基于聚类的双人混合语音分离方法研究与实现毕业论文
2020-02-17 22:00:48
摘 要
语音分离在生活中应用的很广泛,是语音处理的重要研究方向。本文应用聚类的分析方法设计了一个双人混合语音的分离方案。该方案的实现方法简便、分离成本较低。
论文主要研究了聚类算法在双人混合语音分离的应用。分离方案通过两次聚类实现混合语音的分离,第一次聚类完成对噪声帧和语音帧的区分,第二次聚类完成对不同说话人语音的区分。其中,第二次聚类采用了欧氏距离和相似系数来衡量语音特征的相似性或差异性。此外,论文还对分离方案的分离效果进行了比较。
研究结果表明:聚类算法能够有效地区分噪声和语音;分离方案能有效地分离双人混合语音,且混合语音越长,理论分离效果越好。
关键词:MFCCs;聚类;欧氏距离;相似系数
Abstract
Speech separation is widely used in life and is an important research direction of speech processing. In this paper, a clustering analysis method is used to design a separation scheme for two-person mixed speech. The implementation method of the scheme is simple and the separation cost is low.
The paper mainly studies the application of clustering algorithm in the separation of two-person mixed speech. The separation scheme realizes the separation of mixed speech by two clusters. The first clustering completes the distinction between the noise frame and the speech frame, and the second clustering completes the distinction between the different speaker voices. Among them, the second cluster uses Euclidean distance and similarity coefficient to measure the similarity or difference of speech features. In addition, the paper also compared the separation effects of the separation scheme.
The research results show that the clustering algorithm can effectively distinguish noise and speech; the separation scheme can effectively separate the mixed speech of two people, and the longer the mixed speech, the better the theoretical separation effect.
Key Words: MFCCs; Clustering; Euclidean distance; Similarity coefficient
目 录
第1章 绪论 1
1.1 课题研究背景及意义 1
1.2 国内外研究现状 2
1.3 论文的研究内容及组织结构 3
1.3.1 研究内容概述 3
1.3.2 论文组织结构 3
第2章 基础技术及原理 4
2.1 语音特征分析及前期处理 4
2.1.1 噪声和语音信号的特征 4
2.1.2 语音信号的前期处理 4
2.2 常用的聚类算法 5
2.3 MFCCs与特征提取 8
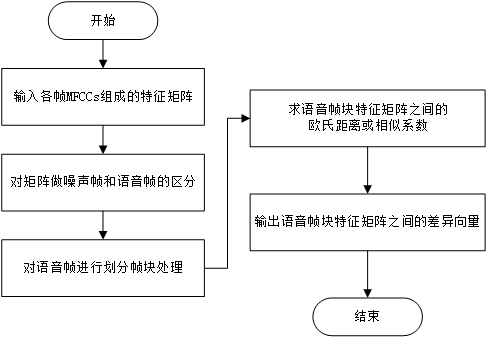
第3章 语音分离方案设计与实现 11
3.1 语音分离思路分析 11
3.2 语音分离方案设计 11
3.3 分离方案的具体实现 12
3.3.1 音频文件的读取与前期处理 12
3.3.2 Mel滤波器参数的设定并求取MFCCs 13
3.3.3 MFCCs相似程度的刻画 15
3.3.4 对刻画结果进行聚类分析 18
3.3.5 根据聚类结果重组语音信号 18
3.4 双人混合语音分离结果的比较 19
3.4.1 相同时长不同实现方式的比较结果 20
3.4.2 不同时长相同实现方式的比较结果 20
3.5 方案的不足与分析 21
第4章 总结与展望 22
4.1 本文工作总结 22
4.2 下一步的工作展望 22
参考文献 23
致 谢 24
第1章 绪论
1.1 课题研究背景及意义
语音是人们交流的重要载体之一,是获取信息的主要途径。随着社会的发展,生活中需要用到语音处理的场景越来越多,如平常的交谈、媒体的采访、企业的会议、机密场所的入门许可、罪犯的监听与鉴别等都是语音处理的高频场景,在金融、信息服务和军事等领域则更是应用广泛。近年来,语音信号处理得到了飞速发展,基本上满足了各种场景的需求。语音信号处理涉及到音频的录制、音频的编解码、语音分离、语音识别、语音增强和语音合成等多方面技术,而语音分离作为语音识别和语音合成的重要基础,在语音信号处理中始终占据着重要位置。因此,语音分离技术得到了广泛深入的研究,各种语音分离技术也越来越成熟。
语音分离问题起源于“鸡尾酒会效应(Cocktail Party Effect)”,它指出人拥有一种听力选择能力,在某种情况下,人类能够将注意力集中在某个人的谈话中而忽略其他人的谈话[1]。这个现象被提出后引起了相关语音研究人员的重视,语音分离的研究就此开始,相关的语音分离技术也不断地涌现出来。早在20世纪90年代,研究人员就发现人类的听觉心理和生理模型可以很好地应用在语音分离的问题上,但如何在计算机上构建这个听觉模型却是个相当棘手的问题。尽管如此,经过多年的研究与实践,还是有很多优秀的语音分离方法得到大家的认可,大致可以分为基于ICA(Independent Component Analysis,独立成分分析)的语音分离方法、基于CASA(Computational Auditory Scene Analysis,计算听觉场景分析)的语音分离方法和基于SF(Spatial Filtering,空间滤波)的语音分离方法[2][3]。
近年来,机器学习和深度学习得到长足的发展,里面涉及的很多数据处理方法也被运用到语音处理方面,聚类分析就是其中之一。聚类分析(Cluster Analysis)是一种数据分析技术,它把具有相似属性的一些数据成员聚合在一起,划分在同一类别里,属于无监督学习。聚类常用在数据挖掘、模式识别等多个领域中,在语音处理方面也有相当成熟的应用,比如语音识别等。聚类分析作为一种非监督式学习,衍生出了很多种聚类算法,其中比较实用的聚类算法有K-Means、均值偏移、DBSCAN、EM聚类、层次聚类等。这些聚类算法以其聚类方式或聚类目的划分,通常用于不同的数据处理场景。在实际数据处理中,需要根据数据特征和聚类目的等来选择合适的聚类算法,以达到最佳处理效果。
传统的语音分离实际上是一个比较宽泛的说法,根据分离目的的不同,语音分离可以分为三类:从噪声信号中分离出说话人的语音,可以称为“语音增强”;从其他说话人中分离出目标说话人的语音,可以称为“多说话人分离”;从目标说话人的声音反射波中分离出目标说话人的语音,可以称为“解混响”。本文研究的是双人混合语音的分离,属于多说话人的分离。在语音识别的前端加上语音分离模块,把多个说话人的语音分开就可以提高语音识别的准确性,这也成为现代语音处理系统重要的一环。随着分离技术的不断发展,多说话人分离技术也日臻成熟,已广泛应用于媒体采访、会议录音等多种场合。本文研究的基于聚类的双人混合语音的分离,是从聚类算法的角度,以较低的分离成本和分离条件,实现一种简易轻便的软件分离方法。该分离方法的实现,将提供另一种多说话人分离方式,给相关的应用场合提供更多的选择,也将推动多说话人分离方法的发展。
1.2 国内外研究现状
多说话人分离的研究始于20世纪30年代,当时的研究热潮主要是说话人识别的研究,多说话人分离也是基于说话人识别的研究而实现的。说话人识别有别于语音识别,前者关注的是包含在语音信号中的个人声音特征,后者着眼于提取语音的语义内容信息,而多说话人分离正是基于语音中的个人声音特征之间的差别实现的多个说话人语音的分离。因此,多说话人分离很大程度上依赖于说话人识别的相关研究,特别是语音中各个说话人声音的特征提取,以及特征之间差异性的增强。
早期的说话人识别研究主要处在人耳听音的阶段,随着研究工具和研究方法的改进,相关研究开始使用先进的计算机作为研究工具。Bell实验室经过相关的研究,先后提出了“声纹”概念与基于模式匹配和概率统计方差分析的说话人识别方法[4][5]。目前,对于说话人声音特征的提取和特征的增强,已经提出了很多技术和方法,主要有动态时间规整(Dynamic Time Warping, DTW)、矢量量化(Vector Quantization VQ)、人工神经网络(Artificial Neural Network, ANN)和隐马尔可夫模型(Hidden Markov Model, HMM)以及一些组合技术[6][7]。这些技术的发展给多说话人分离的实现提供了更多的选择。
有关双人混合语音的分离,已经有很多相关的研究。李锐等人在BIC和G_PLDA的融合方法的研究中指出,充分利用BIC在短时聚类的可靠性和G_PLDA在长时段上的优异区分性,可以降低分类错误率,提升系统的分离性能[8]。基于CASA的双人混合语音的分离也有相关的研究,在此基础上还分析了聚类应用在CASA系统上对语音分离的影响[9]。考虑到单个麦克风在噪声处理、声源定位和跟踪、语音提取和分离等方面存在的不足,相关研究已经将麦克风阵列引入了多说话人分离的系统,使用近场2D_MUSIC算法完成说话人的定位和跟踪,使用近场最小方差波束形成技术(Near-Field Minimum VarianceDistortionless Response Beamforming)完成语音的提取和分离等[10]。基于深度学习的多说话人分离也有相关的研究,王燕南在其研究中提出了一个基于说话人组合检测的说话人独立单通道语音模型系统,该系统在聚类的基础上应用了深度学习的方法完成语音的分离[11]。以上研究或多或少都应用了聚类的分析方法,值得研究和借鉴。
目前,国内外有许多大学和研究机构也在这个领域展开了相关研究,并取得了丰硕的研究成果,如麻省理工林肯实验室、中科院声学所、科大讯飞等。作为中国语音处理方面的领军企业,科大讯飞在语音处理上的技术积累是非常雄厚的,在其官网上推介的一个名为语音转写(Long Form Automatic Speech Recognition)的语音服务,就包含了发音人分离的功能。
1.3 论文的研究内容及组织结构
1.3.1 研究内容概述
本文将研究与实现双人混合语音的分离。双人混合语音分离是指在单声道的情况下,对包含2个说话人语音中的目标语音进行分离。论文将采集或模拟多种环境下的语音数据,使用聚类算法对其分离,并对各语音分离方法的效果进行比较和分析。
据前文所述,语音分离可细分为三类,本文研究的内容属于“多说话人分离”。与其他两类分离不同,多说话人分离主要解决的问题是“某个时刻是谁说的话”。根据有无监督分离,又可以分为有监督分离、半监督分离和无监督分离;根据与文本有无关联,又可以分为与文本无关、与文本有关和文本指定型。本文所研究的基于聚类的双人混合语音的分离,因其聚类分析的无监督性,属于与文本无关的无监督分离。这样的“多说话人分离”常用的分离方法是,根据噪声与语音之间的差异,在时间轴上划分出多个语音帧块,用聚类的方法对这些语音帧块进行处理,将不同说话人的语音帧块分别标记,最后将属于同一个说话人的语音帧块重新组合在一起。本文将大致按照上述分离方法进行研究,在实现方式或方法上会有所差异。
1.3.2 论文组织结构
本文的内容共四章,具体安排如下:
第一章是绪论部分。首先简要介绍了语音分离问题的起源和发展以及聚类分析在语音处理方面的应用;接着阐述了语音分离的细分类别和多说话人分离与说话人识别之间的联系,并在此基础上概述了论文的研究内容;最后是论文的内容安排介绍。
第二章是设计的相关原理。先介绍论文所涉及的一些概念和前人的研究成果以及相应的公式。
第三章是语音分离方案的设计与实现。首先,提出论文的研究思路,然后对整个研究过程给出实现框图,并介绍设计思路和详细的实现过程,最后与其他的语音分离方法的效果进行比较和分析,指出各分离方法的优点和不足。
第四章是总结与展望。对完成的工作进行总结,对分离方法的进一步完善提出改进建议。
第2章 基础技术及原理
2.1 语音特征分析及前期处理
2.1.1 噪声和语音信号的特征
20世纪60年代以来,数字录音产品开始走向商业化,涌现了很多录音设备和录音技术。数字音频的产生,实际上就是模拟信号经由录音设备(如麦克风)采样、量化及编码的转换过程。在录音设备的采样过程中,难以避免将环境当中的干扰声音录制进去,如各类环境音、其他说话人的声音等,录音设备自身的电子噪声也将录制进去,这样得到的数字音频实际上包含了很多种成分。为了进一步的数字音频处理,需要了解音频中各种成分的特征以及特征之间的差异。
通过对大量语音信号的研究发现,从整体上看,语音信号及其特征参数都是随时间变化的,是一个非稳态过程,不能使用处理平稳信号的数字信号处理方法对其进行分析处理。然而,由于人体发声器官的生理特性,发出的语音信号无法在极短的时间内快速变化,因此可以认为语音信号具有短时平稳性。而噪声由于不确定性,通常会表现出不同的信号特征,但从一般而言,噪声具有随机性、低能量性、短时不变性。总体来看,噪声和语音信号主要有以下几个特征:
1)从时域上看,语音信号具有短时平稳性,语音的浊音部分表现出周期性,清音部分表现出随机性;噪声信号则具有短时不变性、整体随机性。
2)从频域上看,语音信号的频谱分量主要集中在300~3400Hz的范围内,而噪声信号没有明确的频率范围。
2.1.2 语音信号的前期处理
为了使后续的语音处理更加顺利和有效,通常会对语音信号做前期处理,一般是预加重处理、分帧和加窗处理。
由于人体发声器官的生理特性,在向外辐射声波的时候,语音信号的高频部分会受到抑制,在求语音信号频谱时,会发现频率越高的分量成分越小,因此需要进行预加重处理。预加重处理的目的是补偿高频分量的损失,使频谱变得平滑。一般用一阶数字滤波器来实现预加重处理,且该过程通常在语音信号数字化之后、特征参数分析之前进行。实现预加重处理的数字滤波器公式如公式2.1所示:
其中μ值介于0.9到1.0之间。
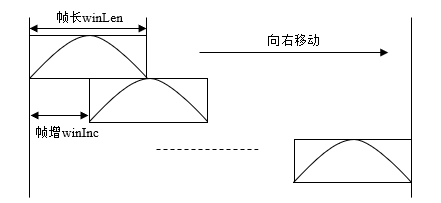
接下来的分帧和加窗处理实际上是合并在一起的操作。根据上文所述,语音信号具有短时平稳性,这个短时一般指10~30ms,在这样短的时间内通常可以认为语音信号是平稳的。这样就可以把语音信号划分成一段一段的语音段来处理,语音段的长度通常在10~30ms之间,把这样划分语音段的处理称为分帧,每秒的帧数约为33~100帧。加窗则是对每一个帧的操作,即每一帧与一个窗函数相乘,以提高帧左右两侧的连续性,简单的加窗操作如图2.1所示:
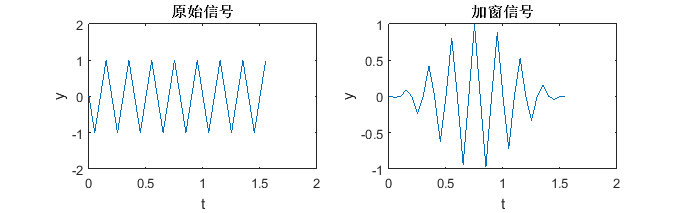
图2.1 加窗示意图
2.2 常用的聚类算法
聚类是一种机器学习的数据分析方法。常用的聚类算法有K-Means、均值偏移、DBSCAN、EM聚类、层次聚类等,对以上5种聚类算法的总结对比如表2.1所示:
表2.1 5种聚类算法的总结对比
K-Means | 均值偏移 | DBSCAN | EM聚类 | 层次聚类 | |
聚类特点 | 基于欧氏距离 | 基于数据点密度 | “找邻居” | 基于概率 | 构建树状图 |
优点 | 速度快 | 符合数据驱动型任务的需要 | 可划分任意形状的聚类 | 聚类形状不局限于圆形 | 适合于具有层次结构的数据 |
缺点 | 初始质心点的选取麻烦 | 难以确定高维数据的球半径r | 难以确定高维数据的邻域半径ε | 计算量大 | 效率较低 |
是否需要指定 | 是 | 否 | 否 | 是 | 均可 |
从表2.1中可以看出,5种聚类算法的特点及优缺点都比较明显且各不相同。下面将详细介绍这5种聚类算法:
(1)K-Means聚类
K-Means聚类或称K均值聚类,是知名度很高的一种聚类算法,常出现在数据分析的课程中。K均值聚类比较容易理解和实现,算法流程框图如图2.2所示:

图2.2 K-Means流程框图
首先,我们要确定聚类的数量,并初始化同等数量的聚类质心点,初始化质心点的过程可以随机,但更好的方式是在输入的数据中合理地选择几个数据点作为质心点;其次,计算每个数据点到质心点的距离,并根据距离的远近进行分类,数据点离哪个质心点近,它就被分到该聚类;接着,更新聚类质心点,即新的质心点应当满足聚类里每个点到它的欧氏距离平方和最小这个条件;最后,判断质心点是否发生改变,若是则重复二三步骤,不断迭代更新聚类质心点,直到聚类质心点相对稳定,若未发生改变则直接输出数据点所属类别序列。
K-Means的优点是速度非常快,因为只需要计算数据点到质心点的欧氏距离,涉及的计算量非常少。但它的缺点也很明显,一是在一开始就要判断出聚类数量K,这一点在数据量很大且不够直观的时候是比较麻烦的;二是初始质心点的选取,随机初始化有可能导致质心点发生震荡,即无法终止迭代。对于初始质心点的选取和震荡的消除,已经有了很多的解决办法。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: