基于深度学习的空间变换网络模型研究毕业论文
2020-04-12 16:26:02
摘 要
深度学习是机器学习研究中基于对数据进行表征学习的一种方法,用于实现文本识别,计算机视觉等工作,是人工智能研究中重要的学习方法。卷积神经网络是机器学习中的一种深度前馈人工神经网络,可用于大型图像处理。空间变换网络模型是可与神经网络并行放置,对输入图像调整分割后再传递给神经网络处理,使代价函数最小的一种优化模型。
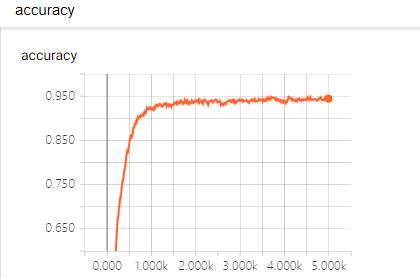
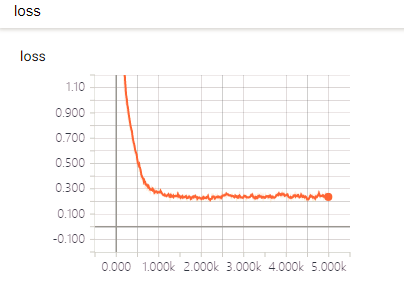
本文针对神经网络中的图像识别优化提出了基于深度学习的空间变换网络模型,主要研究了空间变换网络和卷积神经网络的基本原理,在TensorFlow平台使用python开发语言搭建卷积神经网络,实现空间变换网络模型,并将空间变换网络嵌入卷积神经网络中,本文还使用了扭曲变形的MNIST数据集来测试嵌入空间变换网络后的卷积神经网络性能的改善状况。实验结果表明,引入空间变换网络模型,图像识别的准确性得到了提升。
关键词:空间变换网络;卷积神经网络;仿射变换
Abstract
Deep learning is a method based on data representation learning in machine learning research. It is used to realize text recognition, computer vision, etc. It is an important learning method in artificial intelligence research. Convolutional neural networks are deep feedforward artificial neural networks in machine learning that can be used for large image processing. The spatial transformation network model is an optimization model that can be placed in parallel with the neural network, adjust the segmentation of the input image, and then pass it to the neural network for processing to minimize the cost function.
In this paper, a spatial transformation network model based on deep learning is proposed for image recognition optimization in neural networks. The basic principles of the spatial transformation network and convolutional neural network are mainly studied. The tensor neural network is built on the TensorFlow platform to achieve space. Transforming the network model and embedding the spatial transformation network in a convolutional neural network. This paper also uses the distorted MNIST dataset to test the performance improvement of the convolutional neural network after embedding the spatial transformation network. The experimental results show that the accuracy of image recognition has been improved by introducing the spatial transformation network model.
Key Words:spatial transformation network; convolutional neural network; affine transformation
目录
摘 要 1
Abstract 2
第1章 绪论 4
1.1 课题研究的背景及意义 4
1.2研究现状 4
1.3论文主要工作以及内容安排 6
第2章 算法理论 7
2.1仿射变换 7
2.2双线性插值 9
2.3卷积神经网络 11
2.4卷积神经网络可改进之处 15
2.5本章小结 16
第3章 基于深度学习的空间变换网络模型 17
3.1空间变换网络模型 17
3.2空间变换网络与卷积神经网络融合 19
3.3本章小结 20
第4章 仿真实验及其结果分析 21
4.1实验平台 21
4.2实验设计 21
4.3扭曲的MNIST数据集测试 24
4.4空间变换网络模型效果 27
4.4实验分析 28
第5章 结论与展望 30
5.1结论 30
5.2展望 30
参考文献 31
致 谢 32
第1章 绪论
1.1 课题研究的背景及意义
随着计算机互联网科技的不断发展,智能手机等电子设备逐渐普及,人们获取图像的手段也越来越丰富。如何从大量的图像中提取到有用的特征信息,进而对图像进行辨别变得十分重要,图像识别在工业生产,日常生活中的热度与日俱增,已成为信息处理领域的一个重要分支[13]。
图像识别是指利用计算机对图像进行处理,来识别不同模式下的目标和对象的技术。图像识别是以其主要特征为基础的,每个图像都有自己的特征,如字母O是个圆圈,字母Z有两个锐角等,对人类视觉的研究表明,视线总是集中在图像的主要特征上,这些主要特征是信息量最大的位置,对复杂图像的识别往往要经过不同层次的信息加工才能实现,训练过的图像往往会留下特征,这些特征会被保存,作为一个单元来识别。在计算机视觉中,图像内容使用图像特征进行描述,识别过程为:图像输入,预处理,特征提取,分类和匹配。图像识别的常用方法有:模板匹配法,贝叶斯分类法等。随着人工智能的发展,基于深度学习的图像识别方法出现,使以往数学办法解决复杂问题的工作简单化[14-15]。
深度学习是近十多年来人工智能领域取得的重要突破,它在语音信号识别、自然文本处理、计算机视觉、图像与视频分析等多领域获得了广泛应用。深度学习与传统的模式识别方法的最大不同之处在于它选用的特征是从大数据中自动学习得到,而不是通过使用手工设计,在传统的识别方法中,手工设计特征的方法一直处于统治地位,但是过于依赖手工方式调试参数,特征的设计中参数数量不够充分,而深度学习由于能够自动在大数据中学习,特征中可以包含成千上万的参数,在时间花费上,能够很快学习新特征的深度学习也占有巨大优势。因此深度学习运用到图像识别当中,极大地提升了图像模式识别的效率和准确度[4-9]。
为了更进一步地提高图像识别的效率和准确性,有必要对神经网络结构进行优化。
1.2研究现状
1.2.1深度学习的发展和研究现状
现有的深度学习模型属于神经网络,继承了神经网络的架构,发展了深层结构和自动学习数据特征的功能。神经网络的发展可追溯到上世纪四十年代,从最初的仅能进行二值判断的感知机,到后来七八十年代出现的三层神经网络,神经网络不断发展。1986 年Rumelhart、Hinton 和 Williams 在杂志《science》上发表了反向传播算法,这种深度学习算法受到了广泛使用[4-9]。
由于最初的神经网络容易过拟合并且参数训练速度慢等原因,它渐渐被多数研究者放弃,相比于生物神经网络,传统的神经网络只是一个浅层结构,学习能力太弱。直到2006年,加拿大多伦多大学的Hinton教授和他的学生Ruslan Salakhutdinov在《science》杂志上发表文章,提出了深度学习,阐述了两个重要的观点:1.多隐藏层的神经网络可以学习到能刻画出数据本质属性的特征,对数据可视化和分类任务有很大帮助;2.可以借助于无监督的“逐层初始化”策略来有效克服深层神经网络在训练遇到的困境[16]。深度学习从此进入了学者研究的视野,在学术界和工业界得到了广泛地应用。
1.2.1空间变换网络模型研究现状
以往优化算法的实现,大都是通过改善训练方式,来对损失函数进行优化,例如Keras中的SGD、Momentum、Adagrad、Adam、Adamax等优化器,这些优化算法目的都是用于优化学习速率,使网络的训练能力达到最佳,并防止过拟合的出现,同样,在很多深度学习平台都包含大量的优化算法,这种网络内部优化有一定效果,但是当数据量过大,过复杂时,仍然存在耗时和准确性问题[10-12]。
图像是深度学习最早尝试的领域。随着技术的发展,基于深度学习的目标识别方法出现,大大提高了图像识别的准确度和识别效率,但是图像信息的扭曲变形制约了图像识别的进一步发展。图像识别模型的构建基于深度学习的理念,以数据的原始形态作为算法输入,经过算法层层抽象将原始数据逐层抽象为自身任务所需的最终特征表示,最后以特征到任务目标的映射作为结束,从原始数据到最终任务目标,“一气呵成”并无夹杂任何人为操作。卷积神经网络定义了一个非常强大的分类模型,但仍然受限于缺乏在计算和参数效率上对输入数据空间不变性的能力[14]。
2016年,Google Deepmind的Max Jaderberg、Karen Simonyan、Andrew Zisserman和Koray Kavukcuoglu提出使用空间变换网络模型来处理图形扭曲变形的各种变换,旨在提升卷积神经网络在计算和参数方面的空间恒定性。普通的卷积神经网络能够显式地学习平移不变性,以及隐式地学习旋转不变性,但是根据监督模型,与让网络隐式地学习到某种能力相比较,为网络设计一个显示的处理模块,专门处理以上的各种变换,图像识别的准确性和效率会得到提升。空间变换网络模型的实现,完成了这样的任务[1-3]。
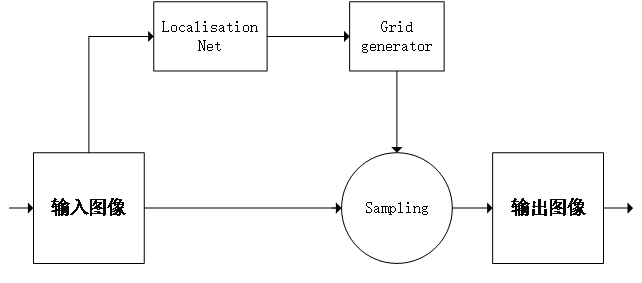
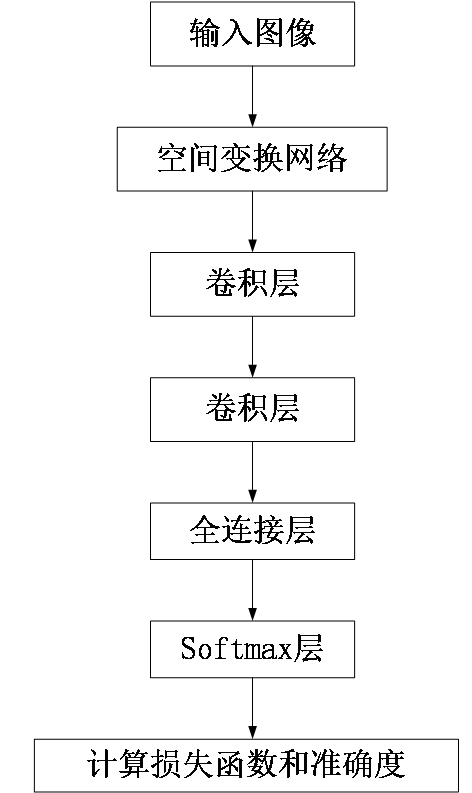
针对图像识别中出现的图形扭曲变形现象,可以将空间变换网络嵌入到深度学习网络(主要是卷积神经网络CNN)中,然后通过模型训练得到合适的模型参数,最后完成整个模型的调试,使之能够自动的进行图像矫正变换并得到对应的标签信息,避免了直接将数据“硬塞”给深度学习网络,能够有效提高训练的准确性和效率。
1.3论文主要工作以及内容安排
全文一共分为5章,各章的研究内容如下:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: