基于YOLO v3的智能驾驶行人检测算法研究毕业论文
2020-02-17 21:09:52
摘 要
行人检测作为一种重要的目标检测应用,在自动驾驶,视频监控,刑侦等多个领域受到广泛关注。本文研究基于YOLOv3的行人检测,将深度学习方法应用于行人检测任务中,分析存在的问题,进而改进模型,使其有更好的性能表现。
首先在理论上对YOLO三个迭代版本和一个快速版本进行详细的对比和分析,重点分析其网络结构和目标函数的发展和改进,以及使用的网络改进方法。其次根据智能驾驶的研究背景,结合两个行人数据集的特点,使用INRIA Person Dataset和Caltech Pedestrian Detection两个数据集组合成新的行人检测数据集。该数据集融合了静态行人照片的高清晰度、辨识度和运动行人的形态变化和遮挡以及远处小行人的特点。着重分析YOLOv3-tiny权重在训练集上重新训练的过程和训练得到的模型表现,使用K-means算法修改anchor box尺寸使其贴合行人特征并重新训练。在测试集上进行实验和测试,对比分析改进措施的实际效果,并对网络性能进行了解释和分析。
实验结果表明,与原始YOLOv3-tiny相比,修改后的模型在收敛速度、检测速度和检测性能均有一定的提高。
关键词:卷积神经网络;深度学习;YOLO;行人检测
Abstract
As an important object detection application, pedestrian detection has received extensive attention in many fields such as autonomous driving, video surveillance, and criminal investigation. This paper studies the pedestrian detection based on YOLOv3, applies the deep learning method to the pedestrian detection task, analyzes the existing problems, and then improves the model to make it have better performance.
Firstly, the three iterative versions and a quick version of YOLO are theoretically compared and analyzed in detail, focusing on the development and improvement of the network structure and objective function, and the network improvement method used. Secondly, according to the research background of intelligent driving, combined with the characteristics of two pedestrian data sets, two data sets of INRIA Person Dataset and Caltech Pedestrian Detection are combined into a new pedestrian detection data set. The data set combines the high-definition, recognizability, and morphological changes and occlusions of static pedestrian photos with the characteristics of distant pedestrians. Emphasis is placed on the process of retraining the YOLOv3-tiny weights on the training set and the performance of the trained model. The K-means algorithm is used to modify the anchor box size to fit the pedestrian characteristics and retrain. Experiment and test on the test set, compare and analyze the actual effect of the improvement measures, and explain and analyze the network performance.
The experimental results show that compared with the original YOLOv3-tiny, the modified model has a certain improvement in convergence speed, detection speed and detection performance.
Key Words: Convolutional neural network; Deep learning; YOLO;Pedestrian detection
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.2 相关研究工作 1
1.3 研究内容 3
1.4 全文安排 4
第2章 深度学习基本理论 5
2.1 神经网络基础 5
2.1.1 神经元模型 5
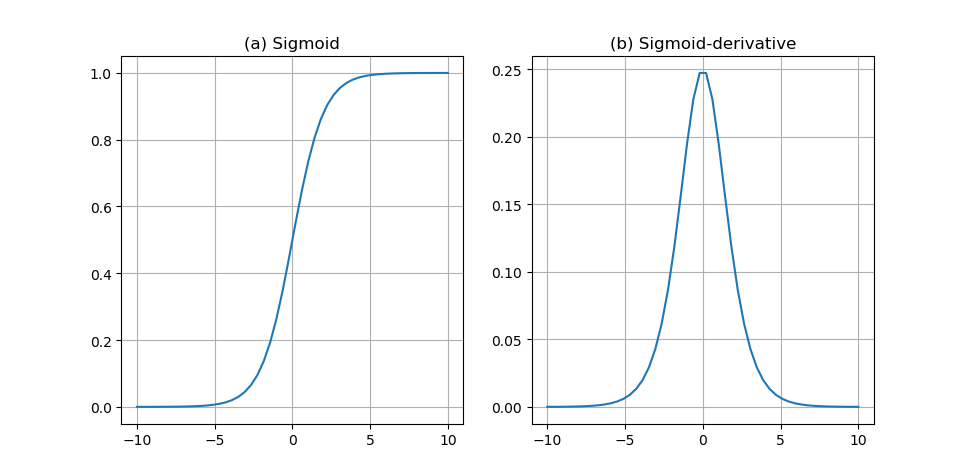
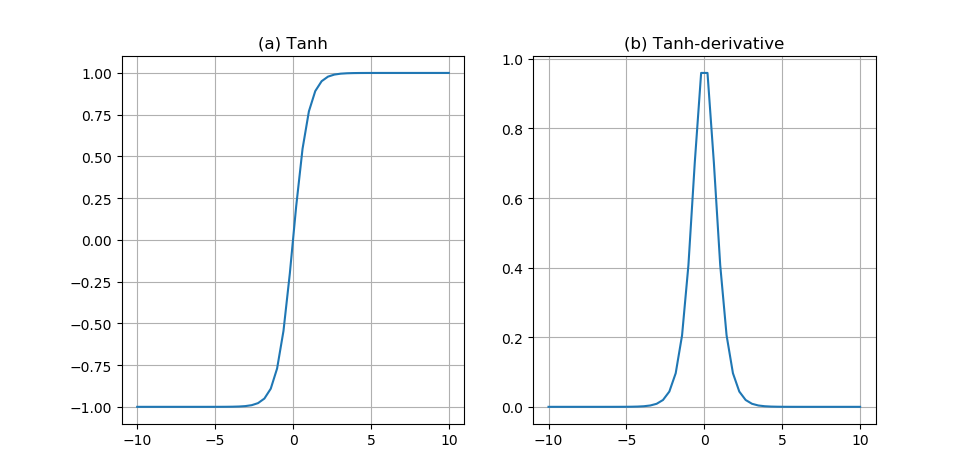
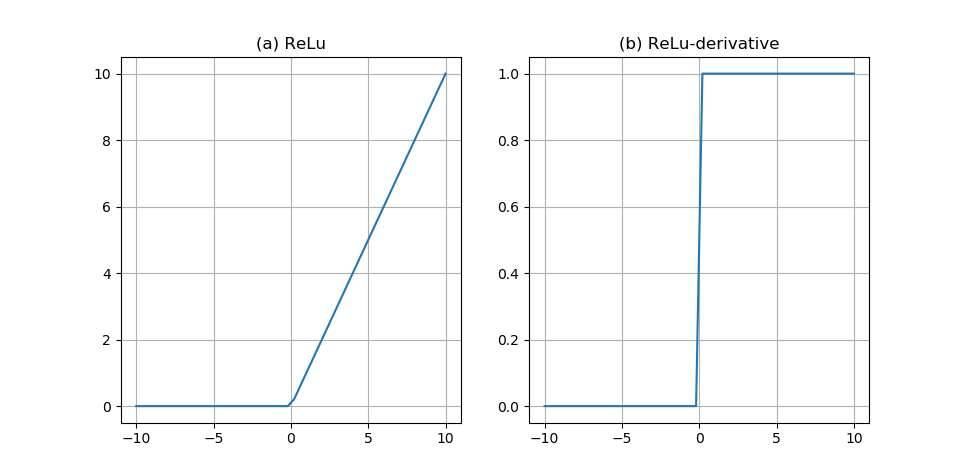
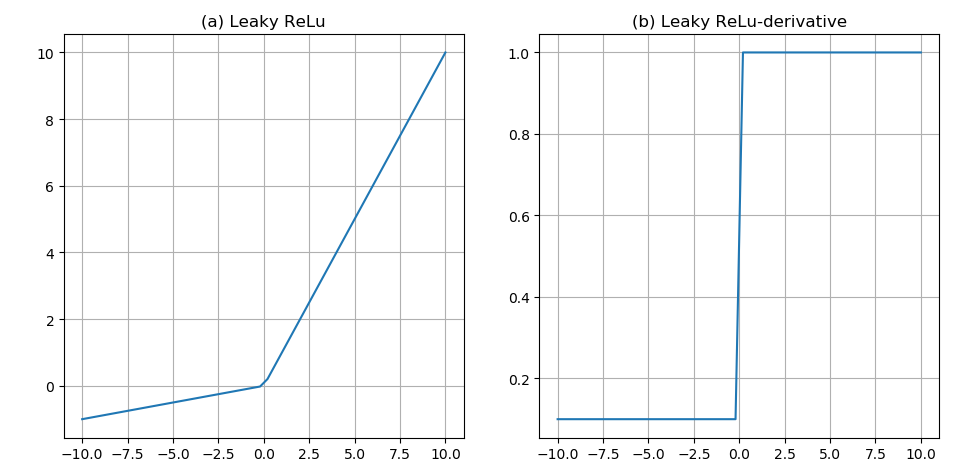
2.1.2 激活函数 6
2.1.3 损失函数 8
2.1.4 前向传播与反向传播 9
2.1.5 优化算法 10
2.2 卷积神经网络 12
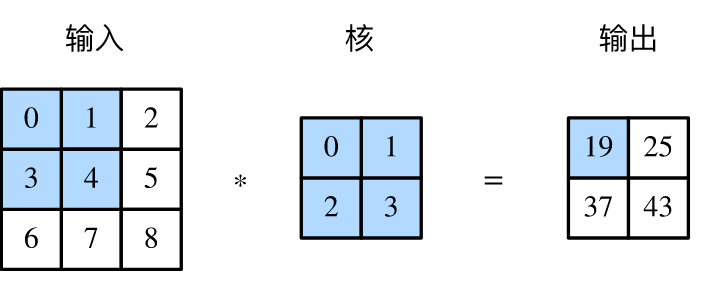
2.2.1 卷积层 12
2.2.2 池化层 13
2.2.3 BN层 14
2.2.4 残差网络 14
2.3 目标检测 15
2.3.1 边界框和IoU 15
2.3.2 anchor box和NMS 16
2.3.3 评价标准 18
第3章 YOLO模型 19
3.1 YOLOv1 19
3.1.1 基本思想 19
3.1.2 网络结构 20
3.1.3 损失函数 21
3.2 YOLOv2 22
3.2.1 改进策略 22
3.2.2 网络结构 23
3.2.3 损失函数 24
3.3 YOLOv3 25
3.3.1 改进策略 25
3.3.2 网络结构 26
3.3.3 损失函数 27
3.4 YOLOv3-tiny 28
第4章 算法实现及实验分析 30
4.1 智能驾驶数据集 30
4.2 YOLOv3的实现 31
4.2.1 微调YOLOv3 31
4.2.2 实验与分析 32
4.3 YOLOv3-tiny的改进 34
4.3.1 修改网络结构的输出 34
4.3.2 K-means计算anchor box尺寸 35
4.3.3 实验与分析 35
第5章 总结与展望 39
5.1 工作总结 39
5.2 未来展望 39
参考文献 41
致 谢 43
第1章 绪论
研究背景及意义
据公安部统计,2018年全国新注册登记机动车3172万辆,机动车保有量已达3.27亿辆,其中汽车2.4亿辆,小型载客汽车首次突破2亿辆[1]。随着我国汽车的使用量增加,道路交通安全事故也成为我国交通事业发展的一大隐患。
交通事故的发生是由多种因素造成的,其中人的因素中的由驾驶员引发的事故占据了绝大部分。相关调查报告表明,如果驾驶员在交通事故发生前0.5秒获得提醒,则可以避免60%的后续碰撞事故;而1.5秒的额外反应时间,则可以避免90%的交通事故。因此行人检测系统的检测速度在智能驾驶系统中尤其重要,是及时预警避免事故的关键。
具有行人检测功能的自动紧急制动系统(AEB)是现代化汽车必须具备的安全功能之一,而某品牌车企公布的一份列表以强调旗下汽车行人检测软件的缺陷。而这些局限性并不是该品牌汽车独有的,所有使用相同AEB系统的都可能面临相同的问题。这表明现有的行人检测软件或算法的精度以及实时性依然不能很好地保障行人与乘客的生命安全。
由于我国机动车保有量大,行人在道路交通事故中受到的安全威胁大,辅助驾驶提醒的收益高等原因,一个精度高,实时性高,鲁棒性强的行人检测器对降低交通事故、保障行人安全尤为重要。
相关研究工作
目标检测是一项重要的计算机视觉任务,用于检测数字图像中某类(例如人,动物或汽车)的视觉目标的实例。目标检测的任务是开发计算模型和技术,提供计算机视觉应用所需的最基本信息之一:哪些对象在哪里?
作为计算机视觉的基本问题之一,目标检测构成了许多其他计算机视觉任务的基础,如实例分割,图像描述,目标跟踪等。从应用的角度来看,目标检测可以分为两个研究课题,“一般目标检测”和“检测应用”,前者旨在探索在统一框架下检测不同类型对象的方法,以模拟人类视觉和认知,后者是指特定应用场景下的检测,如行人检测,人脸检测,文本检测等。近年来,深度学习技术的快速发展为目标检测带来了新的血液,取得了显着的突破,并将其推向了前所未有的关注研究热点。
在过去的二十年中,人们普遍认为目标检测的进展一般经历了两个历史时期:以2014年为分界,往前传统方法主导,而往后深度学习方法取得巨大成就,如图1.1所示。
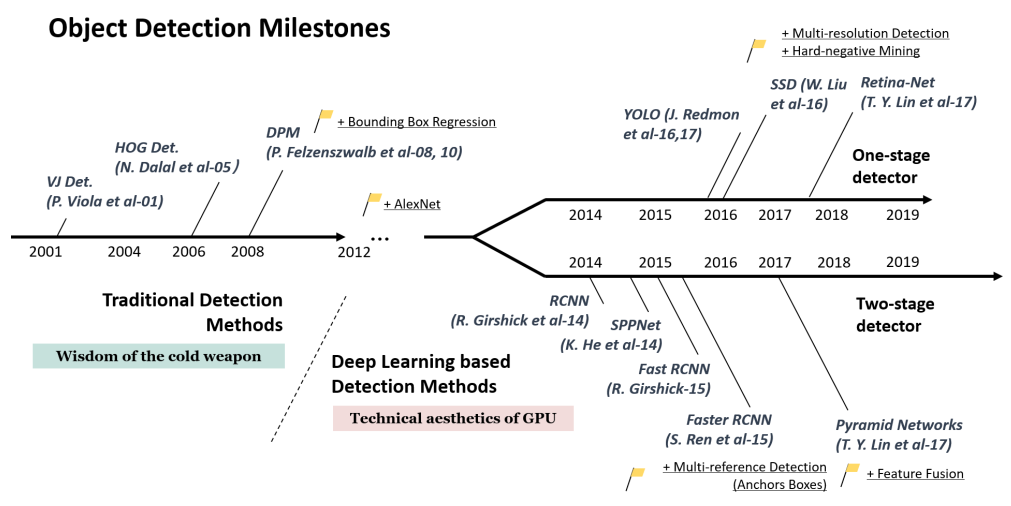
图1.1 目标检测发展里程碑
2012年,世界看到了卷积神经网络的重生[2]。由于深度卷积网络能够学习图像的强大和高级特征表示,一个自然的问题是我们是否可以将其用于目标检测?R. Girshick等在2014年率先通过提出具有CNN特征的区域(RCNN[3])进行目标检测来打破僵局。从那时起,目标检测开始以前所未有的速度发展。
在深度学习时代,目标检测可以分为两种类型:“两步检测”(two-stage)和“一步检测”(one-stage),前者将检测框架化为“粗略到精细”过程,而后者将其框架化为“一步完成”。
two-stage的开山鼻祖RCNN[3]背后的想法很简单:它首先通过选择性搜索提取一组目标提议(目标候选框)。然后将每个候选框重新调整为固定大小的图像,并将其输入到在ImageNet上训练的CNN模型(例如AlexNet[2])以提取特征。最后,线性SVM分类器用于预测每个区域内目标的存在并识别目标类别。RCNN在VOC07表现出显着的性能提升,平均精度(mAP)从33.7%大幅提高到58.5%。
尽管RCNN取得了很大的进步,但它的缺点是显而易见的:大量重叠候选框(一张图像超过2000个候选框)的冗余特征计算导致检测速度极慢。SPPNet[4]克服了这个问题。
当使用SPPNet[4]进行目标检测时,可以仅从整个图像计算一次特征图,然后可以生成任意区域的固定长度表示以训练检测器,这避免了重复计算卷积特征。SPPNet比R-CNN快20倍以上而不牺牲任何检测精度。尽管SPPNet有效地提高了检测速度,但仍然存在一些缺点:首先,训练仍然是多阶段的;其次,SPPNet仅对其完全连接的层进行微调,而忽略了所有先前的层。
Fast RCNN[5]是对R-CNN和SPPNet的进一步改进。Fast RCNN使我们能够在相同的网络配置下同时训练检测器和边界框回归器。在VOC07数据集上,Fast RCNN将mAP从58.5%(RCNN)增加到70.0%,而检测速度比RCNN快200倍。Fast-RCNN综合了R-CNN和SPPNet的优势,但其检测速度仍然受到候选检测的限制。
Faster RCNN[6]是第一个端到端、近实时深度学习探测器。从RCNN到Faster RCNN,目标检测系统的大多数单独的模块(如提议检测,特征提取,边界框回归等)已经逐渐集成到统一的端到端学习框架中。
YOLO(“You Only Look Once”的缩写)v1在2015年被提出,是深度学习时代的第一个单级探测器[7]。YOLO非常快:YOLO的快速版本以155fps运行,VOC07 mAP = 52.7%,而其增强版本运行速度为45fps,VOC07 mAP = 63.4%,VOC12 mAP = 57.9%。从其名称可以看出它遵循的理念:将单个神经网络应用于完整图像。
同时代还有SSD[10]和RetinaNet[11]等one-stage检测器。在这基础上,YOLO取各家所长,在v1的基础上进行了一系列的演化进步,并提出了v2[8]和v3[9]版本,进一步提高了检测精度,同时保持了非常高的检测速度。
行人检测作为一种重要的目标检测应用,在自动驾驶,视频监控,刑侦等多个领域受到广泛关注。一些早期的行人检测方法,如HOG探测器,ICF探测器,在特征表示,分类器设计和检测加速度方面为一般目标检测奠定了坚实的基础。近年来,一些通用目标检测算法,例如,Faster RCNN,已被引入行人检测,并极大地促进了该领域的进步。
研究内容
本文研究基于YOLOv3的行人检测,行人检测数据库采用了INRIA Person Dataset[12]和Caltech Pedestrian Detection[13]两个行人数据库。借助深度学习框架Keras搭建卷积神经网络,对现有的深度学习算法基础和卷积神经网络进行分析研究。并分析YOLO的各个版本,在YOLOv3快速版本的基础上进行改进,使其在行人检测这一任务中具有更好地精度和速度。具体研究内容如下:
对YOLO三个迭代版本和一个快速版本进行详细的对比和分析,重点分析其网络结构和目标函数的发展和改进,以及使用的网络改进技巧和手段。
结合两个行人数据集的特点,使用两个数据集组合成新的行人检测数据集。该数据集融合了INRIA Person Dataset中静态行人照片的高清晰度、辨识度和Caltech Pedestrian Detection中运动行人的形态变化和遮挡以及远处小行人的特点。
利用迁移学习,对YOLOv3进行微调,在测试集上进行实验和测试。对YOLOv3-tiny权重在训练集上重新训练,使用K-means算法修改anchor box尺寸使其贴合行人特征并重新训练。在测试集上进行实验和测试,对比分析改进措施的实际效果。
全文安排
第一章为引言,阐述了行人检测课题的背景及意义和基于深度学习的目标检测算法研究国内外现状,以及行人检测的发展情况。其中着重介绍了基于深度学习的两类目标检测算法的发展进程。
第二章对深度学习理论基础进行了综合性的介绍,重点介绍计算机视觉中常用的卷积神经网络,并介绍目标检测相关概念。
第三章对YOLO系列算法原理进行分析研究,具体介绍了算法思想及每代的网络结构。按先后顺序指出YOLO各版本新加入的细节,对比分析各版本的共同点和不同点。
第四章针对行人检测这一明确目的,在开源行人检测数据集上对网络进行训练,对结果进行分析,以证明训练集的修改是将通用检测器转化成专用检测器的一大关键。同时在YOLOv3快速版本的算法上进行优化,针对行人宽比特点利用K-Means重新聚类得到新anchor box尺寸,对于提高行人检测的准确率鲁棒性有一定的作用。
第五章对整个工作内容进行总结,同时分析本文的不足之处,并对后续的研究给出自己的想法,提出了下一阶段工作的展望。
第2章 深度学习基本理论
2.1 神经网络基础
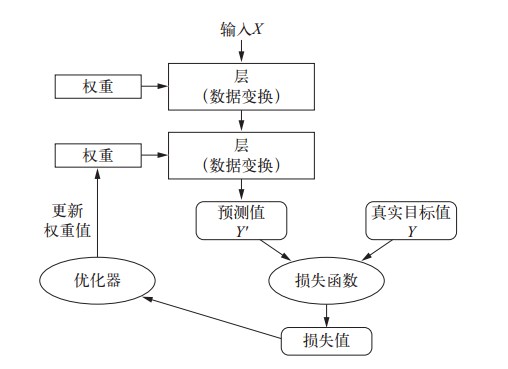
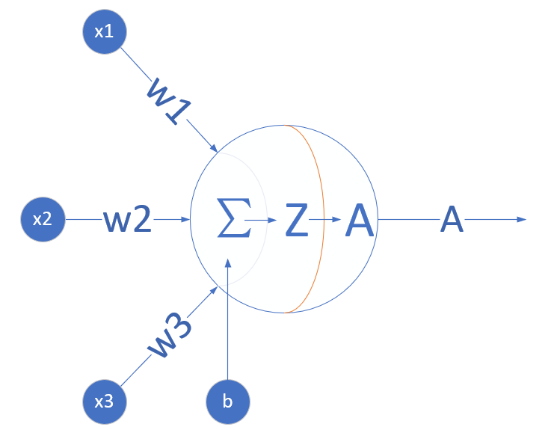
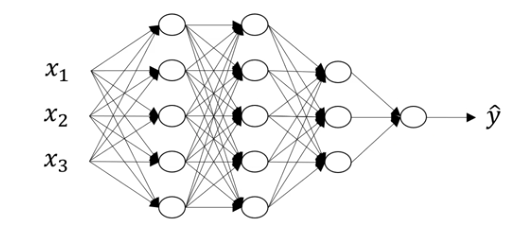
图2.1 神经网络训练模型
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: