自顶向下语法分析器的可视化交互仿真毕业论文
2020-04-04 10:50:41
摘 要
Abstract 2
第1章 绪论 3
1.1 论文研究背景及意义 3
1.2 国内外研究现状 3
1.2.1 编译技术国内外研究现状 3
1.2.2 可视化国内外研究现状 4
1.3 主要内容及技术路线 5
1.3.1 论文主要内容 5
1.3.2 采用的技术路线 5
1.4 论文组织结构 5
第2章 自顶向下语法分析原理 6
2.1 文法 6
2.1.1 正则文法 6
2.1.2 上下文无关文法 7
2.2 语法分析 7
2.2.1 自顶向下语法分析 8
2.2.2 消除左递归 8
2.2.3 提取左公因子 9
2.3 错误处理 12
2.4 本章小结 12
第3章 自顶向下语法分析可视化分析与设计 13
3.1 需求分析 13
3.2 软件结构设计 13
3.2.1 前端设计 15
3.2.2 后台设计 17
3.3 本章小结 18
第4章 自顶向下语法分析可视化的实现 19
4.1 整体架构 19
4.2 开发环境的选择 19
4.2.1 Visual Studio Code 19
4.2.2 Microsoft Visual Studio 19
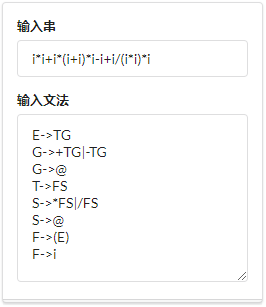
4.3 文法编写规则 20
4.4 前端页面实现 20
4.4.1 使用的前端框架 20
4.4.2 输入文法和符号串模块 21
4.4.3 FIRST集合、FOLLOW集合和预测分析表模块 22
4.4.4 分析过程模块 23
4.4.5 对应算法伪代码模块 24
4.4.6 语法分析树模块 25
4.5 后台程序实现 26
4.6 本章小结 27
第5章 系统测试 28
5.1 测试环境 28
5.2 测试用例 28
5.3 功能测试 29
5.4 兼容测试 32
5.5 本章小结 32
第6章 结论 33
6.1 工作总结 33
6.2 展望 33
致谢 34
参考文献 35
摘 要
编译原理是计算机科学与技术这一学科中核心的课程之一,也是对于当代程序员开发软件的必修课程之一。所以掌握这样一门课程,在日后的科研与工作之中都是显得尤为重要的。
本文主要针对编译器前端中语法分析这一部分进行阐述,着重研究了语法分析,尤其是自顶向下语法分析,并对正则文法和上下文无关文法进行了论述。在实现过程中,先对其进行需求分析,通过UML建模语言对构建出对应的系统模型。再选择以可维护性高和灵活性强的B/S架构作为开发架构。以及最后再测试系统中的重要模块。
系统界面布局简洁,使用起来操作方便,展示效果明显。在过程可视化展示上,通过提供分析结果完整展示等方法,以达到编译过程可视化效果。对《编译原理》课程中的编译过程、各阶段主要算法、相关数据结构等都起到了辅助教学的作用。
关键词:编译原理;语法分析;算法可视化;
Abstract
In the subject of computer science and technology, the principle of compiling is one of the core courses, as well as a compulsory course for modern programmers to develop software. So mastering such a course is particularly important in the future of scientific research and work.
This paper focuses on the grammar analysis in the front-end of the compiler, focusing on the grammar analysis especially the Top-down grammar analysis, in which the regular grammar and context-free grammar have been discussed. In the process of implementation, the requirement analysis is carried out first and the system model is constructed through the UML modeling language. And choosing the B/S architecture which is highly maintainable and flexible as the development framework. Finally, the important modules of the system have to be tested.
The system interface is simple in layout, easy to use, and the effect of displaying is obvious. In the displaying of visualized visualization, implementing the displaying effect of compiling process by providing the methods of full demonstration of analyzing result. The compiling process, the main algorithms and the related data structure in the course of compiling principles have played an auxiliary role in teaching.
Key Words:Compiler Principles; syntax analyze; visualization of algorithms
第1章 绪论
1.1 论文研究背景及意义
伴随计算机行业的发展,该行业对于在计算机相关领域中的精尖人才的需求愈来愈大。而对于编译原理这门计算机科学与技术核心课程,既能帮助相关从业人员加深对程序编译过程的理解,并且能够在理解编译原理相关算法的基础之上设计出更为优秀的程序,编写出使编译器更容易进行优化的代码,可以见得该门课程对于培养计算机行业相关精尖人才夯实基础有着十分重要的作用。
但是由于编译原理相关算法存在一定的复杂性和抽象性,使得常规教学中所使用的多媒体教学方式不能足以让学生理解透彻对应算法的原理,从而让教学收效颇差。尽管如今存在一些可视化编译软件可用于阐述相关原理和课堂教学作用,但是缺少对于编译原理前端语法分析过程的特定的和详细的可视化编译软件。
为了解决这类存在于编译原理教学中的过程,本文设计了一个针对编译器前端可视化的软件。本软件是基于LL(1)文法,针对语法分析部分进行可视化,与当下其它软件不同之处在于可以根据输入的不同显示出各个算法的可视化结果,使得相关学习人员可以对其背后的原理及相关运行机制有着更深一步的理解。
1.2 国内外研究现状
1.2.1 编译技术国内外研究现状
大约在20世纪50年代末期,与机器无关的编程语言被首次提出。随后,人们开发了几种实验性质的编译器。世上首个编译器是在计算机科学家葛丽丝·霍普于1952年为A-0系统编写的。但是1957年由任职于IBM的美国计算机科学家约翰·巴科斯带领下的FORTRAN则是第一个被实现出具备完整功能的编译器。1960年,COBOL成为一种较早的能在多种架构下被编译的语言。高级语言在许多领域流行起来。由于新的编程语言支持的功能越来越多,计算机的架构越来越复杂,这使得编译器也越来越复杂。最初的编译器是由汇编语言编写的。而首个能编译自己源程序的编译器是在1962年由麻省理工学院的Hart和Levin制作的。从20世纪70年代起,实现能编译自己源程序的编译器已基本完全具有可行性,但更多是以C和Pascal实现。
数年来,编译器相关技术在国外的研究主要体现在:编译器中采取了大量算法用于在程序编译过程中的优化。例如:即时编译,又称为及时编译或实时编译。它是动态编译的一种,常用于优化程序运行。一般来说,程序有动态解释和静态编译两种。其中,解释是一行一行对源码进行翻译运行,而编译是在运行前将其全部翻译为目标代码。而结合了这两者的即时编译器,将逐行编译源码,但其中缓存翻译后的目标代码这一行为将会带来成性能上的损耗。由即时编译获得的目标代码是具备高安全性和延迟绑定的特性,这是相较静态编译的优势。同时,即时编译也存在两种类型:动态编译翻译和字节码翻译。并且即时编译提供了.NET Framework和JVM的实现以及对应代码的高效运行。即时编译技术也应用于各处,例如:Mozilla Firefox的JavaScript引擎SpiderMonkey和Ruby、Python的第三方实现Rubinius、PyPy。而在国内多集中于编译过程中某一部分或某一阶段的研究,且大多数用于教学领域[1][1],常常利用一些如lex、yacc[2][2]和bison等工具来实现编译系统中的可视化(),又或者是专门针对于编译器前端[3][3]或特定编程语言[4][4]来设计。并将分析过程以转换图或转换矩阵的方式呈现[5][5]。
1.2.2 可视化国内外研究现状
科学可视化[6][6]是一个交叉学科的研究领域,着重关注各种现象的可视化,如生物学、医学或地质学等,尤其是对光源、几何图形和 的渲染。它从属于计算机图形学,也是计算机科学的一个重要方向。科学可视化的目的是以图形方式说明科学数据,使科学家能够从数据中了解、说明和收集规律。
美国国家科学基金会的可视化会议是最早于1987年提出可视化这样一个概念的,从而让可视化这样一门新兴技术得以发展了起来。起初,可视化技术是应用于科学计算之中,通过图表等直观的方式来展示出来,使得科研人员能够根据这些图表从新的角度来进行数据上的科学分析,使得传统的学科有了新一步的发展。
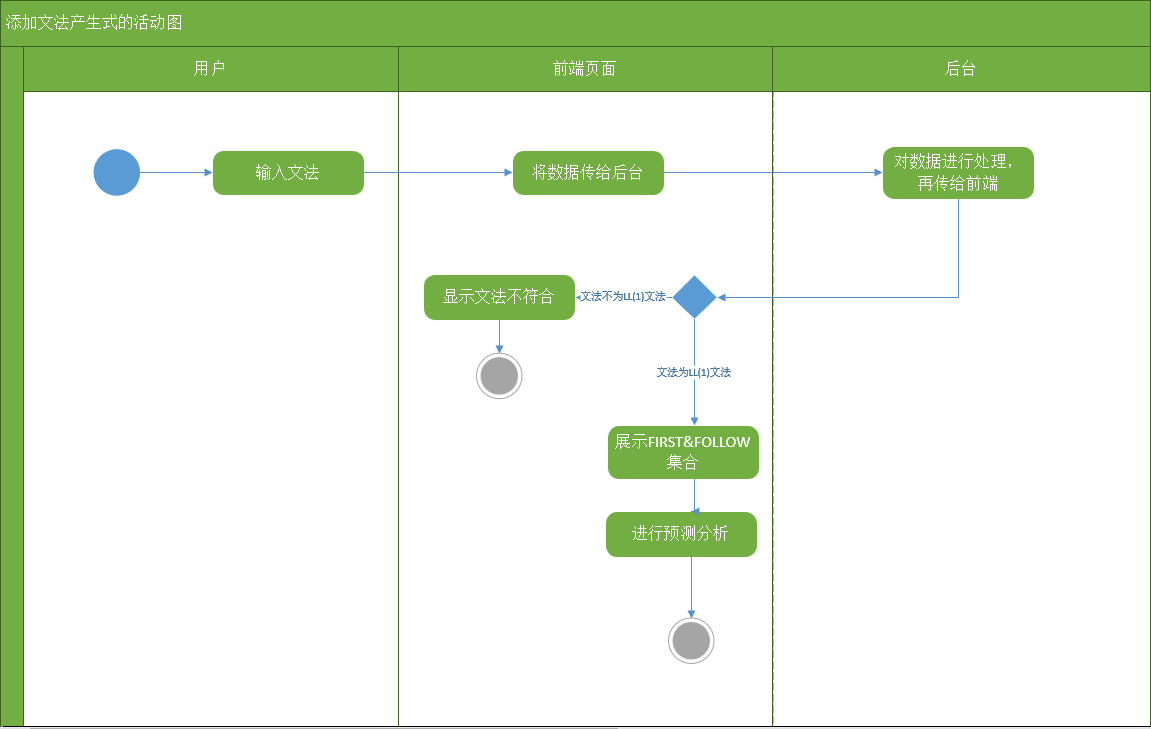
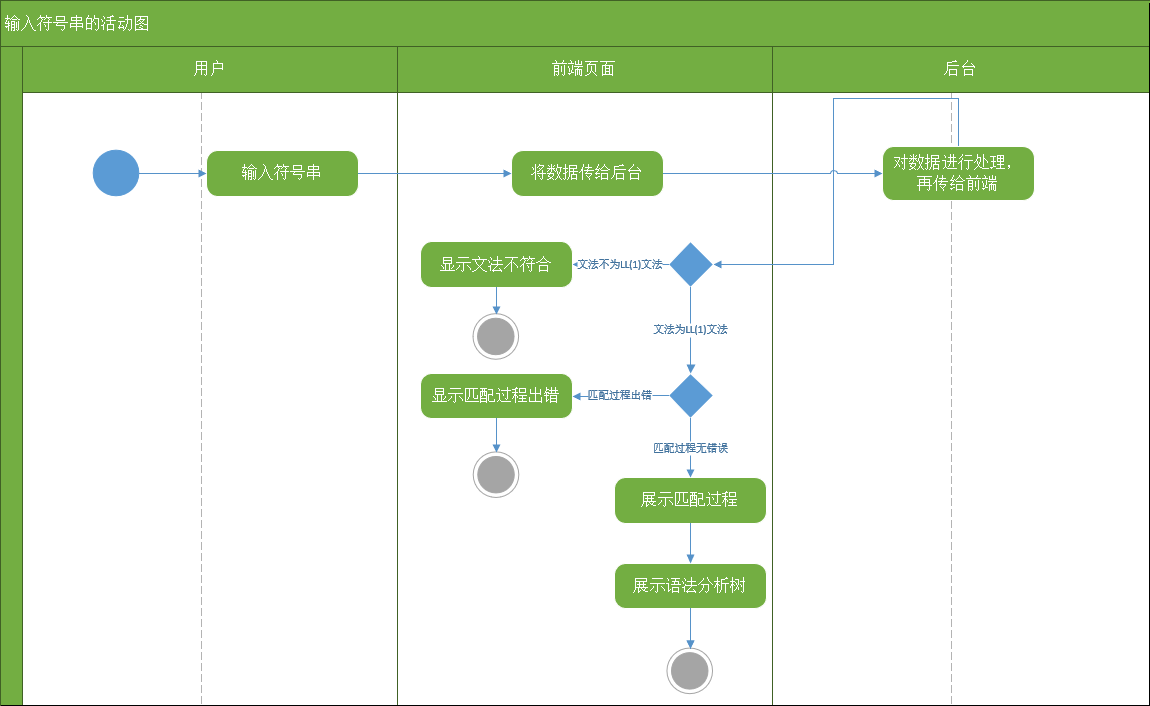
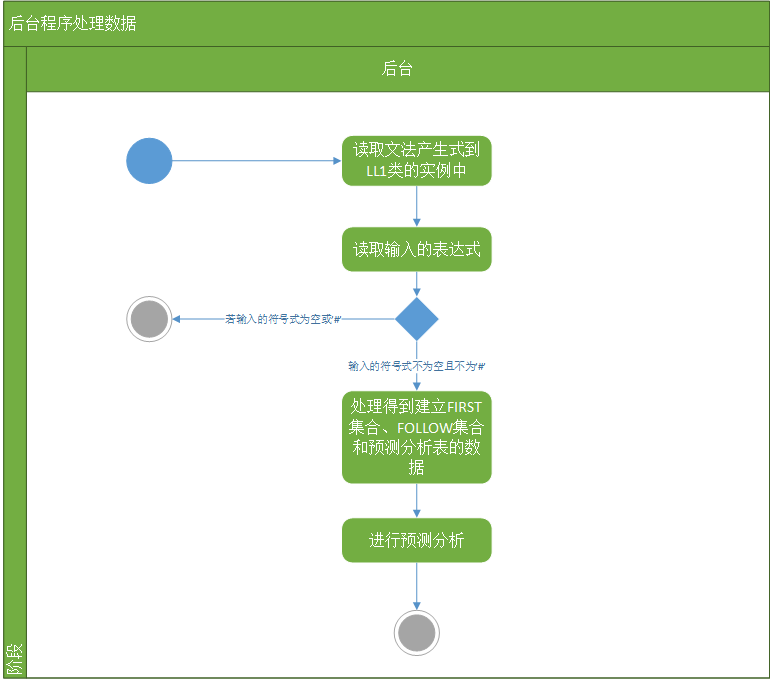
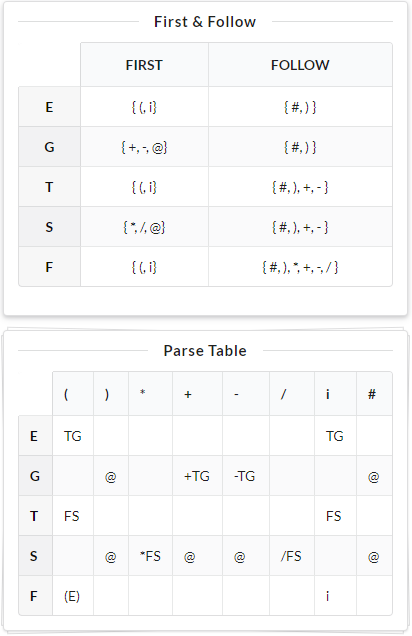
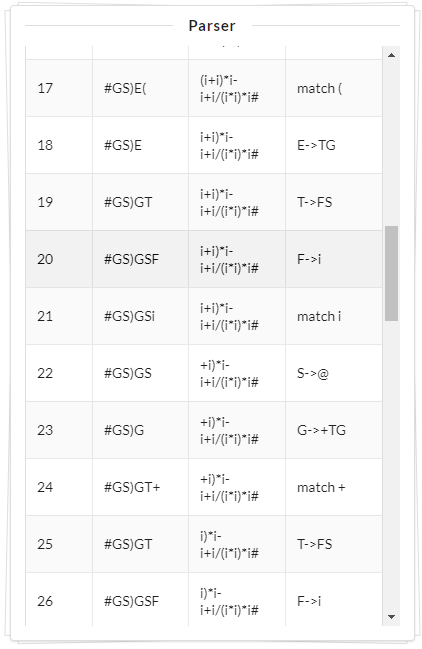
故在本文中采用数据可视化的方法来实现语法分析过程可视化。如:FIRST集合、FOLLOW集合、预测分析表、分析过程和语法分析树。
1.3 主要内容及技术路线
1.3.1 论文主要内容
本文主要针对编译原理中语法分析相关算法的过程可视化进行程序的设计与实现,将主要针对语法分析部分展开。其主要内容为:能够根据编译原理前端中的语法分析部分,清楚地理解并掌握其中所涉及的原理,以及如何实现对应算法且能在实现对应算法时规避掉一部分可能出现的错误。
1.3.2 采用的技术路线
实现对应程序时,先通过UML建模软件进行分析与设计,绘制对应的用例图、流程图、活动图和类图等等,再根据建立的模型来编写对应的程序。而程序的实现打算通过B/S架构进行前端、后台的分离。
1.4 论文组织结构
本文一共有六个章节,其组织机构和对应内容如下:
第一章是绪论,分别阐述了本文的研究背景和意义、国内外研究现状、论文主要内容及技术路线。
第二章是对要实现的编译原理前端中的语法分析部分进行原理上的介绍。
第三章是对要实现的程序的分析与设计,根据需求分析等设计出对应不同的UML模型。
第四章是对程序的实现的各个部分进行阐述,主要分为前端、后台,以及其中各个模块的实现思路,以及测试部分。
第五章是对本次毕业设计的总结与展望,总结了此次过程中的成果,以及对于不足之处的展望。
第2章 自顶向下语法分析原理
2.1 文法
语法分析的任务是,是确定某个单词流能否够与源语言的文法适配。这意味着,可以在描述文法的同时检测文法。所以我们需要一种符号表达式来描述计算机程序设计语言的文法[7][7]。
2.1.1 正则文法
正则文法是可由有穷自动机和非确定有穷自动机 [8][8]识别的一种文法。其分为两种类型:一类要求生成式的形式必须是或,其中A,B都是变元,是终结符串或空串,这种特殊的正则文法称为右线性文法。另一类正则文法称为左线性文法,它要求生成式必须是,或的形式。
以一种形式化方式定义正则表达式。一个正则表达式(Regular Expression,简称RE)描述了一个定义在某个字母表Σ上的字符串的集合,外加一个表示空串的ε[9][9]。我们将字符串的这种集合称为一种语言。对于给定的正则表达式r来说,我们将它规定的语言记作L(r)。一个正则表达式由三个基本操作构建而成。
(1) 选择 两个字符串集合R和S的交集,记作R | S,定义为 。
(2) 连接 两个集合R和S的连接记作RS,由R中任意一个元素,再后接S中任意一个元素所组成的所有字符串,定义为。
(3) 闭包 集合R的科林闭包,记作R∗ , 定义为 。其是R与自身连接零或多次后形成的所有集再取并集。
使用选择、连接和柯林闭包三个基本操作,我们可以如下定义字母表Σ上RE的集合
(1) 如果a∈Σ,那么a也是一个RE,表示仅包含a的集合。
(2) 如果p和q是RE,分别表示集合L(p)和L(q),那么p | q也是RE,它表示L(p)和L(q)两个集合的并集。并且pq也是一个RE,表示L(p)和L(q)的连接,而r*也是一个RE,表示L(r)的柯林闭包。
(3) ε是一个RE,表示仅包含空串的集合。
尽管RE是一种简洁的符号表示法来描述语法,还有一种高效的机制用于测试字符串是否属于RE描述的语言,但是无法写出一个RE来匹配左右平衡的所有表达式。例如:[a-z]([a-z]|[0-9])*(( |-|*|/)[a-z]([a-z]|[0-9])*)* 这个RE可以匹配a b*c和a/b*c,但是RE中并没有存在运算符优先级的概念。
给RE添加 { 和 } ,使表达式可以从字符 { 开始,以字符 } 终止,以表现出语法的优先级。故更改RE为( { |ε)[a-z]([a-z]|[0-9])*(( |-|*|/)[a-z]([a-z]|[0-9])*) *( } |ε)) ,使其能够匹配p q*m和(m n)*o,以及匹配用变量和四个运算符表达的任何正确的带括号的表达式,但仍然存在会匹配括号左右平衡的所有表达式(成对结构,例如:begin和end或是then和else,在大部分程序设计语言中扮演着重要的角色。),这是因为RE只有一个有限状态集。对于语言(m)n,其中m=n,并非是正则语言。虽然对于某些语法处理得很好,但不适合描述一些重要得程序设计语言。
2.1.2 上下文无关文法
上下文无关文法是常用于描述在给定的形式语言中符合一系列规则的产生式的一种文法,例如:A→α。下推自动机[10][10]可以识别上下文无关文法,而其相较有穷自动机而言,还多包括一个长度不受限制的栈,故在其状态迁移过程中,对于有限状态部分和栈当前部分均需进行参考[11][11]。而除了其状态迁移过程之外,还仍有出、入栈的过程,也正是因此可以对括号左右平衡的所有表达式进行匹配。下推自动机作为一个形式系统,其等价与上下文无关文法可见。
形式上,上下文无关文法G是一个四元组(T, NT, S, P),其中各元素解释如下。
- T 是终结符或语言L(G)中单词的集合。终结符对应于词法分析器返回的语法范畴。
- NT 是G的产生式中出现的非终结符的集合。非终结符是语法变量,引入非终结符用于在产生式中提供抽象和结构。
- S 是一个非终结符,被指定为语法的目标符合或起始符号。S表示L(G)中语句的集合。
- P 是G中产生式或重写规则的集合。P中的每个规则形如NT→(T∪NT) ,即每次将一个非终结符替换为一个或多个语法符号构成的串。
集合T和NT可以直接从产生式的集合P推导出来。
2.2 语法分析
语法分析是编译器前端中的第二阶段。语法分析器处理由词法分析器转换生成的程序,从语法分析器的视角来看,输入的程序是一个单词流,其中各个单词都标注语法范畴(词类)。语法分析器为该程序推导一个语法结构,将各个单词适配到源程序设计语言的语法模型中。如果语法分析器确定输入流是一个有小程序,它将构建该程序一个具体模型供后阶段使用。如果输入流不是一个有效程序,语法分析器将向用户报告问题和诊断信息。
2.2.1 自顶向下语法分析
自顶向下语法分析从语法分析树的根结点开始,系统地向下扩展树,直至树的叶结点与词法分析返回的已经归类的单词相匹配[12][12]。在过程的每一点上,都需要考虑一个部分完成的语法分析树。过程在树的下边缘选择一个非终结符,选定某个适用于该非终结符的产生式,用于产生式右侧相对应的子树来扩展该结点。终结符是无法扩展的。语法分析过程将持续进行,直到:
(1)语法分析树的下边缘只包含终结符,且输入流已经耗尽;
(2)或者部分完成的语法分析树的下边缘各结点,与输入流存在着明确的不匹配。
第一种情况,语法分析是成功的。第二种情况,有两种可能情形。语法分析可能在过程中此前的某一步选择了错误的产生式,在这种情况下可以回溯,并系统地考虑此前的决策。如果输入符号串是有效语句,回溯将语法分析导向一个正确的选择序列,并构建出正确的语法分析树。当然,如果输入符号串不是有效语句,回溯将失败,则应向用户报告语法错误。
自顶向下语法分析可以高效进行在于上下文无关语法的很大一个子集不进行回溯即可完成语法分析。
2.2.2 消除左递归
在上下文无关文法内,若存在一种文法规则其中的产生式,其右侧第一个符号与左侧符号相同或者能够推导出左侧符号,则该文法规则是存在左递归的。对于前一种情况称为直接左递归,而后一种情况称为间接左递归。
之所以要消除左递归,是因为左递归的存在可能会使得自顶向下语法分析无限循环,而不会生成与输入匹配的起始终结符。幸好可以通过将左递归转换为右递归以达到消除左递归的作用,并且这样的转换是有规可循的[13][13]。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: