基于卷积神经网络的文本情感分析毕业论文
2020-04-09 15:31:38
摘 要
随着互联网的兴起与发展,依托网络而产生的短文本成为现下主流的文本载体形式。基于短文本的文本情感分析可以在商品评价,网络舆情监控等多方面任务中发挥作用。由于现阶段信息爆炸式增长,继续使用人工分析的手段已无法满足研究人员在自然语言处理上的需求,基于深度学习的方法则以其便利性,高效性,普适性而成为时下主流研究手段。
卷积神经网络作为目前深度学习研究中一种热门架构,在图像处理与文本分析中均有着不俗的表现。本文利用Tensorflow进行卷积神经网络的搭建,通过修改词向量的维度,设置与卷积核有关的参数以及调整正则化参数的取值,对所得模型不断完善修改,使之完成情感判别任务时的性能最优。
利用NLPCC2014评测任务数据集进行训练与测试,在不断调整参数的取值后,本文习得的模型架构能较准确地完成情感极性分类的任务,达到预期实验目标。
关键词:词向量,卷积神经网络,情感极性判别
Abstract
With the rise and development of the Internet, the short texts have become the main form of text in current. The task of emotion analysis based on short texts can play a vital role in different area, such as the appraisal of products, surveillance of internet and so on. Because of the increasing of information, using manual analysis can no longer meet the needs of researchers in natural language processing. The method based on deep learning has become more important because of its convenience, high efficiency, and universality.
Convolutional neural network, as a popular architecture in current deep learning research, has a good performance in image processing and text analysis. I use Tensorflow to build a convolutional neural network in this design. By modifying the dimension of the word vector, setting parameters related to the convolution kernel and adjusting the value of the regularization parameter, the model to deal with the emotional discrimination task has optimal performance.
According to the data set of NLPCC2014, after adjusting the selection of parameters, the model in this article complete the task of classifying emotional polarity well and reaches the desired experimental goal.
Keywords : word vector , convolutional neural network ,classification of emotional polarity
目录
摘要 1
Abstract 2
第一章 绪论 1
1.1研究背景及意义 1
1.2 国内外研究现状 1
1.3课题研究内容 2
1.4 本文的组织结构 3
第二章 卷积神经网络的结构原理 4
2.1 词向量 4
2.2 卷积神经网络的结构组成 7
2.3 本章小结 9
第三章 实验数据预处理 10
3.1 训练文本预处理 10
3.2 实验模型的评价标准 11
3.3 实验参数设置 11
3.4 本章小结 12
第四章 卷积神经网络在情感分析上的具体应用 13
4.1词向量维度的选定 13
4.2滑动窗口的确定 14
4.3滑动窗数量的确定 16
4.4 dropout算法比例的设定 17
4.5 L2正则项参数的选定 18
4.6 验证集的设置 20
4.4 本章小结 20
第五章 实验总结与展望 21
参考文献 22
致谢 23
第一章 绪论
1.1研究背景及意义
时下,互联网与智能终端正处于迅速发展的阶段,人们获取信息的途径变得十分广泛。形如淘宝,京东之类的电商平台,以及以微博,微信为代表的社交软件,作为时代孕育的产物,在人们日常生活中扮演着举足轻重的角色。人们通过在商务平台上进行交流,评论,及时反馈使用信息,方便其他人对商品进行评估,决定是否购买。而网络社交平台作为群众实时交流的媒介,既为大家提供了一个畅所欲言,发表自己见解的平台,也方便政府及时了解社会舆情,搜集民众对某些社会现象以及突发事件的看法。上述种种现象都表明,互联网文本作为时下一种主要的交流方式,越来越受到普通民众的青睐,具有科学研究价值与社会生产的实用研究价值。而对有关研究人员来说,面对信息的爆炸式增长,如何从这类短文本信息中提取有用信息进行相关自然语言处理,从而得到形如情感极性,情感强度等一系列主观特征,便于决策者下阶段的规划,成为现阶段研究的重要课题。为了规范起见,有关人员将这种研究操作定义为文本情感分析,亦或称之为意见挖掘。
1.2 国内外研究现状
目前常使用的文本情感分析手段主要分为两类:一种是利用情感词典进行判别的方法,一种则是利用机器学习的方法进行判断。前者是根据人工修订的情感词典,通过其中记录的词组或者短语,得到情感倾向,从而完成极性的分类。虽然这是一种最直接有效的方法,但由于其分类结果很大程度上取决于情感词典的完备程度,因此在使用中有一定的局限性。而近年来,随着有关理论不断被完善,机器学习成为了时下最热门的研究话题之一。它的工作原理可以概括为,通过对训练语料进行学习,在分析中得出一定的规律,利用所得结果完成文本感情色彩的分类等几个步骤。后者相对于前者来说,使用范围更广,具有更强的泛化性,故而,时下越来越多的研究课题围绕着机器学习的方法进行展开与研究。
现下,研究人员在利用机器学习的手段完成文本情感分析的大框架下,通过将使用方法不断细化,提出了许多架构不同的模型用以完成相关课题的研究。形如朴素贝叶斯算法,支持向量机算法以及最大熵算法等等,都是较为经典的机器学习模型。Pang等人率先将机器学习的有关理念引入情感问题的分析中,利用电影评论数据集,结合词袋模型对三种方法的分类效果进行评判[1]。Wang等人则将朴素贝叶斯与支持向量机算法相结合,根据两种模型的特点,提出了名为NBSVM的综合模型进行语料的训练[2]。为了更有效地研究网络语言文本,Liu等人通过搜集网络流行语以及用于表达情感倾向的网络符号,将之作为文本的特征之一进行提取,以微博短文本作为训练与测试语料,实现了短文本的情感极性判别[3]。
随着神经网络的兴起,与之有关的分析课题也越来越丰富。例如,Socher等人通过递归神经网络的使用,配合语句的组成结构,使得系统能够学习与处理长度不等的句子[4]。再如,Kim选用卷积神经网络,通过对语句进行建模,达到完成情感判别的目的[5]。又如,Kalchbrenner等人对传统卷积神经网络进行修改,在前者的基础上归纳出动态卷积神经网络模型,该模型能够针对不同长度的输入语句生成对应的特征图,在高层滤波器中对低层局部信息进行整合,从而归纳出完整的全局信息,能对整个句子的词序特征进行有效地学习[6]。卷积神经网络与循环神经网络作为时下较为热门的两种深度学习模型,正被越来越多的学者应用在自然语言的处理上。
1.3课题研究内容
本次课题设计,主要围绕着如何将文本进行转换达到后期网络训练的输入要求,以及如何搭建卷积神经网络两个问题展开。根据上述问题,可以将本次的工作内容划分为下述四个部分:
第一,完成训练语料与测试语料的预处理。由于获得的公开数据集不一定满足后续实验的要求,因而需要对文本语料进行一定的处理,用修整好的语料完成后续实验的相关操作。
第二,完成预处理文本中的的词语数值化操作。将文本形式的词语转换成词向量的形式,进一步进行实验,便于计算机的处理与运算。利用词向量对语料进行重构,通过对词向量进行特征信息的提取,完成神经网络对文本数据的学习。
第三,完成卷积神经网络的搭建。利用Tensorflow进行卷积神经网络的编写,实现卷积神经网络的工作机制以及代价函数与评价函数的生成。
第四,完成神经网络参数的调试。通过搭建好的神经网络对语料进行训练,用测试集对学习结果进行检测,在反复训练的过程中,选取最优的参数完成架构的选定。上述四项内容完成后,所得的中文文本情感分类模型当是相同输入条件下学习效果最好的网络架构。
1.4 本文的组织结构
本文一共包含五个章节,按照如下的行文顺序进行文章的编写。
第一章为绪论部分,详细介绍了文本情感分析的研究背景与意义,描述了国内外在该课题上的研究现状,阐述了本次研究设计内容以及预期达到的目标。
第二章为原理介绍部分,分别介绍了词向量和卷积神经网络两种模型的工作原理,以及本次实验选择部分结构的原因。
第三章为数据预处理部分,涵盖了文本预处理与评价标准。介绍了实验在准备过程中具体完成了哪些工作,以及如何评价卷积神经网络的学习结果好坏。
第四章为卷积神经网络的具体应用部分,通过对参数的选取进行说明,介绍了如何将卷积神经网络科学地应用在文本情感分析的处理中。
第五章为实验总结部分,通过对实验结果进行整合分析,评估所得模型的效果好坏,以及对本实验中尚还存在的问题进行说明,提出日后学习的研究方向。
第二章 卷积神经网络的结构原理
2.1 词向量
使用机器学习完成自然语言处理的任务时,首要问题便是考虑如何将文本语言数学化。词向量作为数值化的一种方法,顾名思义便是用向量的形式对词语进行表述。传统词向量采用one- hot的编码形式,从文本中提取N个不重复的词语组成词典,将词典中每一个词语映射成由0,1组成的,大小为N的词向量。这种方式生成的词向量,仅有一处值为1,其余位置处的值均为0。虽然该种方式产生词向量的原理简单,但是在后续的实验使用中,很容易造成维度灾难,同时也无法表示两个含义相近的词语在词向量组成上的相似特征。为了解决传统独热式编码引入的问题,Bengio等人于2003年利用三层神经网络对语料进行训练,利用获得的权重矩阵进行词向量的表述[7],将Hinton于1988年提出的利用Distributed Representation的方法进行词向量描述的有关概念付之实践[8]。利用这种方法训练得到的词向量,不仅可以将词语映射到维度较低的向量上,避免引入维度灾难带来的不良影响,同时也可以根据空间中两点之间的距离衡量两个词的相似程度。区别于one-hot的离散表示方法,这种用定长连续的稠密向量表示词向量的方法便是分布式词向量的原理特点 。
基于分布式词向量的相关理念,谷歌公司的Mikolov等人对模型进行优化,简化了模型参数,缩短了训练时间,于word2vec中成功实现了两种词向量的训练模型,CBOW与skip-gram模型[9]。两种模型的原理相似,前者是结合上下文对中心词为指定词出现的概率进行预测,而后者则是利用中心词预测两边词语出现的概率大小。下面,我将通过skip-gram模型的组成结构,对两种架构的工作原理进行解释与说明。
如下图2.1所示,为skip-gram的原理结构示意图。skip-gram模型作为一种浅层的神经网络,其内部仅包含一个隐藏层来处理中心词预测上下文输出概率的任务。然而,经过学习训练得到解决问题的模型后,我们并不关心实验所得结果,真正有用的模型信息是在学习过程中隐藏层习得的权重矩阵,这些权重便构成了我们实际需要的词向量。因此,词向量作为神经网络概率模型的中间产物,是在习得语言模型的过程中产生的。
具体来说,我们使用语句中一个特定的单词W(t)作为神经网络的输入,按照窗口值的大小,预测随机取到附近单词的概率。所谓窗口值是指,在中心词一侧选取单词的个数。
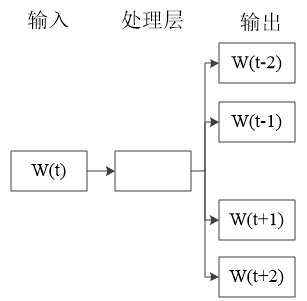 图2.1 skip-gram原理示意图
图2.1 skip-gram原理示意图
 在图2.1中,窗口值的大小为2,意味着需要取中心词前面两个词语W(t-2),W(t-1)以及中心词之后两个词语W(t 1),W(t 2)总共四个词语进行预测。将成对的词组作为神经网络的输入,训练完成后,得到的输出结果是一个概率分布,表示的含义为该词典中的词语作为输入单词的邻近词的概率大小。
在图2.1中,窗口值的大小为2,意味着需要取中心词前面两个词语W(t-2),W(t-1)以及中心词之后两个词语W(t 1),W(t 2)总共四个词语进行预测。将成对的词组作为神经网络的输入,训练完成后,得到的输出结果是一个概率分布,表示的含义为该词典中的词语作为输入单词的邻近词的概率大小。
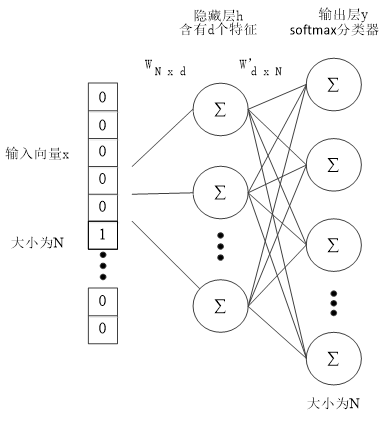
图2.2 skip-gram结构示意图
如图2.2所示,表示的是skip-gram的网络结构图。从文本中抽取N个不重复的词语组成词典,采用one-hot的编码形式,每次向网络中输入一个大小为N的向量,网络经过学习处理,输出一个同样大小的向量作为结果,用来存放词典中每个词语在该词附近的概率。隐藏层里含有d个特征用来提取输入向量的特征信息,d的取值同实际所需的词向量维度大小有关。根据结构图,我们不难发现,由于输入采用one-hot编码,因而隐藏层里没有使用激活函数进行处理。将输入层向量进行加权求和,结合独热式编码的特点,对于隐藏层里的节点h来说,实际作为节点输入,对隐藏层产生影响的是输入向量x里的非零元素。假设向量x中第k行元素不为0,那么隐藏层的输出结果只会同权重矩阵W里的第k行有关联,即如公式2.1所示:
(式2.1)
经过隐藏层的降维处理后,高维的词向量被映射到一个低维向量上。为了将输出向量的维度重新变为词典大小,在隐藏层与输出层之间还包含一个其他单词矩阵进行维度的变换。转换完成后,向量的每一个维度都代表着词典中的其他词语作为目标词语临近词的概率取值。而在输出层里,经过softmax回归分类器的作用,对先前所得的概率分布进行归一化处理,提高使用梯度下降法求得最优解的运算速度。具体来说,softmax分类器的作用是用来计算在给定中心词的情况下每一个窗口中的上下文单词出现的条件概率,如公式2.2所示:
(式2.2)
式子中的表示的是中心词的词向量,表示的是出现在当前词上下文处的词向量。整个神经网络进行优化的目标函数如公式2.3所示:
(式2.3)
式子中代表中心词,代表位于[-k,k]的窗口中出现的上下文单词。通过寻求最大似然函数的最优解,实现在给定中心词的情况下,上下文单词输出概率的最大化。
CBOW模型和skip-gram模型的原理类似,便不再赘述。两种模型各有优缺点,比如前者相对于后者而言,处理速度更快。这是由于CBOW模型仅需对输入进行取值平均并对输出结果进行一次预测,而后者则会随着窗口值取值的增大,不断增加处理过程的复杂程度,因此在处理大型语料上,前者能更快获得结果。但是在处理结果的精确程度与处理生僻词的问题上,skip-gram模型的性能则明显优于前者。由于本次实验进行的时间较长,对训练时间长短并无要求,因此为了追求训练的模型更加精确,利于后续实验的继续进行,本次实验最终选定skip-gram模型用于词向量的学习训练与表示生成。
2.2 卷积神经网络的结构组成
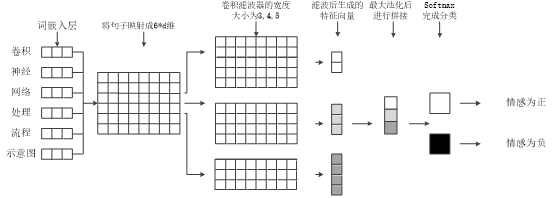 卷积神经网络,简称CNN,是一种典型的深度学习结构,近年来由于相关研究的不断完善,被广泛应用于不同领域的研究中,属于前馈性神经网络的一种。它主要由以下四个部分组成,分别是输入层,卷积层,池化层,以及全连接层。在本次实验设计中,卷积神经网络的处理过程可简化为如图2.3所示:
卷积神经网络,简称CNN,是一种典型的深度学习结构,近年来由于相关研究的不断完善,被广泛应用于不同领域的研究中,属于前馈性神经网络的一种。它主要由以下四个部分组成,分别是输入层,卷积层,池化层,以及全连接层。在本次实验设计中,卷积神经网络的处理过程可简化为如图2.3所示:
图2.3 卷积神经网络处理流程示意图
利用事先训练好的d维词向量模型,将输入到神经网络的待处理文本以单词为单位进行词向量的转换。假设一条语句里包含的单词个数为l,那么经过映射得到的句子矩阵M其大小为。完成词向量的输入后,紧接着进行卷积层的相关处理。卷积层作为卷积神经网络区别于其他网络模型的最重要以及最根本的特征,在CNN语言模型的学习过程中享有非常重要的地位。通过后续实验完成卷积滤波器参数的优化,本实验最终选定以词向量维度作为滤波器的长,以3,4,5三种尺寸作为滤波器的宽,利用三类宽度不同的滤波器对语句矩阵M进行并联处理。这种并联结构利用的是Inception模型,其目的是为了提高传统串联型卷积神经网络的运算性能,解决由于参数空间较大而引入的过拟合问题,增加网络的深度,降低模型的复杂程度,使得卷积神经网络拥有更好的适应性。
现假设滑动窗口的大小为,里面对应的元素用w表示,x对应着输入矩阵M中h行元素,使用的激活函数为f,引入的贝叶斯偏置为b,则经过卷积层的处理,产生的特征向量c,其结果如公式2.4所示:
(式2.4)
激活函数是一种非线性函数,它的作用是将神经网络去线性化,使得运算结果更具有普遍性。常用的激活函数有ReLu函数,sigmod函数,tanh函数等等。虽然ReLu函数的表达式简单,但由于其收敛速度较快,便于梯度的求解,因而广泛应用于卷积神经网络中。故在本次实验选用ReLu函数对运算结果进行非线性变换,它的数学表达式详见公式2.5所示:
(式2.5)
卷积层与全连接层之间是池化层,经过池化层的处理,在不改变神经网络深度的情况下,可以将矩阵的长度有效地进行压缩,完成特征向量的降维处理。除此之外,由于减少了参数的数量,池化层还能够缩短神经网络的训练时间,一定程度上防止过拟合情况的出现。常用的池化方法有两种,一种是平均池化法,一种是最大池化法。前者通过计算一定区域内特征值的平均取值作为最后池化操作的结果,传递给接下来的全连接层进行运算。后者则是选取该区域内数值最大的特征值代表池化所得产物,用以完成后续的实验处理。由于在情感极性判别的过程中,对于词语所处位置并没有太高要求,且在先前的卷积运算中引入并联卷积核的结构,这会导致特征向量出现维数不等的问题,因此本次实验选择最大池化法进行相关处理,提取区域内最关键的局部特征,解决特征向量维数不统一的难题。假设经过卷积处理产生的特征图为C,那么最大池化则可用公式2.6进行描述。
(式2.6)



