基于深度神经网络的语音识别系统设计毕业论文
2020-02-17 23:18:17
摘 要
语音是人类社会数千年来发展的特有的交流工具,是人与人之间表达、传播思想的重要途径,在人类文明中具有举足轻重的地位。而在大数据时代,语音数据也呈现爆炸性增长,人们产生了让计算机“听懂”人类语音,充分利用语音数据,最终反哺人类社会的设想。
近年来,随着深度学习的极大发展,众多研究聚焦在深度神经网络的语音识别领域应用,其强大的非线性拟合和复杂建构特性已经使得传统语音识别方法无法解决的复杂语音场景问题得到了极大的突破。
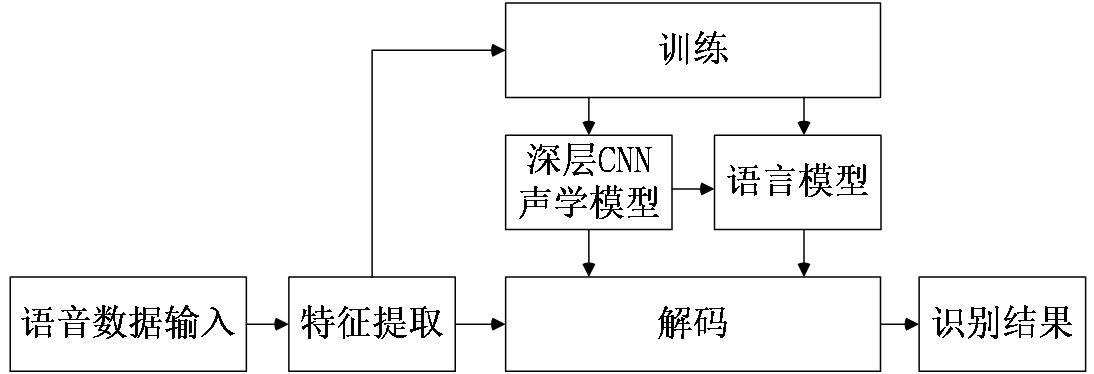
本文聚焦于深度学习和语音识别研究领域的前沿,基于深度神经网络、CTC解码方案、隐马尔科夫链实现了一种基于深度卷积神经网络的语音识别方法。另外,我们基于该方法,从软件工程的角度实现了深度神经网络的语音识别系统。
关键词:深度学习;语音识别;系统
ABSTRACT
Speech is a unique communication tool developed by human society for thousands of years. It is an important way to express and spread ideas among people and plays a pivotal role in human civilization. In the era of big data, voice data has also exploded, and people have created the idea of letting computers "understand" human speech, make full use of voice data, and ultimately feed back human society.
In recent years, with the great development of deep learning, many studies have focused on the application of speech recognition with deep neural networks. Its powerful nonlinear fitting and complex construction features have made the complex speech scene problems that traditional speech recognition methods cannot solve a great breakthrough.
This paper focuses on the frontiers of deep learning and speech recognition research. Based on deep neural network, CTC decoding scheme and hidden Markov chain, a speech recognition method based on deep convolutional neural network is implemented. In addition, based on this method, we realized the speech recognition system of deep neural network from the perspective of software engineering.
Key Words: deep learning; speech recognition; system
目 录
第1章 绪论 1
1.1 研究背景和目标 1
1.2 国内外研究现状 1
1.3 本文主要工作 2
1.4 本文的结构安排 2
第2章 相关技术介绍 3
2.1 特征提取方法 3
2.1.1 傅里叶变换 3
2.1.2 短时傅里叶变换 4
2.1.3梅尔倒谱系数MFCC特征 4
2.2 CTC解码方法 5
2.3 本章小结 6
第3章 深度卷积神经网络的语音识别方法 7
3.1深度卷积神经网络介绍 7
3.2深度卷积神经网络的语音识别框架 8
3.2声学模型 9
3.3语言模型 10
3.4 本章小结 11
第4章 基于深度神经网络的语音识别系统的实现 12
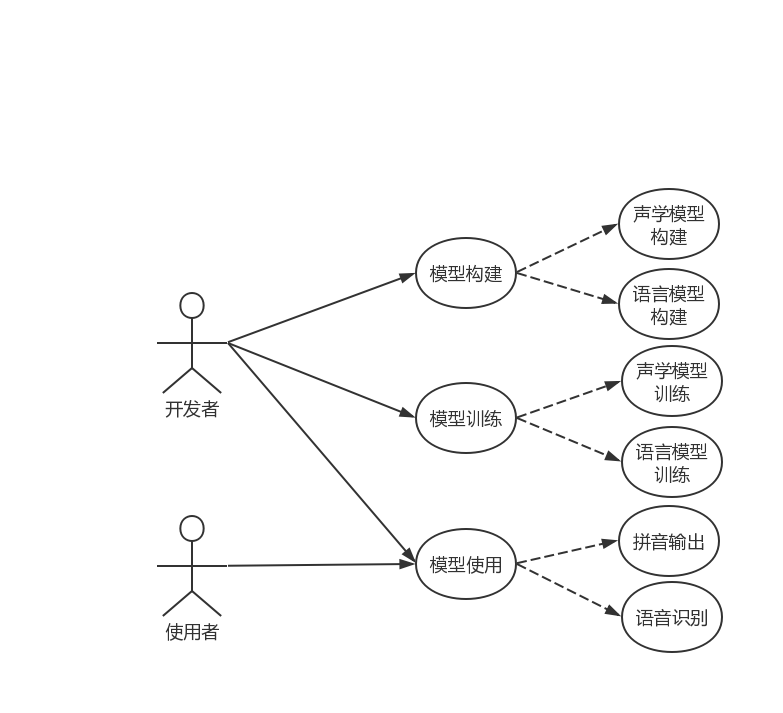
4.1 需求分析 12
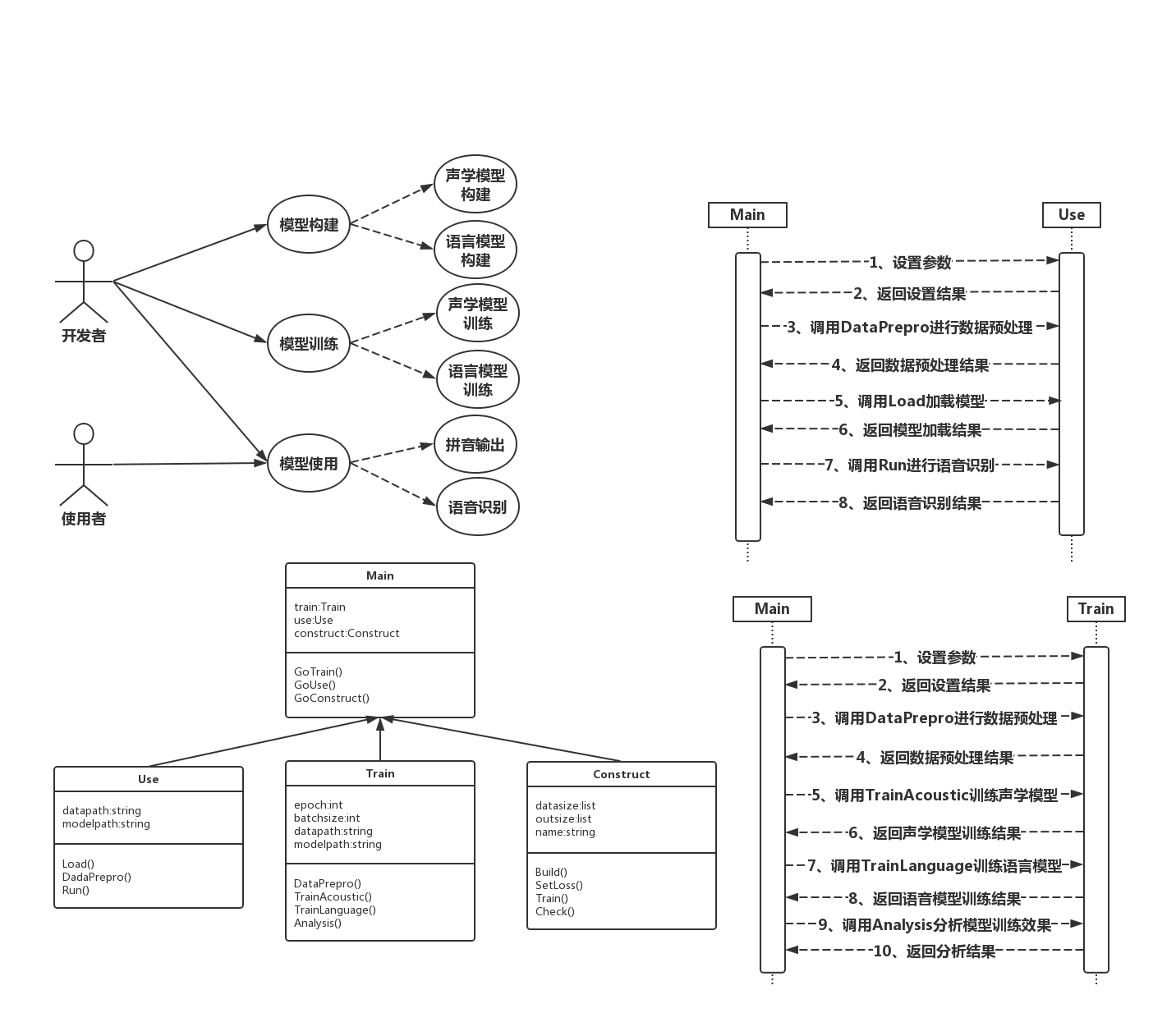
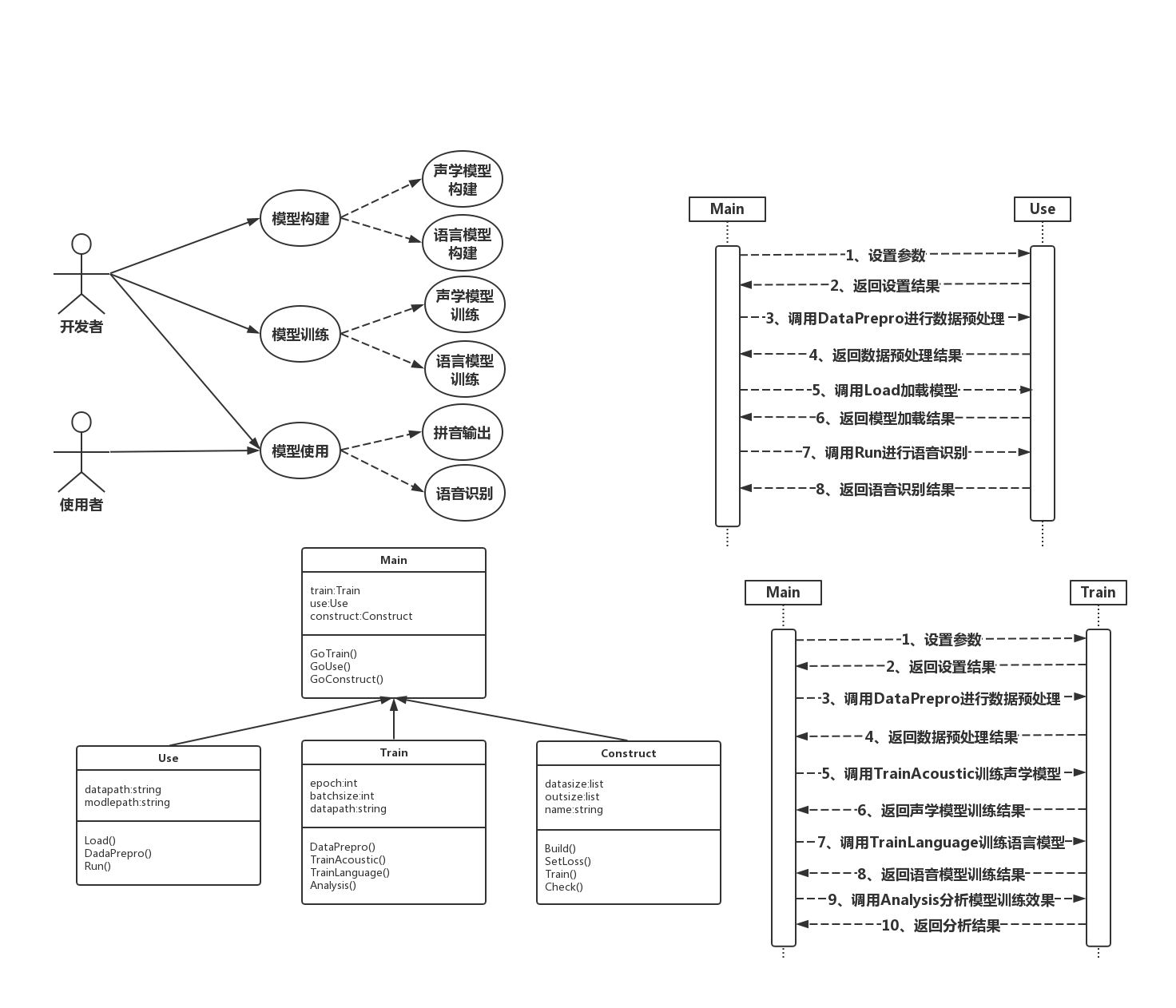
4.2概要设计 13
4.2.1系统类图 13
4.2.2时序图 14
4.3详细设计 15
4.3.1主类模块Main 16
4.3.2模型构建模块Construct 16
4.3.3模型使用模块Use 19
4.3.4模型训练模块Train 22
4.4最终设计结果 25
4.5开发工具和平台 26
4.6 本章小结 27
第5章 总结与期望 28
5.1本文的研究工作总结 28
5.2未来的研究工作展望 28
参考文献 30
致 谢 32
绪论
1.1 研究背景和目标
语言是人类在独有的沟通方法,也构成了人类社会文明交流的纽带,而语音作为传递情感和思想的重要媒介,自然也是计算机科学界的热门研究对象。
语音识别即语音、幅频、文字之间的转换过程,在现代生活中,语音识别系统正在一步步融入现代人的生活中,交通、通信、家居生活都可以看到语音识别的身影,当我们使用智能手机时,可以在不触碰屏幕的情况下,打开任何一项app应用程序;当我们开车时也可以在双手不离开方向盘的情况下,调节车内温度,切换背景音乐;当我们回到家里时,智能音箱、空调、电视、投影仪这些都可以通过语音命令进行控制。语音识别早已不是人类的理想,它已经进入到我们的生活中,为我们带来便捷,为人类带来幸福感。
近年来,人类社会已经步入了云计算时代、大数据时代,随着数据量的海量激增,基于数据驱动的人工智能已经在众多热门领域取得了广泛应用,如医疗、辅助驾驶、遥感等领域。而对于语音数据处理领域的应用,更是极大的便捷了人们的生活,如家电语音助手、导航系统等等。
目前,深度神经网络已经得到了极大的发展,从最简单的全连接神经网络、卷积神经网络、循环神经网络逐步发展为具有层次更深、域度更广的复杂神经网络,如以LeNet和GoogLeNet为代表的深度卷积神经网络、以GRU和LSTM为代表的深度循环神经网络。区别于传统的语音处理方法,如何将深度神经网络更好地应用于语音识别领域,使其具有更好的语音识别和理解正确率已经成为当前一大热门研究问题。语音识别系统在不同场合中需要不断提高本身性能,而且需要在保证性能的前提下做到经济合理,深度神经网络复杂度较高,模型复杂,一般需要较高的硬件配置。
因此,本文将基于国内外的最新研究成果,实现一种深度卷积神经网络的语音识别方法,并基于该方法设计实现为一个友好的语音识别系统。
1.2 国内外研究现状
语音识别技术在过去的十年里产生了巨大的突破,平均两年字错误率下降50%。与此同时基础技术也取得了重大的进展,从而降低了说话人独立语音,连续语音及大词汇量语音识别的障碍。有几个因素促成了这种迅速的进展。 First, there is the coming of age of the HMM.首先,HMM时代即将到来。HMM is powerful in that, with the availability of training data, the parameters of the model can be trained automatically to give optimal performance. HMM模型规模强大,以及具有有效地训练数据,可以自动训练出模型的最佳的性能。
作为成熟的语音处理技术,GMM-HMM声学模型已经在语音识别领域得到了广泛的应用,如王为凯[1]利用GMM-HMM声学模型、Bigram模型和梅尔倒谱系数MFCC特征实现了语音识别系统,并在公开数据集WSJ0和Nov92上取得不错的效果。
然而,高斯混合模型(Gaussian Mixture Model,简称GMM)仍然只是一个浅层的模型,面对复杂的声音数据,如吵杂环境下的声音数据,难以通过GMM构建一个适合的模型来描述,以至于识别效率和成功率不如人意。
近年来,深度神经网络蓬勃发展,其非线性化的复杂建构能力已经得到了广泛认同,并已经成功应用到了语音识别领域,如戴礼荣[2]详细介绍了深度学习在语音处理方面的应用;刘旺玉[3]结合GMM-HMM和深层循环神经网络提出了集去噪和识别一体的混合模型,成功实现了工厂实时环境下的语音识别;张仕良[4]从语音识别和深度学习的框架出发,提出了多种基于全连接神经网络DNN的语音识别模型,并将固定长度依次遗忘编码(Fixed-size Ordinally Forgetting Encoding,FOFE)方法用于神经网络的建模过程,另外还提出了一种基于循环神经网络的前馈序列记忆神将网络(Feedforward Sequential Memory Network,FSMN)和联合优化正交投影和估计(Hybid Orthogonal Projection and Estimation,HOPE)的建模方法;张德良[5]采用多种特征工程对DNN-HMM声学模型进行研究,并成功在Kaldi平台上使用GPU训练网络;王山海[6]引入贪婪预训练算法,并辅以微调操作,成功提高了深度学习语音识别的准确率;屈丹[7]提出了一种基于本征子说话人子空间的说话人自适应算法,该算法更具实用性。
1.3 本文主要工作
本文的主要工作如下:
- 借鉴深度神经网络、CTC解码方法、隐含马尔可夫模型、统计语言模型,实现一种深度卷积神经网络的语音识别方法;
- 基于实现的语音识别方法,设计实现成语音识别系统。
1.4 本文的结构安排
第一章为绪论,主要介绍了语音识别的概况以及本文的主要工作;
第二章为相关技术介绍,如特征提取方法、编码方法、语言模型;
第三章主要介绍本文实现的深度卷积神经网络语音识别方法;
第四章主要介绍本文基于深度卷积神经网络实现的语音识别系统;
第五章为总结本文所做的工作,并对未来工作作出展望。
相关技术介绍
本章将着重介绍语音识别系统实现的相关技术,如特征提取方法、CTC解码方法等,这是实现本文语音识别系统的重要载体。
2.1 特征提取方法
深度学习的运用需要大量的数据,而语音设备获取到的原始数据是语音信号的时序幅度数据,在二维图象上表现为语音信号的波形图。
然而,原始时序语音信号数据的维度是不足以充分发挥深度学习优势的,需要利用特征提取技术将其转换为计算机更容易识别的数据形式,如利用傅里叶变换和短时傅里叶变化将语音数据从幅度维度转换为频率维度,进而提取梅尔倒谱系数MFCC特征。
2.1.1 傅里叶变换
傅立叶变换(Fourier transform,FT)是一种常用的线性积分变换工具,多用于信号处理领域,以实现信号在时域和频域之间的变换,在工程学和物理学中有广泛的应用。因其变换的基本思想是由法国学者傅里叶首先系统提出的,所以以其名字来命名改转换方法,以作纪念。
一般情况下,若“傅里叶变换”一词没有详细的说明,则默认指的是“连续傅里叶变换”,如下式:
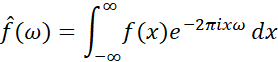
其中自变量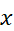 为时间,
为时间,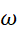 为任意实数以表示频率,
为任意实数以表示频率,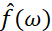 是经过傅里叶变换后的频谱信号,
是经过傅里叶变换后的频谱信号,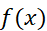 是原时域信号。
是原时域信号。
另外,连续傅里叶逆变换如下式: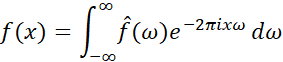
充分利用傅里叶变换,可以将语音数据从时序-幅度维度转换为频率-幅度维度,这样的数据更加适合计算机进行处理。而对于某些领域,如语音还原、语音增强、语音去噪等领域,则需要利用傅里叶逆变换将频率-幅度维度的语音数据转换为原语音数据。
2.1.2 短时傅里叶变换
傅里叶变换可将语音数据从时序-幅度维度转换为频率-幅度维度,虽更适合计算机处理,但时序维度的信息却因此丢失,这并不利于深度神经网络的学习训练,因此需要对傅里叶变换进行“加窗”处理,将语音数据的时序-幅度维度转换为时序-频率-幅度维度,即短时傅里叶变换(Short-Time Fourier Transform,STFT)。
同样的,若“短时傅里叶变换”一词没有详细的说明,则默认指的是“连续短时傅里叶变换”,其原理是将要变换的函数乘上一段不为零的窗函数,并在此范围内进行傅里叶变换,再将此窗函数沿着时间轴不断地正向移动且重复傅里叶变换操作,由此得到一系列的傅里叶变换结果展开后则成为时序-频域的二维表象,如下式:
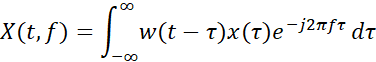
其中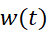 是窗函数,
是窗函数,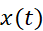 是待变换的原声音数据,
是待变换的原声音数据,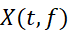 是经过短时傅里叶变换后得到的时序-频域-幅度维数据。
是经过短时傅里叶变换后得到的时序-频域-幅度维数据。
利用短时傅里叶可以将声音数据转换为时序-频域-维度维数据,这与原数据相比,数据的维度较多,更加适合深度神经网络模型的训练,由此训练得出的模型表现效果会更好。
2.1.3梅尔倒谱系数MFCC特征
在声音处理领域中,梅尔频率倒谱(Mel-Frequency Cepstrum)是基于声音频率的非线性梅尔刻度(Mel Scale)的对数能量频谱的线性变换。而梅尔频率倒谱系数 (Mel-Frequency Cepstral Coefficients,MFCCs)就是组成梅尔频率倒谱的系数,是由Davis和Mermelstein在1980年代首次提出的,广泛应用于语音识别等领域。
MFCC的一般过程如图 2‑1。
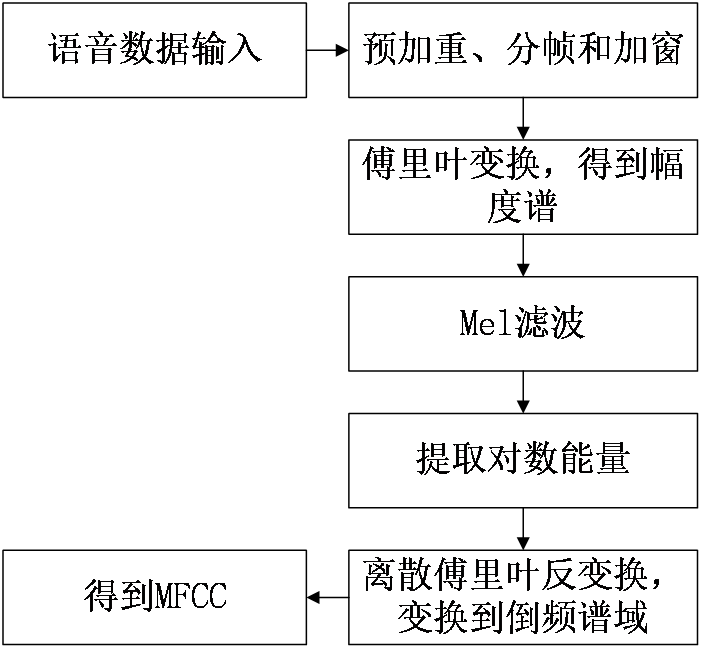
图 2‑1MFCC的一般过程
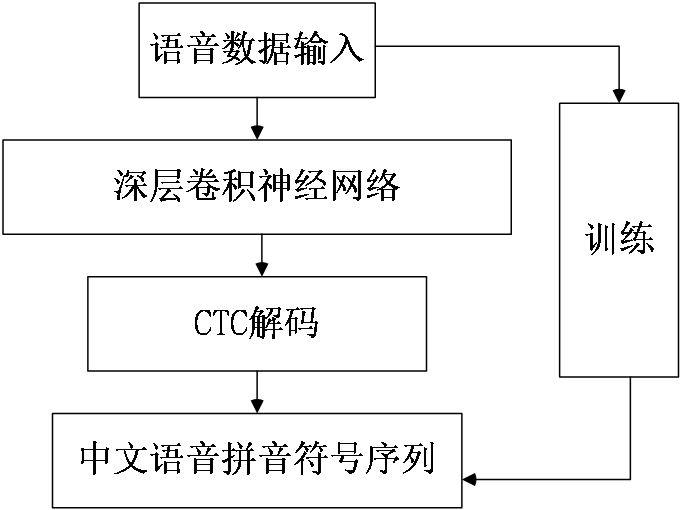
2.2 CTC解码方法
对于语音识别而言,语音的数据是一段不定长的声音数据,而标签则是该段语音对应的不定长文本数据,由于两种数据形式和长度的不同,如何将语音数据片段与文本数据在单词层面上进行对齐操作,便是语音识别任务的一大难题。
连接时序分类器(Connectionist Temporal Classification,CTC)是常用的输入输出对齐方案,常与其他特征提取算法联合使用,如循环神经网络、卷积神经网络。
设输入的声音数据X和输出的文本数据Y如下式:
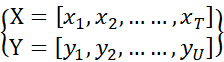
其中T为声音数据的长度,U为标签数据的长度,二者不确定且不一定相等。
连接时序分类器的作用是找到X与Y的映射关系,且对于给定的声音数据X可输出相应的标签数据Y。
而为了,实现精准的输出对齐,与其他方案不同,CTC引入的一个“空白占位符”,通常用字符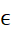 来表示,以表示语音数据中的停顿,如图 2‑2。
来表示,以表示语音数据中的停顿,如图 2‑2。

图 2‑2CTC解码的空白占位符
总的来说,CTC有以下特点:
1、输入数据与输出数据的对齐方式是单调的,即当输入下一个输入数据片段时输出会保持不变或者会移动到下一个字符,而不会回溯到上一个字符;
2、输入与输出是多对一的关系,一个或多个的输入数据只能对齐到一个输出数据;
3、输出数据的长度总是不大于输入数据。
2.3 本章小结
本章主要介绍了本文系统实现所必须的特征提取方法和CTC解码方法,接下来将以这些技术为基础,着重介绍本文的基于深度神经网络的语音识别方法。
深度卷积神经网络的语音识别方法
3.1深度卷积神经网络介绍
1989年,Y.LeCun在首次提出卷积神经网络(Convolutional Neural Networks, CNN),与传统的前馈神经网络相比(如全连接网络),卷积神经网络本质上是属于半连接神经网络,主要由卷积层和池化层构成,因每层主要执行卷积操作而得名。卷积神经网络的最大特点在于“局部感知视野”和“权值共享”,这大大减少了深层网络的参数数量,并提升了网络的训练速度。
卷积神经网络的“局部感知视野”是由“卷积核”实现的,而同一卷积核在数据局部间滑动,每次滑动之后的卷积操作对于同一卷积核而言是相同的,由此实现“权值共享”,如图 3‑1。
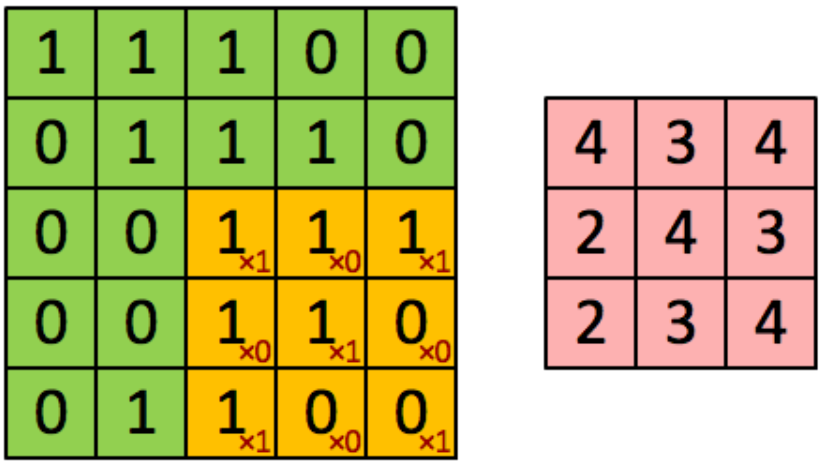
图 3‑1卷积神经网络的“局部感受视野”和“权值共享”
但是,对于复杂的任务,如声音识别、图象识别、动作识别等,在发展前期较为浅层的卷积神经网络的建模表达能力不足以较好地完成这些人物,因此需要构建更深层的卷积神经网络(Deep Convolutional Neural Networks, DCNN),以获取更好的非线性拟合能力和表达能力。
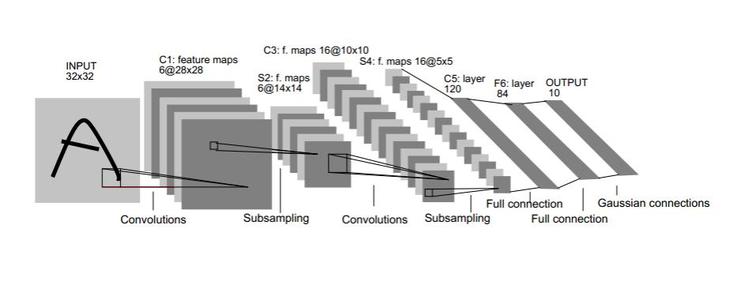
然而,随着卷积神经网络层数的加深,网络很容易会出现梯度消失和梯度爆炸等问题,这是阻碍卷积神经网络往深层发展的重要因素。2012年,Krizhevsky首次提出AlexNet[8],这是在LeNet-5的基础之上改进的,其最突出的贡献是将非线性激活函数ReLu与Dropout[9]方法首次同时应用在卷积神经网络,取得了很好的效果,极大地缓解了梯度消失和梯度爆炸问题,掀起了世界范围内的深层卷积网络研究热潮。之后,研究人员意识到了卷积神经网络的卷积层和池化层仍有不少改进的空间,并陆陆续续地就此提出了多种层数更深、性能更好的深层卷积神经网络,如ZFNet[10]、VGGNet[11]、GoogleNet[12]、ResNet[13]。目前,除语音识别任务之外,深层卷积神经网络已经广泛应用于多个领域,如图像处理[14][15]、自然语言处理[16][17]等领域。
下图展示了深层卷积神经网络的基本架构,可以看到,除基本的卷积层和池化层(包括最大池化和平均池化)之外,为了适应任务的需求,深层卷积神经网络通常最后接上多个全连接层,以规范输出数据的规格。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: