基于强化学习的船舶避碰系统(算法)毕业论文
2020-04-04 10:53:31
摘 要
随着计算机技术的逐渐发展,在海上航行过程中实现自动驾驶和自动避碰成为可能,分析研究船舶自动避碰系统就是一种解决海上船舶碰撞的方法。强化学习作为一种机器学习算法,在很早以前就被人用在汽车的自动驾驶领域,随着数据规模和硬件设备的不断进步,使得深度学习和强化学习方法在许多领域取得了显著的效果,本文旨在研究分析船舶智能驾驶系统来处理海上航行中两船碰撞的问题。相对于陆地上汽车的行驶,海上驾驶有完全不同的避碰规则,需要我们为强化学习设计新的奖励函数和约束规则。
毕业设计使用Ubuntu 16.04平台,利用Director框架,搭建基于强化学习的船舶避碰系统,所搭建的环境基本正确,使用Deep Q Network算法作为强化学习的算法,基于《国际海上避碰规则》规定为强化学习设置奖励函数和约束规则,经过实验可以在海上完成避碰,为船舶决策提供可靠地依据。
毕业设计使用强化学习,完成了海上避碰的算法部分,能让避碰船躲避不同方向不同大小,不同速度的船舶,实验结果表明强化学习适用于海上船舶避碰,并且在一定的范围内可以遵守海上行驶规则。
关键词:强化学习;船舶避碰;Q学习
Abstract
With the gradual development of computer technology, it is possible to realize automatic ship driving and collision avoidance. In order to solve the collision of ships, we need analysis and research the ship automatic collision avoidance system. As a machine learning algorithm, reinforcement learning was used in the auto driving field of automobiles. With the growing data scale and improvement of hardware equipment, deep learning and reinforcement learning methods have achieved remarkable results in many fields. This article aims to study the ship's intelligent driving system to handle the collision of two ships in the sea. Relative to the driving of cars on land, sea driving has completely different rules for collision avoidance, we need to design new reward functions and constraint rules for reinforcement learning.
This thesis passed the Ubuntu 16.04 platform and used the Director framework to build a ship collision avoidance system based on reinforcement learning. The built environment was basically correct. Use Deep Q Network. Based on the International Regulations for Preventing Collisions at Sea, the reward function and constraint rules were set up for reinforcement learning through experiments. Collision avoidance can be accomplished at sea to provide a reliable basis for ship decision-making.
In this thesis, reinforcement learning was used to complete the algorithm for collision avoidance at sea, which allowed the ship to avoid ships of different sizes, speeds and directions. The experimental results show that reinforcement learning is suitable for sea vessels to avoid collisions and obey the rules of the sea within a certain range
Key Words:reinforcement learning;ship collision avoidance;Q learning
目 录
第1章 绪论 1
1.1研究背景 1
1.2 研究目的及意义 1
1.3 国内外研究现状 2
1.3.1 国外研究现状 2
1.3.2 国内研究现状 3
1.4 主要研究内容 3
第2章 基于强化学习的船舶避碰算法设计 5
2.1 强化学习基本原理 5
2.1.1 强化学习概述 5
2.1.2 强化学习的基本要素 6
2.1.3 Q学习算法 6
2.1.4 Deep Q Network算法 7
2.2 避碰情况与影响因子 8
2.2.1 船舶避碰的过程 8
2.2.2 船舶避碰情况分析 9
2.2.3 船舶的避让责任 10
2.2.4避碰危险 11
2.2.5碰撞危险度 11
2.3避碰算法设计 11
2.3.1船舶避碰问题的强化学习描述 11
2.3.2 强化学习中的奖励函数 12
2.3.2 强化学习中的策略函数 12
2.3.3 船舶的状态 13
2.4 本章小结 13
第3章 基于强化学习的避碰系统实现 14
3.1 环境界面介绍 14
3.2 搭建环境模块 15
3.2.1海面环境模拟模块 15
3.2.2避碰船和直行船模块 15
3.2.3两船碰撞模块 16
3.3 强化学习算法的具体实现 16
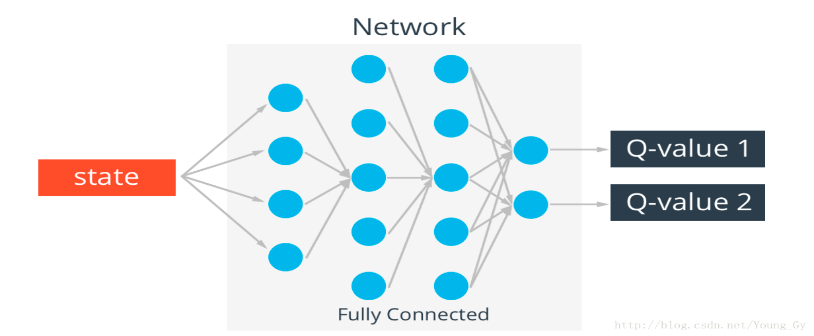
3.3.1 强化学习中的神经网络 16
3.3.2 存储模块 16
3.3.3 记忆库模块 17
3.4 本章小结 17
第4章 实验结果分析 18
4.1 算法性能评价 18
4.2 与无记忆库算法的比较 19
4.3 本章小结 19
第5章 结论与展望 20
5.1 研究成果 20
5.2 进一步的研究 20
参考文献 21
致 谢 23
第1章 绪论
1.1研究背景
海上船舶运输发展快速,在海上航行技术中出现很多新的目标与挑战,如今,在海上航行船的数量急剧增加,船舶总吨位也与日俱增,给海上船舶运行安全带来更加严峻的挑战。为了处理这些问题,保障海上航行的平安,对船舶自动化航行提出了更多要求。比较早年时期的航运设备落后单一,现在的船舶装备精良,但航行过程中碰撞、触礁,搁浅仍时常发生,重大船舶碰撞事故给相关公司造成了极大的损失,也对海上环境产生了极大的恶劣影响,也有研究统计表明,96%的船舶航行事故是因为驾驶船员没有完全遵守《国际海上避碰规则》[1],如果船舶驾驶员在航行途中疲劳过度或遇到过于复杂避碰状况中,机器自动生成相应的避碰动作或者避碰路径,可以有效缓减海员在海上的操作失误。
伴随着深度学习的深入研究,人工智能取得很多长远的进步,其中强化学习是一项十分重要的内容,近年来强化学习效果显著,强化学习(reinforcement learning, 又被称为再励学习, 评价学习)是一种及其重要的机器学习方法, 在智能控制、机器人及分析预测等领域有许多运用。随着近几年深度学习的发展,演化出了深度强化学习这一种新的算法,深度强化学习(Deep Reinforcement Learning)是将深度学习与强化学习结合起来从而实现从感知到动作的端对端学习的算法。强化学习可以有效解决复杂环境因素,让设定好的环境反馈给我们强化信号,以此来产生正确的动作,实现更加优良的避碰。本文就是致力于搭建一个利用强化学习算法实现船舶避碰的仿真系统。
1.2 研究目的及意义
海上交通风险一直是海事研究的核心课题,因为它与交通安全,运输效率,分销可靠性和防止损失相结合[2],为了提高航行安全和防止海上碰撞,过去40年来已经制定了几项管理和航行解决方案。1972年,国际海事组织(IMO)发布了制定导航规则的国际海上避碰规则(COLREGS)。自1981年开始实施的分道通航制(TSS)通过建立交通线路来控制相反的交通流。除了由当局开发的各种系统之外,还有导航工具可用于船长,例如GPS导航设备,自动雷达绘图辅助(ARPA)设备和电子海图显示和信息系统(ECDIS)设备。上述所有系统和设备都主要依赖于自动识别系统(AIS)的数据,尽管现代科研人员在改善航行安全方面作出了重大努力,但由于交通密集程度巨大,冲突数量依然很高,航运事故和事故数量呈上升趋势,比如说新加坡海峡发生事故的平均次数约为每月2000次。在这些冲突中,有些甚至是严重的事故。
众所周知,船舶航行系统需要结合人,船,环境和管理等因素,海上航行充满了不确定性,这个是航行系统的最大特点,在传统驾驶中,人对船的控制是影响船舶避碰系统的主要因素,船舶驾驶人员基本是依靠多年的驾驶经验来进行决策,这些经验用其他方法很难建立准确的数学模型,航行传统的DCPA和TCPA也不能很好的解决各个环境下的避碰问题,但通过强化学习的模拟环境进行学习可以很好的模拟人为驾驶[3]。
本课题的目标就是实现基于强化学习的仿真船舶避碰系统,当一艘船将要碰撞到另一辆船时测量出另一辆的状态,及时避碰,并且在完成避碰后回轨。
本篇论文证明了强化学习算法在船舶避碰领域的可行性,分析了两船避碰的多种情况,能显著减轻船员驾驶的压力,避免船体在运行移动过程中出现危险,实现船舶的自动避碰以减少人工失误。
1.3 国内外研究现状
本文基于自动化船舶避碰这个主题,搭建了两船碰撞仿真平台,并且基于Q 学习算法和神经网络算法,结合船舶航行的《国际海上避碰规则》和相关特性的研究,任何研究都不能一下得出结果,下一节就介绍国内外对船舶自动避碰的研究现状。
1.3.1 国外研究现状
船舶运动的研究自从有船舶运输就从未停止,近现代以来,自从出台第一个国际海上避碰规则,船上的更新了很多避碰装置,如雷达,自动雷达标绘仪(ARPA),船舶自动识别系统(AIS)。提出了许多重要概念,如最近会遇距离(DCPA),最近会遇时间(TCPA)等等,这些成果对于船舶避碰领域都有很重要的意义,也为之后该领域的发展提供必要的实际和理论依据。
八十年代以来,信息技术的发展和智能算法的进一步研究,让智能避碰成为了十分火热的研究方向,其中有代表性的是英国利物浦工业大学研发的原型实时航海知识库系统[3]和日本东京商船大学研究制作的船舶避碰决策系统[4];美国理工大学(Rensselaer Polytechnic Institute,简称 RPI)也提出了一套智能驾驶决策辅助系统,进入新世纪以后,英国南安普顿大学根据导弹制导原理,提出了只注重躲避目标,去忽略捕捉目标的船舶避碰方法。该方法显然没有充分考虑避碰规则以及海员之间的通常做法等,但这是一种新的思想,值得我们去学习研究,该大学的 Tien Tran 等人构建了一个名为“海上避碰航行完全综合系统”的避碰系统。
国外对于强化学习的研究在近几年取得了很多成果,比如,在2010年的时候, Lang提出了深度自动编码用于基于视觉的相关控制,尝试将深度学习和强化学习结合,和目前的框架已经有些相似。在2011年,Abtahi等人用DBN替代传统的强化学习中的逼近器,但真正成功的开端是DeepMind在NIPS 2013上发表的一篇关于深度强化学习的文章引起了广泛的关注[5],Pieter Abbeel团队紧随DeepMind之后,采用另一种方法直接实现了机器人的End-to-End学习[19],其成果也引起了大量的媒体报道和广泛关注。2017年,Google团队Alphago zero对战世界排名第一的围棋选手柯洁的胜利,机器学习领域兴起了强化学习研究热潮。
1.3.2 国内研究现状
我国对于船舶避碰的研究相对于国外研究者来说比较晚。但经过将近 20 余年的发展,国内上海海事大学、海军工程大学、大连海事大学、上海交通大学、武汉理工大学、集美大学、华中科技大学等大学在船舶自动避碰研究上有了一些可靠地的成果。根据国内研究情况,我国学习主要研究的方向大致有三个:其中一个是对船舶自动避碰研究中的局部细节进行了深入研究,主要集中在船舶碰撞危险度、避让时机决策、最晚施舵点等自动避碰基本要素的定量化研究上;另一个是根据船舶避碰的特点,从心理学的角度出发,分析人在避碰过程中的可靠性与避让方法的关系;最后一个是对船舶自动避碰系统的整体化研究,主要集中在人工智能技术与船舶自动避碰相结合的研究上,这与国外研究同行的研究方向与进程基本相同。
我国对于船舶避碰方面也有研究实例:大连海事大学的谢洪彬研究了对建立避碰专家系统[6];海军大连舰艇学院的杨宝璋教授研究了多个方面包括:对避碰自动化系统的性质、数学模型的建立、系统的构成等[7];海军广州舰艇学院的王敬全教授构建了数字化船舶碰撞的数据库[8];上海事大学施朝健教授研究了利用微分对策对两船避碰问题[9];集美大学的李丽娜建立了基于MAS和航海模拟器技术构建船舶自动避碰仿真平台[10]。
到现在为止,虽然这些研究还停留在实验室阶段,投入到实际航海应用的产品还没有真正出现,并没有形成实际已经使用用到的应用的系统,但是这些研究成果使得船舶智能避碰的理论研究有了新的方向。
1.4 主要研究内容
近年来人工智能技术的研究,为船舶避碰系统的改善提供了很多新的思路和改进算法,让船舶避碰领域取得了很多新的进展。
强化学习是机器学习中的一个重要研究领域,它以试错的机制与环境进行交互,通过最大化累积奖赏来学习最优策略。目前强化学习经常运用在机器人和工业自动化,机器人和工业自动化,文字,语音和对话系统等领域,国内外的研究者也有开始尝试,通过强化学习来实现船舶避碰,并取得了一些成果[11]。
综上,将强化学习的原理应用于船舶避碰的研究,提出基于强化学习的船舶避碰决策的模型,并建立基于强化学习的船舶避碰决策仿真系统。
本文以强化学习为主要的的研究算法,通过累积奖赏来尽量满足国际海上避碰规则,构建了基于强化学习的船舶避碰决策系统的框架,试验的重点在于对避碰问题进行描述,建立适合两船的模型。
本课题的研究,只对一些处在良好的海上环境的避碰决策进行研究,即水域和天气等外部环境都处在良好的状况。
在研究过程中,通过模拟碰撞环境进行交互,通过最大化累积奖赏来学习最优策略,当两船碰撞时给予最大惩罚值,以Ubuntu 16.04为主要的操作系统,利用python中的Tensorflow来构建神经网络,使用Team MIT DRC的Director来进行仿真模拟,设计并实现了一种基于强化学习的船舶避碰系统。
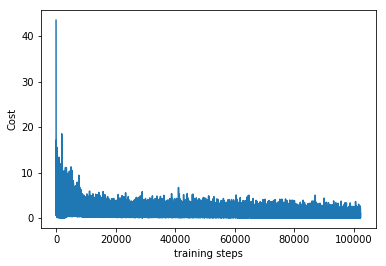
在接下来的内容中首先需要对强化学习进行介绍与设计,之后对强化学习进行具体的实现,最后对实验结果主要是神经网络的损失值的变化和实际避碰效果进行比较,并且对和没有设置记忆库的结果进行比较。
第2章 基于强化学习的船舶避碰算法设计
为了完成本次设计不光需要对强化学习进行了解,还需要详细了解关于船舶避碰的相关知识,最后将两者结合设计强化学习的算法。
2.1 强化学习基本原理
强化学习是机器学习中的一个分类,他又别于机器学习的另外两个监督学习和非监督学习,是通过分析机器在环境中运行的动作所获得的奖励值来完成动作的优先级,机器不停的学习,不停的得到奖励和惩罚,最后通过不停的积累,完成强化学习的过程,一般来说学习的环境越复杂,学习的时间就需要越久。接下来就对强化学习和毕业设计中使用的算法进行介绍。
2.1.1 强化学习概述
强化学习一种是让计算机如同一个不会移动的,只会在原地哭泣的婴儿,通过在爬行中不断地尝试,在爬行过程中的种种反馈中学习,最后学会行走达到目的的方法。图2.1给出了强化学习的一个简单图示,强化学习通常用马尔可夫决策过程来叙述当机器处于一种环境中时,处在状态x,当动作a执行时,当前状态修改为另一个状态并且反馈给机器一个奖赏[13],现实中成功运用的强化学习完成系统的有很大,比如几年前战胜围棋高手李世石的Alphago[14],几乎是第一次机器战胜职业围棋选手,让计算机从完全不会到精通 Atari等,这些例子都是让机器在奖励函数的指导下,按人们想要的行为准则,一步步学会如何进行下一步的动作。
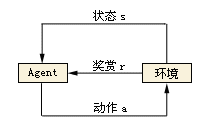
图2.1 强化学习图示
比较机器学习中的另一个算法监督学习,强化学习一开始没有数据和标签,它是通过在环境中的状态变化,来获取数据和标签,然后再学习通过哪些数据能够对应哪些标签, 通过学习到的这些规律,得到相应的高奖励值。
强化学习它包含了很多种算法,主要分为有模型学习和免模型学习,在现实的强化学习任务中,环境的变化概率,奖励的函数往往很难可以得到,甚至环境中有多少状态也很难知晓,所以本文主要使用的是免模型学习算法,其中有通过行为的价值来选取特定行为的方法,包括使用表格学习的 Q学习,Sarsa,使用神经网络的特性的深度强化学习,还有直接输出行为的策略下降等等。
2.1.2 强化学习的基本要素
强化学习的关键要素有:环境,奖励,动作和状态。有了这些要素我们就能建立一个强化学习模型。强化学习解决的问题是,针对一个具体问题得到一个最优的策略,使得在该策略下获得的奖励最大。所谓的策略其实就是一系列动作。
强化学习中要素的关系如图2.1所示,模型中奖励函数和概率转移函数是未知的,所以每次的动作改变状态后进行状态评价,以次来得到奖励值。在学习过程中不光要当前的奖励即及时回报,还要从长远的角度来考虑[14]。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: