基于文件同源性分析的嵌入式设备固件漏洞检测毕业论文
2020-02-23 18:22:58
摘 要
不同的生产商在开发嵌入式设备固件时,经常会使用相同的第三方程序,如cgibin、httpd、tftp等。而一旦这些开源的程序或运行库存在漏洞,就会导致这些漏洞出现在不同的商家的产品中,对于特定厂商、特定型号、特定版本的嵌入式设备固件的分析通常无法代表该系列大多数固件的安全状况,不同固件的漏洞发掘过程也存在较多的重复性工作。基于文件同源性分析的嵌入式固件漏洞检测方法考虑不同的固件在开发过程中引入文件或代码片段的同源性关系,且忽略漏洞的具体表现,因此能够快速简略地对固件进行初步的安全性分析,适用于大规模的固件安全状况分析需求。本论文选择家用路由器作为嵌入式设备的代表,依据若干近期文献的理论,对部分文献中的实验进行了复现。旨在根据已知存在漏洞的路由器设备固件,将其解包并寻找合适的特征文件或反汇编代码片段,利用二进制差量分析、字符串常量匹配、模糊哈希三种文件同源性分析方法,检测未知的路由器固件中是否存在漏洞。最后设计并开发了在线平台,实现用户可用。
关键词:嵌入式设备;固件漏洞;固件安全;同源性分析;
Abstract
Different manufacturers often use the same third-party programs such as cgibin, httpd, and tftp when developing embedded device firmware. Once these open source programs or running inventory are in a loophole, these vulnerabilities will appear in products of different vendors. Analysis of the firmware of a specific vendor, a specific model, and a specific version of an embedded device usually cannot represent most firmware of the series. The security situation, there are more repetitive tasks in the process of exploiting different firmware. The vulnerability detection method of embedded firmware based on file homology analysis considers the homology relationship of files or code fragments introduced by different firmware during the development process, and ignores the specific performance of the vulnerability, so the initial security of the firmware can be quickly and simply implemented. Sex analysis, suitable for large-scale firmware security analysis requirements. This paper takes a home router as an example, according to the theory put forward by several existing papers, the experiments on homology analysis in some articles are reproduced. Designed to unpack and find appropriate signature files or disassembled code fragments based on known buggy router device firmware, using binary differential analysis, string constant matching, fuzzy hashing, and three file homology analysis methods , Detects whether there is a loophole in the firmware of the unknown router. Finally, an online platform was designed and developed to make it available to users.
Key Words: Embedded Devices;Firmware Vulnerability;Firmware security;Homology Analysis;
目录
摘要 i
Abstract ii
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外相关研究 2
1.3 主要研究内容 3
1.4 本文组织结构 4
第2章 相关理论 5
2.1 同源性分析 5
2.2 网络数据采集 6
2.3 在线平台开发技术 7
2.4 本章小结 8
第3章 实验前期准备 9
3.1 数据收集 9
3.2 数据预处理 10
3.3 实验工具和平台 12
3.3.1 实验软件工具 12
3.3.2 实验环境 13
3.4 本章小结 14
第4章 实验结果与分析 15
4.1 D-LINK DIR-505缓冲区溢出漏洞 15
4.2 TENDA AC15远程代码执行漏洞 16
4.3 本章小结 17
第5章 结论 18
参考文献 19
致谢 21
第1章 绪论
1.1 研究背景及意义
随着我国互联网事业的腾飞和网络通讯技术的进步,物联网产业也获得了蓬勃的发展,越来越多的嵌入式设备接入了互联网,手机、打印机、路由器都属于嵌入式设备。嵌入式设备包含“固件”,即固化的软件,被写入到EEPROM、Flash等随机只读存储器中,轻易不会更改。与传统的计算机软件相同,嵌入式设备中的固件也可能存在安全漏洞。由于嵌入式设备体积较小,数量众多,从前被关注程度较低,由此带来的安全问题较传统计算机也更加突出。近几年经常有关于嵌入式设备安全事件的相关报道,例如:家用智能路由器被黑客控制后用于组织僵尸网络(BotNet)发动分布式拒绝服务攻击(Distributed Denial of Service,DDoS)、智能摄像头被黑客控制后网上直播用户隐私画面、公路信号灯被黑客控制后工作异常导致交通阻塞等。嵌入式设备存在的信息安全问题目前受到了公众更为广泛的关注。
在嵌入式设备的生产过程中,设备公司通常仅写入引导程序(boot),而诸如操作系统、文件系统等则是先交由软件外包公司构建,再交给生产商。这就出现了一个现象:不同的设备公司可能选择同一个外包公司。由于外包公司使用的编程工具、开发包、引入的第三方程序等没有统一的标准,使得不同品牌的嵌入式设备的固件中有很大概率包含相同的第三方程序或文件。因此,嵌入式设备会受到一些来自于共同的第三方程序中现已公开的安全缺陷的影响,同一个第三方程序的安全漏洞也可能会出现在不同厂商、不同型号的嵌入式设备中,这就导致不同固件安全漏洞发掘过程包含较多的重复性劳动。仅对于特定厂商、特定型号、特定版本的嵌入式设备固件的分析通常也无法代表该系列大多数固件的安全状况,需要找到一种快速、准确的嵌入式设备固件漏洞检测方法,实现有效判别不同固件或同种设备的不同版本固件所包含的第三方程序或文件之间的关联性和相似度,从而确定引入的第三方程序或文件的同源性,进而对固件中可能包含的安全缺陷进行检测。
本论文选择家用路由器作为嵌入式设备的代表,依据若干近期文献的理论,对部分文献中的实验进行了复现。旨在根据已知存在漏洞的路由器设备固件,将其解包并寻找合适的特征文件或反汇编代码片段,使用二进制差量分析、字符串常量匹配、模糊哈希三种文件同源性分析方法,检测未知的路由器固件中是否存在漏洞。
1.2 国内外相关研究
传统的路由器固件安全性检测方法主要有提取特征码、分析执行过程、提取敏感函数等,上述检测方法针对数目较小的固件集进行漏洞检测可能具有较为理想的表现。但是,近几年智能嵌入式设备层出不穷,传统的固件安全性检测方法已经不太适合大规模的固件安全状况检测需要。
由于嵌入式设备固件通常而言专用于特定的硬件,动态分析不同提供商的嵌入式设备一般需要使用其配套的调试设备,而且不同设备固件的特定执行环境需要QEMU等虚拟化模拟器进行模拟。这种方法的分析对象单一,人工分析过程在漏洞检测工作中所占比重较高,无法对同系列多数固件的综合安全状况实施评估。因此动态分析方法对嵌入式固件安全综合分析来说适用性较差。目前固件漏洞分析的主流是静态分析方法,如检测某个固件程序中的特征码,或采用符号执行对程序的控制流和数据流进行跟踪。但是静态分析方法也存在一些难点,如:由于不同体系结构的指令集不同,导致跨体系结构交叉编译生成的二进制文件其内部的机器指令完全不同,这就给静态分析带来了一定的困难。即使二进制文件属于统一平台,内部机器指令的指令集也相同,在文件特征的选择、提取、筛选,以及静态分析方法和手段等方面也引起了相关安全研究人员的关注。
马丁于2011年提出了基于函数控制流图的结构化比对算法[12],该算法结合了基本块签名和基本块之间一阶跳转关系,可以输出函数相似度和文件综合相似度。颜颖等人于2017年提出了基于跳转逻辑等基本块指纹的对比分析算法[9],该方法从基本块中提取了跳转逻辑、代码序列、子方法名称三个特征,首先根据控制流图得到不同基本块跳转逻辑的相似度,再利用点距阵方法计算代码序列的相似度,然后通过编辑距离算法计算子方法名称的相似度,最后综合上述结果输出基本块的相似度,以此进行同源性分析。Jannik Pewny等人于2015年在IEEE Symposium on Security and Privacy会议上提出了基于语义的跨平台二进制漏洞检测方法[1],首先将不同平台下的二进制代码首先翻译为统一的中间形式,然后经过转语义表达式、数值采样和最小Hash加速处理,得到基本块,再根据漏洞签名对获得的基本块进行检测。作者以OpenSSL的“心脏出血(HeartBleed)”漏洞为例,在特定测试集上进行实验,性能指标Top1为32.1%。中国研究者常青在上述工作的基础上提出了“基于神经网络和局部调用结构匹配的跨平台固件漏洞关联方法[2]”,该方法的实施包括两个过程,依次是:基于神经网络的函数数值相似度计算阶段、基于局部调用结构匹配的函数整体相似度计算阶段。在函数数值相似度计算阶段,作者提取了指令个数、调用字符串个数等函数数值特征和函数控制流图特征,由上述31维特征构成了相似度量向量,然后通过ReliefF算法进行特征筛选,去掉了权重较小的一些特征,最后的相似度量向量维度为23维。常青等人将最终成果命名为VANS(The Framework of Vulnerability Detection Based on Neural Networks and Struct Matching,VANS),并称该方法使得在同一固件集上的性能指标Top1从32.1%提高到了76.49%。
1.3 主要研究内容
本课题的主要研究内容是基于文件同源性分析的家用路由器固件漏洞检测,实施过程包括路由器固件批量采集、解包、特征文件和特征代码片段的提取、建立特征数据库以及基于上述工作的字符串常量匹配、二进制差量分析、模糊哈希的特征文件同源性分析,最后根据分析结果对采集到的固件的安全状况进行评估。下面简单介绍字符串常量匹配、二进制差量分析、模糊哈希三种文件同源性分析方法:
字符串常量匹配法来源于字符串常量在编译过程中与体系结构依赖性较低,同一份源代码基于ARM、MIPS、Intel x86等不同体系结构交叉编译,字符串常量往往不发生改变。因此这种方法能够较好地适应跨体系结构之间的第三方程序或文件的同源性分析。
二进制差量分析和模糊哈希方法擅于发现不同程序二进制代码中的变化,对基于单一体系结构下编译固件的同源性分析效果较好。由于ARM、MIPS、Intel x86等不同体系结构的机器指令集差别较大,同种操作的机器指令可能完全不相同,所以基于不同体系架构编译生成的二进制文件差异也很大,因此针对跨架构下的同源性分析效果不明显。
本文首先使用网络数据采集技术收集、下载不同品牌、不同型号的路由器固件,为大规模的分析提供数据支持;然后对采集到的设备固件进行解包,从已知存在漏洞的固件中寻找合适的特征文件,并编写IDA脚本从文件中提取出特定函数的反汇编代码,利用同源性分析方法,检测采集到的固件中是否存在漏洞。最后设计并开发了文件同源性分析平台,实现文件同源性在线分析,从而简化上述步骤,实现用户可用。
1.4 本文组织结构
本文主要分为以下几个部分:
第一部分,绪论,介绍课题研究背景、研究意义、国内外研究现状。
第二部分,相关理论。首先详细介绍文件的同源性分析理论及方法,包括关于字符串常量匹配、二进制差量分析、模糊哈希等。然后简单介绍网络数据采集理论及文件同源性分析平台开发相关技术。
第三部分,介绍实验数据来源及预处理过程。
第四部分,介绍实验结果及分析。
第五部分,总结和展望。
第2章 相关理论
2.1 同源性分析
同源性分析(Homology Analysis)的概念起源于生物学,最早存在于分子进化的研究中。同源性一般是指两种核酸分子的DNA序列之间或两种蛋白质分子的氨基酸序列之间的相似度。在计算机等信息领域,同源性指的是两个或多个对象具有共同或相似的起源,即使经过了一次或多次迭代(变异),对象之间仍存在某种内在的联系。
常用的文件同源性分析方法有:
(一)字符串常量匹配
相同的源代码对不同平台所编译生成的二进制文件中的机器代码不同,即机器代码具有平台依赖性。但是,针对不同体系架构的交叉编译器在编译同一份源代码时,其中的字符串常量一般不会进行变化,所以,相同的一份源代码对不同平台所编译生成的二进制文件中的字符串常量信息是基本一致的。这就使得字符串常量可以作为不同架构下第三方程序同源性分析中的指纹特征。大致步骤为:提取固件中包含的二进制程序、共享对象、脚本文件,搜索其中的字符串,包含硬编码的字符串、调试信息、版本号等,作为该文件的指纹。将该文件的指纹特征与数据库中的指纹特征进行比较,若与某个数据库中第三方程序或文件相匹配的字符串达到了某个阈值,则认为两文件同源的可能性较大。在进行字符串常量提取时,常使用Unix/Linux系统自带的strings工具。使用如下公式度量文件x和y之间的相似程度:
其中,y为对照文件,表示文件x包含的字符串,I为指示函数(Indicator Function),,。
(二)二进制差量分析
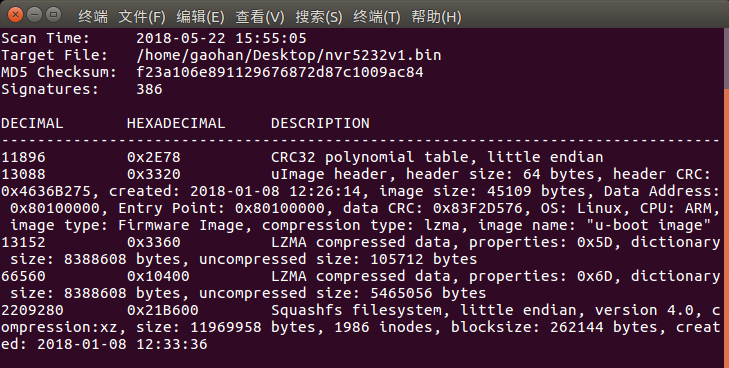
二进制差量的原理是发现两个文件在字节水平的差异,并将其打包成为一个增量包。较多应用于Android移动应用程序的更新,大致步骤为:使用工具生成新、旧两个安装文件的增量包,用户更新应用程序时只需要下载增量包,再在手机端将差分补丁与需要更新的二进制程序进行结合,从而得到一个新版本的应用程序。借助该思想可以计算相近固件版本中的二进制程序增量,若两个文件之间的增量较小,则可认为两文件有较大可能同源。
在进行二进制差量分析时,常用开源的bsdiff程序。使用以下公式度量文件x和y之间的同源性程度:
其中,y为对照文件,表示x和y之间的二进制增量;表示空文件和y之间的二进制增量;。趋向0表示x与y的同源程度较大,趋向1表示x与y同源程度较小。
(三)模糊哈希
模糊哈希算法(Fuzzy Hashing)又称为基于文本的分片哈希算法,主要用于文件的相似性比较、开源软件漏洞挖掘、恶意代码检测、数据泄密防护系统开发等。模糊哈希的实施过程是,首先用一个简单的单向散列函数(Alder-32等)计算文件的局部内容,然后使用“滚动哈希”等方法对文件分片,再使用另一个复杂的单向散列函数(MD5,SHA-1等)对文件每片计算哈希值,截取这些值的部分内容连接起来,与分片条件(滚动哈希方法)一起构成最终的模糊哈希结果。最后使用字符串相似性对比算法(如编辑距离)计算两个模糊哈希值的相似度,从而判断两个文件的相似程度。模糊哈希对文件的部分变化(如在多出修改、增加、删除内容)均能发现与源文件的相似关系,在判断同源性问题上效果较好。
本文使用ssdeep程序计算不同程序之间的模糊哈希,映射到。
表示x和y的模糊哈希相似度。趋向于100表示x和y相似度较高,趋向于0表示x和y相似度较低。
2.2 网络数据采集
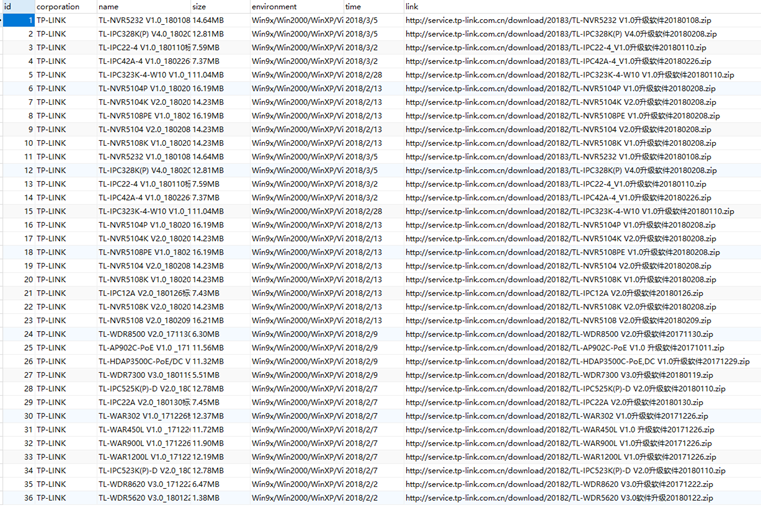
网络数据采集的含义为:通过编程手段收集网络中现有的数据。一般而言,最常用的方法是写一个自动化的程序向网络服务器请求数据,然后对返回的数据进行解析,进而提取出需要的信息。网络数据采集工作涉及到的相关前置知识较多,如HTTP协议相关、网站前端技术、数据清洗技术、数据库技术等。且不同的网站对于用户的限制也不同,部分网站出于自身安全考虑,引入了Web应用防护系统(Web Application Firewall),对用户的请求频率和行为进行了限制,开发者需要使用一定手段绕过网站限制才能获取到需要的数据,这就导致网络数据采集工作变得十分复杂。
本文使用Python3作为开发语言,通过request库进行HTTP网络请求,并使用BeautifulSoup4库完成HTML数据的解析,提取出路由器固件的相关信息,最后使用pymysql库将信息分类存放入MySQL数据库中。
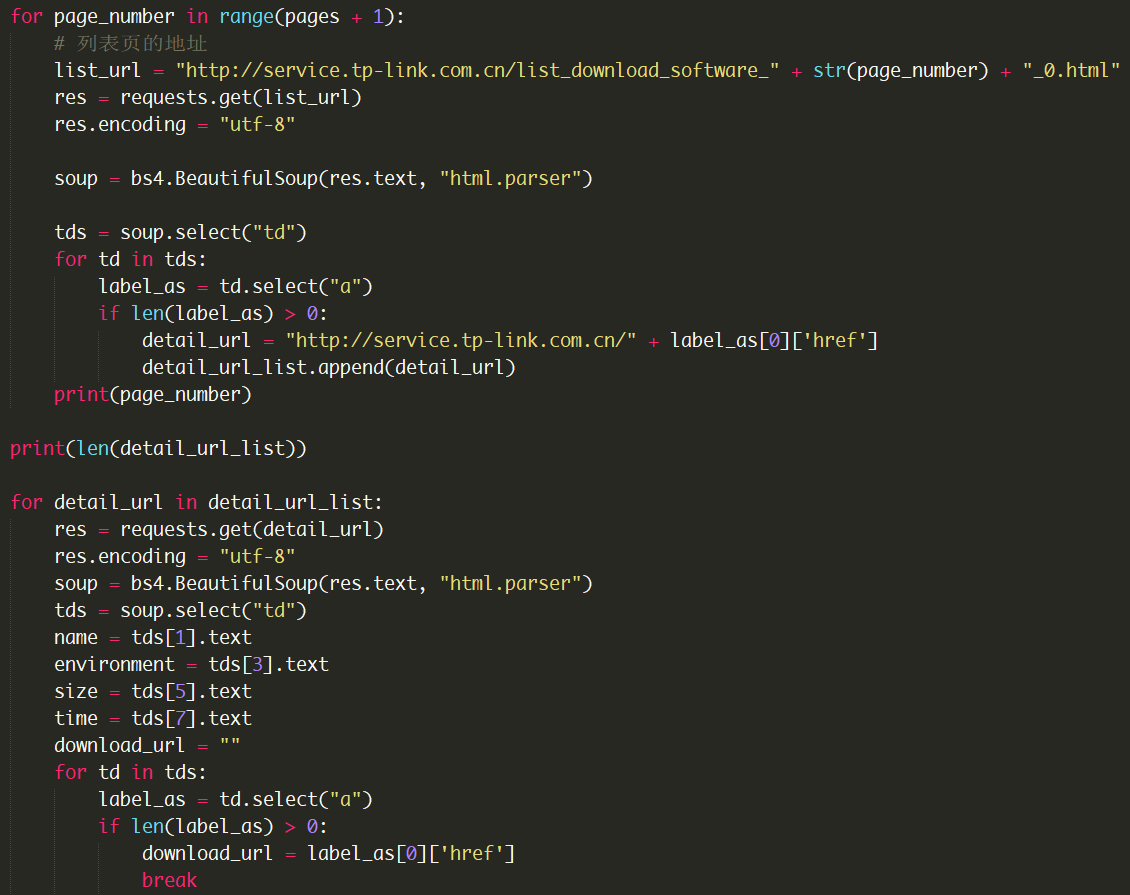
图2.1 Python采集程序的部分代码
2.3 在线平台开发技术
本文使用PHP语言作为在线平台的开发语言,PHP是一种服务器端面向对象编程语言。平台的运行过程中,需要调用服务器本地的程序进行字符串提取、二进制差量分析、模糊哈希计算等。PHP与strings、binwalk、sed等本地程序的输入输出使用Linux PipeLine(管道)连接。平台基本运行流程如下:
用户上传文件到服务器。用户登录平台,选择一种操作,并将需要分析的文件上传到服务器。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: