基于决策树与随机森林的光纤光栅振动信号的识别与分类毕业论文
2020-02-17 22:21:02
摘 要
随着光纤传感技术高速发展,分布式声传感系统(Distributed Acoustic Sensing,DAS)成为了实现周界安防监测等多领域的常用技术。为了解决其不同的环境下所采集到的传感信号复杂多变,难以辨识和区分的问题,本文对分布式光纤光栅振动传感信号的分类和识别进行了研究与设计。
本文的工作主要包括两部分。一方面,本文对光纤光栅振动信号的数据处理进行了理论分析和实现。完成了对原始振动信号数据的清洗和归一化,并进行数据的特征选定和分割处理,为后续算法实现打下了基础。另一方面,本设计以随机森林算法为核心,通过对处理后振动信号数据的学习和训练,完成了对振动信号分类识别的功能。
设计结果表明,随机森林算法对于光纤光栅振动信号有较好的分类识别效果,同时能够降低泛化误差,避免过拟合。本文最终实现了一种具有较高易用度与准确性的光纤光栅振动信号分类识别的设计,该设计测试识别的准确率达到了90%。
关键词:决策树;随机森林;光纤光栅信号数据处理;信号分类识别
Abstract
With the rapid development of information technology, distributed acoustic sensing system (DAS) has become a common technology to realize distributed fiber grating monitoring. In order to solve the problem that the sensor signals collected in different environments are complex and changeable and difficult to be identified and distinguished, this paper studies and designs the cla-ssification and recognition of distributed FBG vibration sensor signals.
This paper mainly includes two parts. On the one hand, the data processing of FBG vibrati-on signal is theoretically analyzed and realized in this paper. By cleaning and normalizing the or-iginal vibration signal data, and selecting and segmenting the characteristics of the data, it lays a foundation for the implementation of subsequent algorithms. On the other hand, this design takes the random forest algorithm as the core, and through the learning and training of the processed vibration signal data, the function of vibration signal classification and recognition is completed.
The design results show that the random forest algorithm has better classification and reco-gnition effect for vibration signals, and can reduce generalization error and avoid overfitting. In this paper, a novel vibration signal classification and recognition design with high usability and accuracy is finally implemented.
Keywords: Decision tree; Random forest; Fiber grating signal data processing; Signal classification and recognition
目 录
摘要 I
Abstract II
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 1
1.2.1 光纤振动信号识别的研究现状 1
1.2.2 随机森林算法的研究现状 2
1.3 本文的主要工作与结构安排 2
1.3.1本文的主要工作 2
1.3.2本文的结构 3
第2章 光纤光栅振动信号数据处理方法 5
2.1光纤光栅数据预处理 5
2.1.1 数据清洗 5
2.2.2 数据归一化 6
2.2光纤光栅数据转换 7
2.2.1 数据特征提取 7
2.2.2 数据分割 9
2.3 本章小结 9
第3章 随机森林算法的相关理论 10
3.1 决策树 10
3.1.1 决策树原理 10
3.1.2 决策树算法划分 11
3.2 集成学习 13
3.2.1 基分类器构造与集成 13
3.2.2 袋装算法 14
3.3 随机森林 14
3.3.1 随机森林的定义 14
3.3.2 随机森林的泛化误差 15
3.3.3 随机森林算法流程 16
3.4 本章小结 16
第4章 设计结果及其分析 17
4.1 设计流程与实验环境 17
4.2 光纤光栅数据处理 18
4.2.1 数据采集与清洗 18
4.2.2 数据归一化 18
4.2.3 特征提取与数据分割 19
4.3 算法模型设计 20
4.3.1 模型构建 20
4.3.2 模型实现 20
4.3.3 测试结果与分析 22
4.4 本章小结 23
第5章 总结与展望 24
5.1 全文总结 24
5.2 工作展望 24
参考文献 25
致谢 27
第1章 绪论
1.1 研究背景与意义
随着信息技术的高速发展与互联网的迅速普及,让信息无处不在、无孔不入。从商业发展到科学研究,从银行政府到医疗保险,各个不同的领域的信息都在爆炸式增长,同时也积累了大量的数据,甚至这种增长超过了我们创造机器的速度,超过了我们的想象空间。在大数据时代的背景下,面对“数据摩尔定律”的挑战,如何处理和分析数据成为了我们急需面对的问题。数据挖掘作为当下最流行的数据分析技术之一,可以将数据中潜在有用的信息提取出来,通过建立计算机程序来发现其规律或者模式,从而达到对数据进行识别、预测和分类的目的。
在光纤光栅传感的应用领域,光纤受外力产生的应变将反应在光栅之间的光程差的变化。光纤光栅传感器不仅具有便携、成本低、动态范围宽等优点,而且因其抗电磁以及灵敏度高的特性可适用于应用场景多变的大范围高精度测量场所。目前,在相关研究中,性能表现最为出色的是分布式声传感系统(Distributed Acoustic Sensing, DAS)。通过超弱反射率的光纤光栅实现了对连续空间公里级的结构监测,同时测量的应变灵敏度达到纳应变量级,因此该技术能常常用于实现大容量的分布式光纤光栅监测[1]。但由于其应用场景多变,不同的环境下所采集到的传感信号复杂多变,难以辨识和区分。因此,对于DAS系统的传感信号的分类识别将会是分布式光纤传感领域的一个发展热点。
针对DAS系统在应用中的实际需要,本文旨在研究对分布式光纤光栅振动传感信号的分类和识别,满足行业发展对DAS系统中大数据光纤光栅振动传感信号的分类识别需求,具有重要的研究价值以及应用前景。
1.2 国内外研究现状
1.2.1 光纤振动信号识别的研究现状
光纤光栅振动信号由于振动信号的非平稳性与随机性,致使振动信号具有比较大的不确定性,所以在对各类振动信号的检测与识别中容易出现误报的现象[2]。然而随着模式识别方法和信号处理技术的不断发展,光纤光栅振动信号识别的研究取得了较好的成果。这些成果主要表现在以下几个方面:
(1)采用对光纤信号属于进行预处理和特征提取方法,主要方法包括利用小波分析法对信号进行降噪,之后提取数据的频域或时域特征,根据信号特征判断信号类型。由于实际情况中高斯噪声容易对信号的功率谱、频带和峰值等特征造成干扰[3],采用这种方法处理中会出现对信号的特征模糊提取和造成线性稳态缺陷的问题;
(2)采用传统识别分类方法,如经验阈值法[4]或支持向量机算法,通常情况下使用传统方法的模型训练效果比较好,但实际情况中,光纤振动信号的采集往往会受到外界噪声的干扰,此时常常会出现识别准确率下降的问题。
1.2.2 随机森林算法的研究现状
随机森林(Random Forest, RF)算法是由美国科学院院Leo Breimam在2001年提出的一种集成机器学习方法[5]。随机森林采用基于随机子空间方法创建的,该方法结合了袋装算法和随机选择特征的方式,算法构建多棵决策树并作为其分类的模式来进行结果输出。从此,随机森林算法正式成为数据分析算法中的重要组成部分之一,并应用于各类领域。
近年来,决策树与随机森林算法由于具有易收敛、鲁棒性好、分类精度高等特点,被广泛应用于众多数据分类任务中。在金融领域方面,为了使高校财务管理更加科学,将数据处理、数据分析等技术应用到高校事务决策中。金茂珠[6]等人针对高校财务管理系统生成的大量财务数据,采用决策树算法实现高校财务管理与决策,为高校的财务管理提供了有效的支持,使高校财务管理和决策更加方便有效;在遥感地理方面,Junshi Xia[7]等人提出了基于随机森林集合的高光谱图像分类技术,同时使用了使用四种策略,包括装袋、随机子空间、基于旋转和基于旋转的增强方法来构建随机森林集合,最终在两个基准高光谱图像上验证了该方法的有效性;另外,随机森林算法在机械设备故障诊断[8]、交通事件估计[9]、医学病理数据分析[10]等领域,也取得了较为满意的成果。
1.3 本文的主要工作与结构安排
1.3.1本文的主要工作
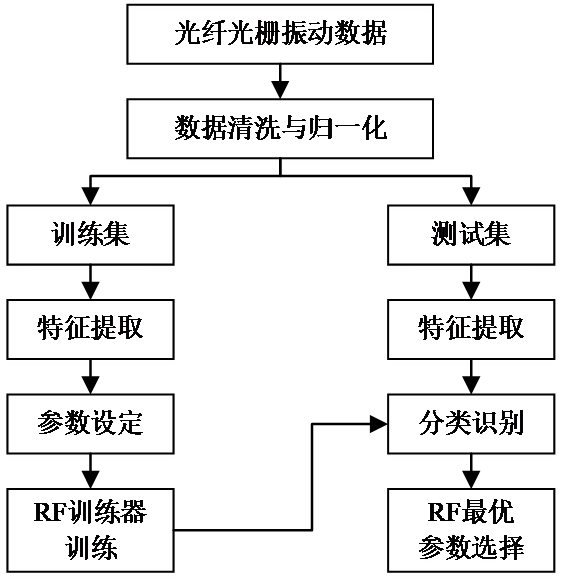
本文的主要工作在于实现光纤光栅振动信号的识别与分类系统,并验证光纤光栅数据分类效果,同时完成了基于决策树与随机森林的光纤光栅振动信号的识别与分类系统的资料整理和论文编写。
本课题旨在研究数据处理方法与随机森林的基本结构等理论,了解其应用背景及研究现状,使用TensorFlow深度学习框架,以实现光纤光栅振动信号的识别与分类方法的设计,达到80%以上的光纤光栅振动信号类型识别的准确率。

图1.1 课题设计框图
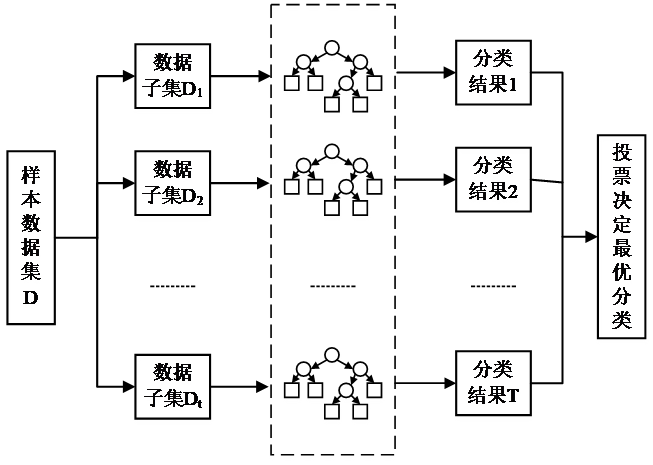
本课题的设计框架如图1.1所示。通过研究CART决策树与以多颗决策树组合模型为基础的随机森林算法的工作原理,利用TensorFlow深度学习框架搭建系统。系统调试中,需要对模型的相关参数进行设计,通过样本数据集完成对基分类器(CART决策树)的训练,形成随机森林。预测样本时,采用投票择优的原则从森林中选择最终预测样本的类别,从而实现光纤光栅振动信号的识别与分类,得到输出结果,在此基础之上对模型性能进行评价,提出模型优化的一些思路。基于以上实现基于决策树与随机森林的光纤光栅振动信号的识别与分类。
1.3.2本文的结构
第一章,绪论。作为全文的开篇部分,首先介绍了本设计研究的背景以及目的,并从光纤光栅振动信号的分类识别和随机森林两个方面对研究现状进行了总结和阐述。之后,对本文的主要工作进行了概括与分析,同时对本文的论文结构进行了安排和说明。
第二章,光纤光栅振动信号数据处理方法。光纤光栅数据处理方法的步骤包括数据预处理以及数据的转换。关于数据预处理方面,本章主要介绍了关于数据清洗的基本方法以及清洗过后的归一化方法;而关于数据转换过程的方面,本章则对数据特征选定以及分离数据集样本的相关方法进行了阐述。
第三章,随机森林算法的相关理论。本章首先介绍了决策树的原理,指出了决策树存在过拟合问题,之后给出了决策树的三种形式,并分析了它们的特点。后续部分中,本章对集成学习的基本思想进行了阐述,并总结了基分类器构造与集成的方法,最终对集成学习中的袋装算法进行了原理说明,并指出了随机森林算法是袋装算法的一种特例化形式。最终,本章对随机森林的相关理论进行了阐述,分析了算法的泛化误差,指出了随机森林很好的解决了过拟合的问题,并总结了随机森林的算法流程。
第四章,设计结果及其分析。本章的内容主要围绕着光纤光栅振动信号分类识别具体设计进行的。首先,本章对设计的总体流程进行了描述,同时也对总体设计的实验环境进行了说明。其次,本章对如何处理光纤光栅数据进行了说明,并随机挑选两组信号数据进行处理和演示。最终,本章展示了算法模型的实现过程,并对基分类器(决策树)的可视化图进行了说明,最终从样本中挑选了一些数据进行了结果的测试与验证。
第五章,总结和展望。首先对本文进行一个全面的总结,之后对后续的工作展望进行了说明,提出了关于设计与算法改进的一些想法。
第2章 光纤光栅振动信号数据处理方法
在工程实践中,由于光纤光栅振动信号数据收集环境的复杂,得到的数据可能会受到噪声干扰,也可能存在有重复值以及缺失值等问题,在使用之前需要进行数据处理的环节。数据处理是数据挖掘过程中一个经常被忽视但又十分重要的步骤,没有经过仔细筛选的数据可能产生误导的结果,数据预处理包括数据清洗、归一化以及包括数据特征选定和数据分离的数据转换等任务。数据准备没有统一的流程,通常根据不同的设计需求和数据特征的不同而不同,大致可分为两个步骤:数据预处理和数据的转换。数据处理是一项完整设计的必要环节,能够有效提高最终算法模型识别的准确率。因此,为了提高算法模型的精度,在数据分析过程中,需要根据算法的特点和数据的特征对数据进行处理。
2.1光纤光栅数据预处理
2.1.1 数据清洗
在实际情况中,正确采集数据后,并不意味着数据没有错误,数据的采集过程往往伴随着数据的污染,广义上来说,污染数据包括丢失的数据、错误的数据和相同数据的非标准表示。如果大量的数据是脏的,那么应用到算法的过程肯定会导致模型不可靠,脏数据对不同的算法往往会有不同程度的影响,同时也很难量化这种影响。所以在将数据应用任何机器学习技术之前,必须清洗数据以删除或修复脏数据。数据清洗的步骤如图所示:

图2.1 数据清洗步骤图
脏数据的来源包括数据采集错误、数据更新错误、数据传输错误,甚至数据处理系统中的错误。在训练数据集或测试数据集中存在高比例的脏数据可能会产生不太可靠的模型,所以数据处理的第一步就需要对数据集进行清洗工作。数据清洗的目的有两个,第一是通过对原始数据集清洗让数据可用。第二是让数据变的更适合进行后续的分析工作。数据清洗通常包括以下的方法:
(1)处理数据缺失值
对于一个较小的数据集,我们可以通过人工查找的方式来处理这个问题,但对于较为庞大的数据集,就需要寻找和使用一个更为方便快捷的方法。典型的处理缺失数据的方法包括删除法与填充法。
删除法是最简单的缺失值处理方法,当数据缺失率高且属性重要程度低时,可以采取直接删除该属性的方式。然而在缺失值高且属性程度较高情况下,直接删除该属性对于算法的结果可能会造成很不好的影响,甚至在最后得到了一个有偏差的统计结果。
填补法主要使用在数据重要程度低且缺失率少属性的情况下,通过非缺失的数据集中找到一个与缺失值所在样本相似的样本,这个样本也被称为匹配样本,利用匹配样本中的观测值对原始数据的缺失值进行填补。
(2)数据去重处理
首先要对数据的重复项进行判断,通常的方法是按照某些规则预先对样本数据进行排序,然后比较相邻的记录是否相同来检测重复数据。 整个过程其实包含了两步,一是排序,二是计算相似度,然后将重复的样本进行简单的删除处理。
(3)数据异常值处理
异常值通常也被称为“离群点”,通常拿到我们需要对原始数据集进行一个简单的描述性统计分析来判断样本数据的取值是否超过了合理的范围,之后可以按照数据缺失值的处理方法对其进行处理。
2.2.2 数据归一化
数据归一化处理是数据分析的一项必要的工作,在工程中实际测量的数据往往可能具有不同的量纲和量纲单位,如果各个数据属性按照不同的方式来度量数据,这种情况会影响到算法模型的结果。那么通过对数据尺度的调整将所有的数据属性重新缩放到相同的值范围,来消除特征之间的量纲影响,就会给后续的算法模型训练带来极大的方便。
数据归一化处理通常是将数据的所有属性标准化,并将数据转换为特定范围之间的值,数据归一化的方法通常有一下几类:
(1)离差归一化
离差归一化也被称为min-max归一化,其目的是将数值属性的所有数值缩放到指定的范围(通常指0到1之间)。标准化的公式如下:
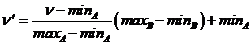 (2.1)
(2.1)
其中,maxA和minA分别是原始的最大和最小属性值。
“归一化”通常指的是min-max归一化的一种特殊情况,其最终区间为[0,1],公式(2.1)中即表示为minB = 0,maxB = 1,但在对数据进行归一化时,常常也会将最终的归一化区间设置为[- 1,1]。
使用归一化方法可以将所有数据重新缩放到相同的值范围,来避免模型计算中以maxA−minA的差这一属性占主导地位[11],使学习过程更加重视数据其他的属性,从而误导学习过程。这种归一化也被认为可以加速算法模型的学习过程,帮助模型更快地收敛。
(2)标准差标准化
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: