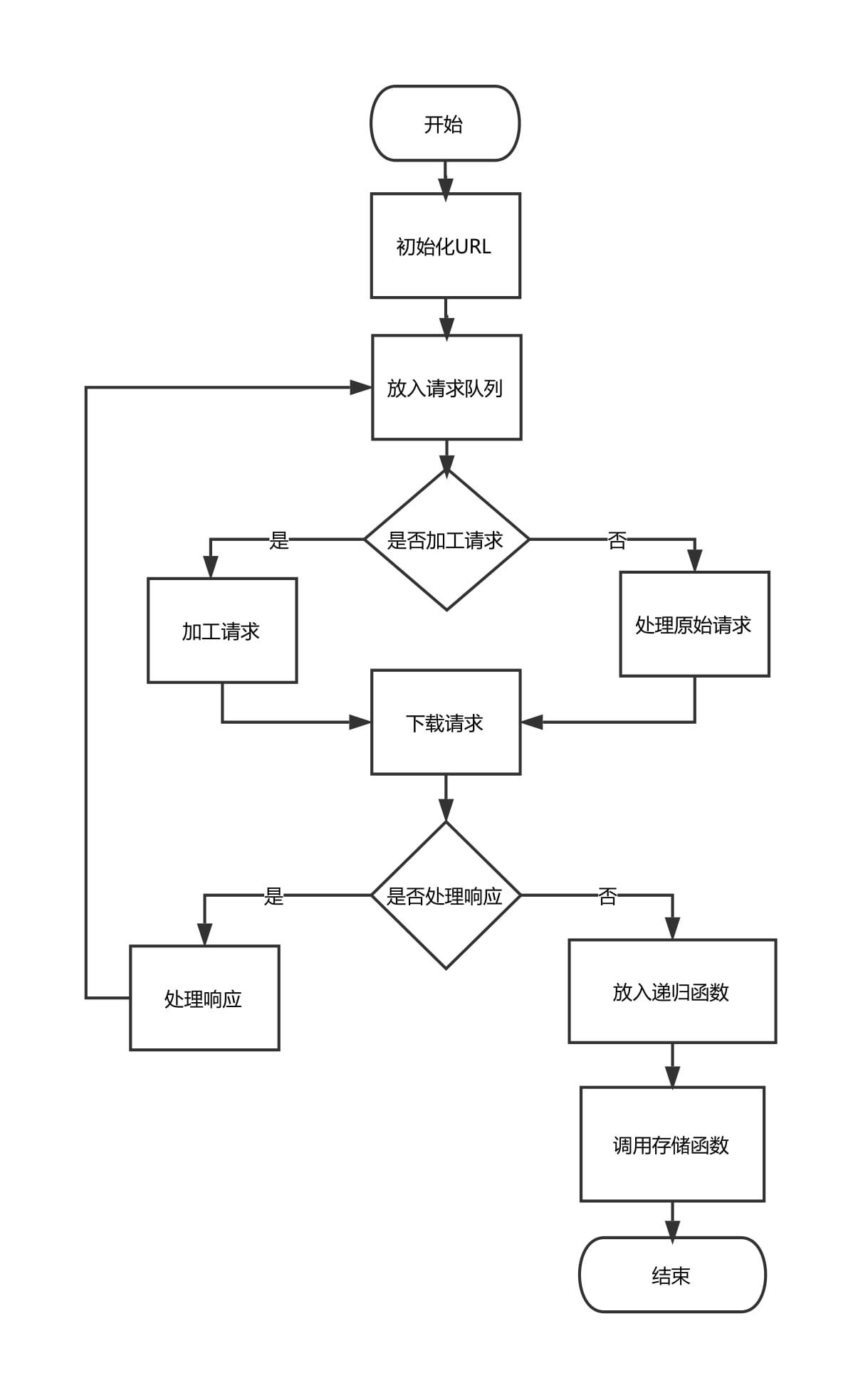
2.1.2网络爬虫 5
2.1.3获取数据爬虫算法 8
2.2MongoDB数据存储 9
2.2.1 NoSQL 9
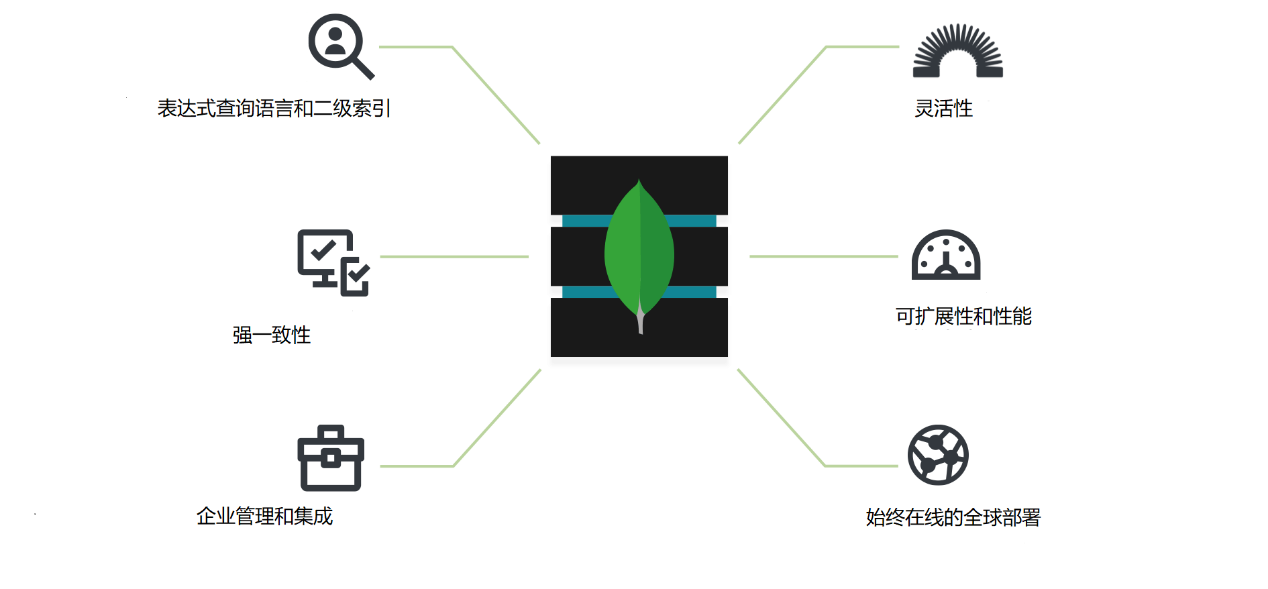
2.2.2 MongoDB数据库 10
2.2.3 MongoDB数据库特点 10
2.2.4基于MongoDB的数据存储 10
2.3 本章小结 11
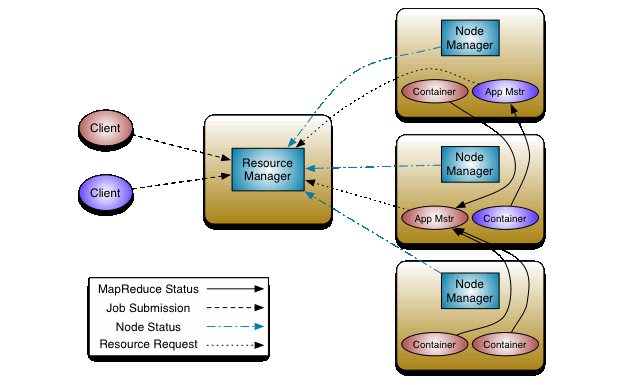
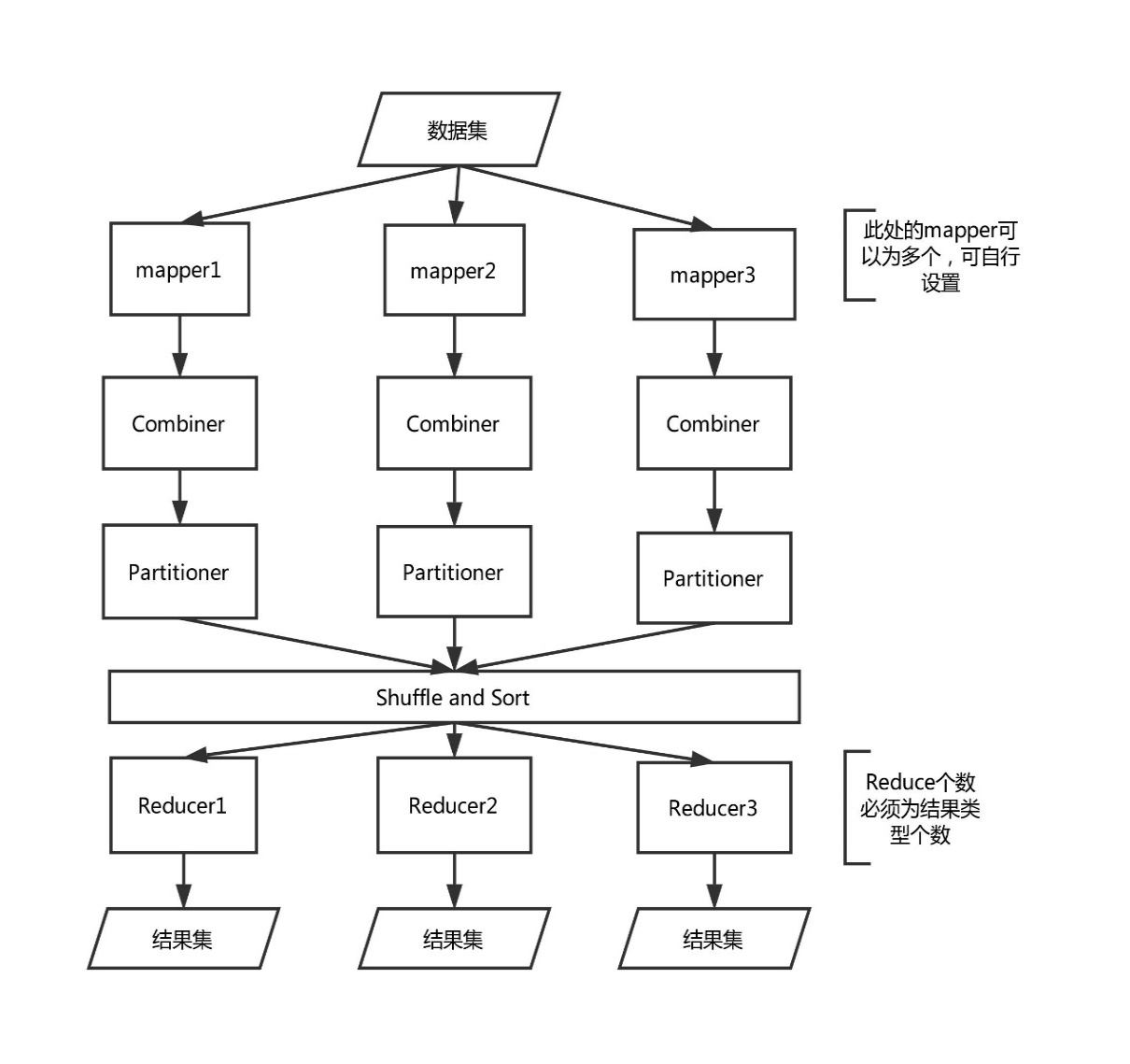
第三章 舆情分析的MapReduce模型 12
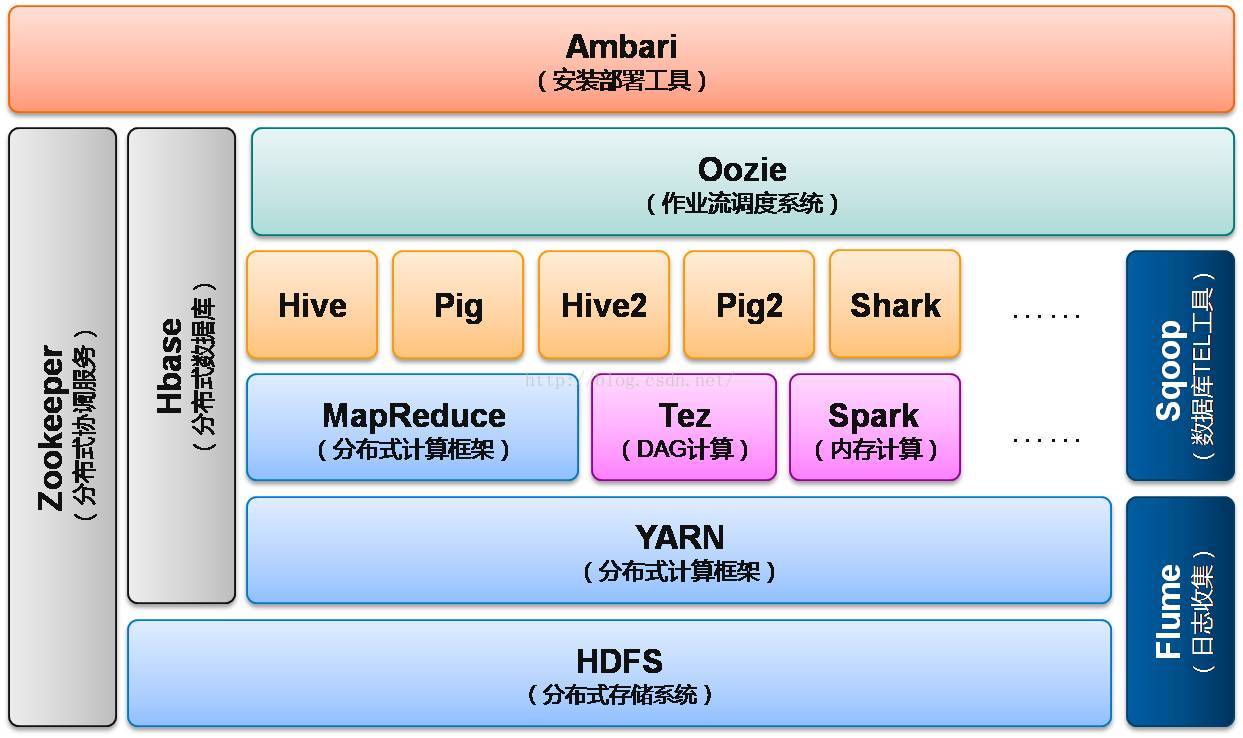
3.1 Hadoop概要 12
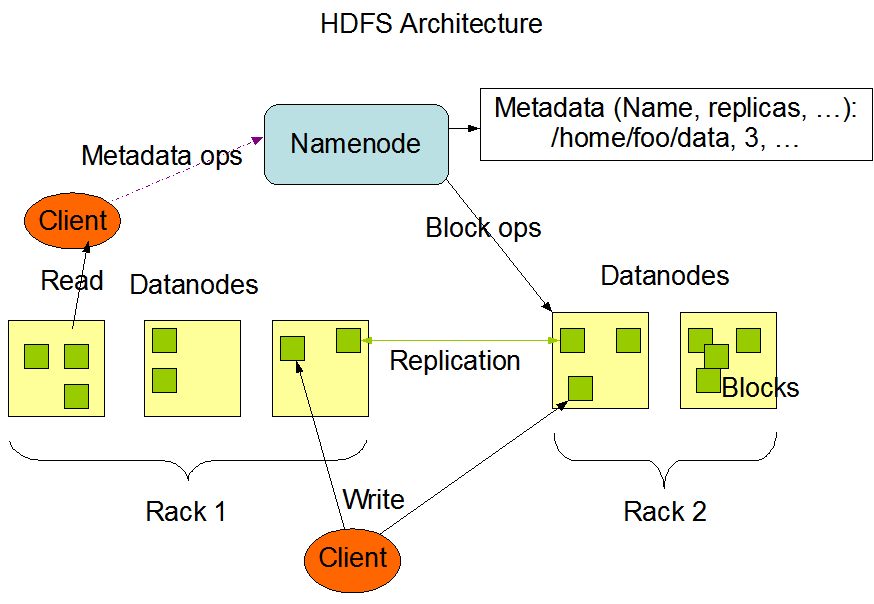
3.2 分布式文件系统 13
3.3 YARN 13
3.4 舆情数据源的MapReduce模型 14
3.5 本章小结 16
第四章 舆情分析算法和可视化 17
4.1 中文分词算法 17
4.2数据分析 17
4.2.1聚类分析算法k-means 18
4.2.2情感分析算法 19
4.2.3 文本相似度算法BM25 19
4.3数据的可视化分析结果 20
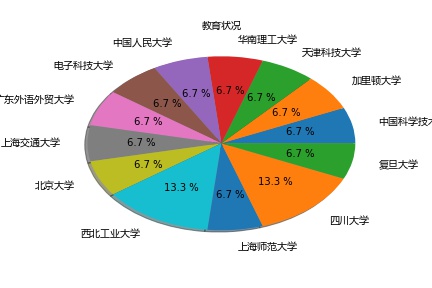
4.3.1教育情况的分析 20
4.3.2基于K-means的用户影响力的分析结果 21
4.3.3用户地理位置的分析结果 21
4.3.4 词云分析结果 22
4.3.5社交平台用户情感分析结果 22
4.4图形用户界面 24
4.5本章小结 27
第五章 系统框架和实现 28
5.1系统的开发环境 28
5.2 爬虫与MongoDB数据库 28
5.3 从MongoDB数据库到HDFS文件系统 29
5.4 数据清洗和重载 29
5.5 MapReduce过程 29
5.6 Hadoop文件系统 30
5.6 本章小结 30
第六章 总结和展望 31
6.1总结 31
6.2展望 31
参考文献 33
致谢 35
第一章 绪论
1.1研究背景及意义
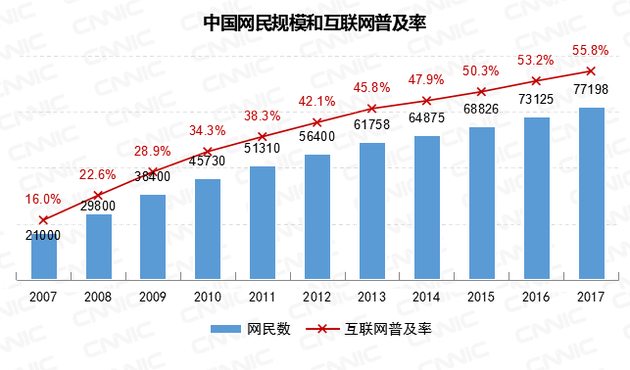
从20世纪末期,互联网诞生之初,没有人会想到经过二十多年的发展,互联网已经成为现代社会的主流媒介,人们通过互联网可以进行几乎所有领域的活动。近年来,随着生活水平的提高,网络覆盖范围不断变大,大半个中国乃至全世界许多地方都能通过运营商接入互联网,随之而来的是网络数据呈现出爆发式增长,互联网俨然成为了一个巨大的信息存储库,供用户查询,数据的存储,数据的修改和数据的删除。2018年新年伊始中国互联网络信息中心发表了《第41次中国互联网络发展状况统计报告》,在该报告中可以看出,到2017年底,中国网民人数为7.72亿,在全国总人数13.8亿中占比55.8%,全球网民人数占总人口数的比率比55.8%低4.1%,亚洲网民数量占亚洲总人口数的比率比55.8%低9.1%,从中可见,我国网络的普及率很高,且我国网民数量正在不断的增长,随着中国互联网的快速发展,中国在互联网的服务方面不断的优化升级,通过线上和线下服务的融合加速以及公共服务中线上服务进程提高的步伐加快,使得网民数量不断增加。历年来网民规模和网络普及率如下:
相关图片展示: