图像哈希检索方法研究毕业论文
2020-02-23 18:22:18
摘 要
随着全球互联网技术的飞速发展,越来越多的图像被上传到互联网,每个人每天接触到的图片数量迅速增长,人们对于图像检索的要求也越来越高。为了解决大规模图像检索问题,普遍采用基于哈希的图像检索算法,然而检索的准确率还是无法让人们满意。如何提高哈希图像检索方法的准确率是一个难题,本文针对这一问题展开了研究。
近年来哈希算法在图像检索领域得到了越来越广泛的运用。本文在传统迭代量化哈希方法与多特征哈希方法的基础之上提出了一种多特征迭代哈希图像检索方法。传统方法采用的单一特征不能完整的表达一幅图像的内容信息,本文提出采用多特征迭代哈希方法来实现大规模图像的快速检索。本文提出的多特征迭代哈希方法通过学习数据的几个特征上的紧凑哈希码,同时考虑到了不同特征对应哈希码的关系,最后通过迭代量化的方法得到最优的哈希码,将检索结果按相似度从大到小依次排列。
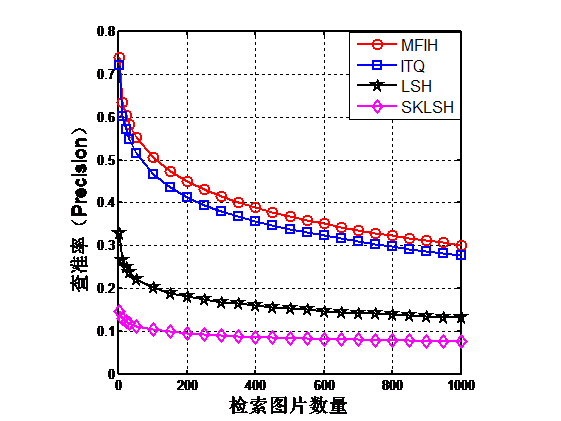
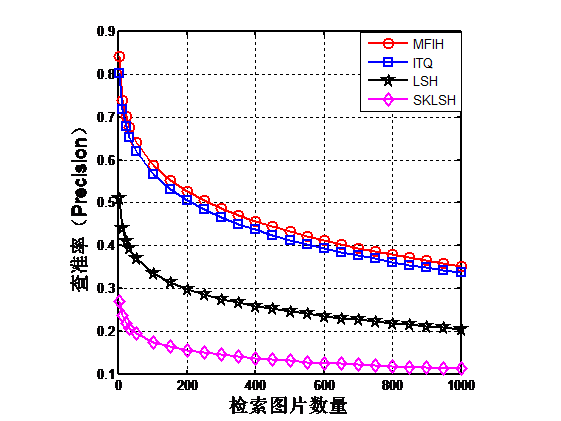
本文在公开的CIFAR-10数据集上对该算法进行了实验,实验证明该方法检索准确率优于迭代量化哈希、位置敏感哈希、移不变核位置敏感哈希这三种单特征哈希方法。
关键词:图像检索;哈希;多特征;迭代量化
Abstract
With the rapid development of global Internet technology, more and more images are uploaded to the Internet, and the number of pictures that each person encounters each day increases rapidly, and people's requirements for image retrieval are also increasing. In order to solve the problem of large-scale image retrieval, hash-based image retrieval algorithms are commonly used. However, the accuracy of retrieval cannot satisfy people. How to improve the accuracy of the hash image retrieval method is a difficult problem. This article focuses on this issue.
In recent years, the hash algorithm has been more and more widely used in the field of image retrieval. This paper proposes a multi-feature iterative hash image retrieval method based on the traditional iterative quantification hash method and multi-feature hash method. The single feature adopted by the traditional method can not completely express the content information of an image. This paper proposes to use a multi-feature iterative hashing method to achieve fast retrieval of large-scale images. The multi-feature iterative hashing method proposed in this paper learns the compact hash code on several features of the data, taking into account the relationship between different features and the corresponding hash code. Finally, an iterative quantization method is used to obtain the optimal hash code. The search results are ranked in descending order of similarity.
In this paper, the algorithm is tested on the published CIFAR-10 data set. Experiments show that this method has better retrieval accuracy than iteratively quantized hash, position-sensitive hash, and shift-invariant position-sensitive hash. Greek method.
Key Words:Image Retrieval;Hashing;Multi-Future;Iterative quantization;
目 录
摘 要 I
Abstract II
第1章绪论 1
1.1研究背景及意义 1
1.2发展现状及问题 2
1.3本文主要内容及结构 3
第2章哈希图像检索相关知识 5
2.1图像检索基础知识 5
2.1.1基于文本的图像检索 5
2.1.2基于内容的图像检索 6
2.2图像的特征提取 7
2.2.1颜色特征 7
2.2.2纹理特征 7
2.2.3形状特征 8
2.3图像哈希算法 8
2.3.1位置敏感哈希(LSH) 9
2.3.2谱哈希(SH) 10
2.3.3锚点图哈希(AGH) 10
2.4本章小结 11
第3章 多特征迭代哈希方法设计与实现 12
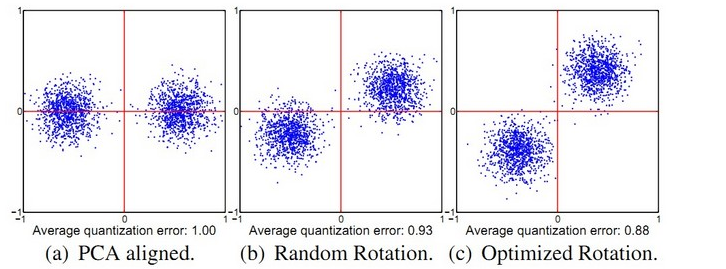
3.1迭代量化哈希(ITQ) 12
3.2符号与标记 13
3.3目标函数 13
3.4迭代求解 14
3.5本章小结 15
第4章 实验与分析 16
4.1实验环境及参数 16
4.2实验性能评价 16
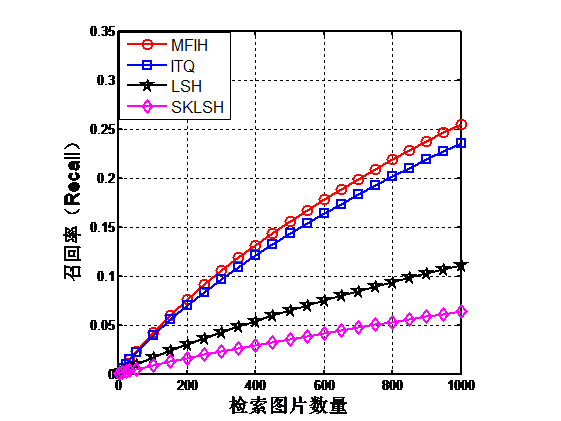
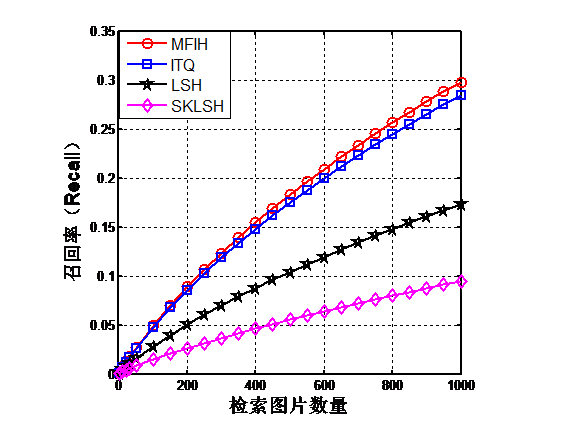
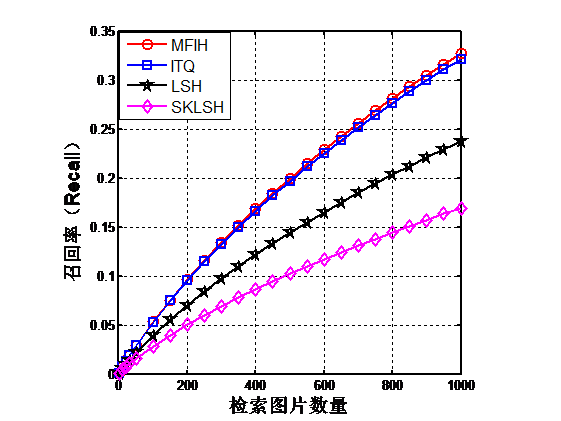
4.3实验结果分析 17
4.4本章小结 18
第5章总结与展望 19
5.1总结 19
5.2展望 19
参 考 文 献 20
致 谢 22
第1章绪论
1.1研究背景及意义
随着多媒体技术和互联网的快速发展,图像信息资源的检索已成为国内外的热门话题。如何建立高效的图像描述和图像的检索机制已经变得很关键。原始数据是知识的来源,它可以是结构化的(数据库中的数据),半结构化(文本,图像,图形)数据,也可以是分布在网络上的不同构型的数据。图像的信息检索技术经历了从文本特征到图像表层特征,再到基于语义的图像特征三个阶段。
鉴于基于内容的图像检索发展越来越成熟,在以下领域的应用也越来越广泛:
- 新一代图像搜索引擎
网络正逐渐渗透到每个人的日常生活中,网络上存在着非常丰富的图像资源,传统的文本图像搜索引擎已经无法满足人们的需求,基于图像内容检索系统的出现,让用户可以直接用图片搜索图片,得到自己想要的文本及图片资源。常用的搜索引擎包括:百度识图、google、360图片搜索、bing等等。
- 知识产权保护
科技的飞速发展使得人们越来越关注知识产权的保护问题。许多知识产权的载体都是图像,商标和艺术作品是其中最为突出的两个方面。商标的知识产权体主要分为专文字描述和图形标记两个方面。为了防止发生商标知识产权的侵权,新申请的商标需要通过严格的审查程序来确认是否侵犯了已注册商标的知识产权。将新申请的商标与已经注册的商标进行对比、审查就需要用到基于内容的图像检索技术。显而易见,基于内容的图像检索技术对于实现商标的专用图形标记的自动审查具有不可或缺的作用。
- 建筑和工程设计
建筑与工程设计有一个相同点就是用二维的图像来表示立体的建筑或工程。设计师们可以通过在网上查找一些他人的优秀作品增添自己的创作灵感,同时一些标准化的照片对于设计也很重要。但目前,这些方面的发展都比较不成熟,因此大力发展基于建筑与工程设计的图像检索系统、建筑和工程集队建筑设计师与工程设计工程师来说就是一个亟待需解决的问题。开发基于内容的建筑与工程谁的图像检索能够很好的解决这方面的问题。
- 公安系统
公安系统中保存着大量图像信息,包括每个人的照片、指纹和胶印等等。如果有人发生了犯罪行为,只要犯罪嫌疑人留下了指纹等相关证据,公安的工作人员就能通过运行公安内部图像检索系统,快速锁定犯罪嫌疑人的身份,并且获得其过去的犯罪记录等等,从而加快案件的侦破过程。
基于内容的图像检索的应用还有许多,包括服装设计、家居装潢设计、远程教育以及个人相册管理等等血多方面。
当前图像检索的研究主要有两个方向,第一是寻求更好的特征描述匹配图像的内容来适应不同检索场景的需要;第二是提高图像检索算法的效率和准确性。在互联网日益普及和多媒体全面覆盖人们生活的今天。如何通过各种媒介迅速准确地让人们得到所需要的信息就显得至关重要。因此我们必须在基于内容的图像检索任务上进行更深入的研究,为人民生活需要做出自己的贡献。
1.2发展现状及问题
在20世纪70年代末,通过文本注释和文本检索手动搜索文本特征。这种使用图像关键词等文字描述信息的方法已经越来越不适应网络信息检索的要求,这不仅费时费力,而且文字难以反映图像中的完整内容。
在20世纪90年代前后,随着大规模图像采集的不断普及和完善,各国的研究人员先后提出了基于内容的图像检索(CBIR)[1][2]。CBIR采用的诸如颜色[3],纹理[4],形状[5]等视觉特征已经逐渐成为图像检索技术研究的主流。根据大图像集中的图像检索实例,实现了图像视觉内容特征的检索。根据图像的表面视觉特征搜索不满足基于图像语义的智能检索的需要[6]。语义图像检索变得越来越关键。这也是计算机视觉和模式识别领域的难点。
最早的哈希图像检索方法是Indyk等人在1998年提出的位置敏感哈希方法[7][8](Locality Sensitive Hashing,LSH)。局部敏感哈希方法是最早应用于图像检索的哈希方法,位置敏感哈希主要用来解决高维空间中点的近似最近邻搜索问题(Approximate Nearest Neighbor)。这种方法将原始空间中的点嵌入到汉明空间中,即原始空间中点的表达形式转换成汉明空间中点的表达形式,原始空间中的距离度量转换成汉明空间中的距离度量。该方法适用于解决不要求得精确解,只需要得到近似解的问题。它的优点是简单、速度快,但检索结果并不是很理想。Ji等人在原LSH算法的基础上改进出了超比特局部敏感哈希方法[9](Super-Bit Locality-Sensitive Hashing,SBLSH),这个方法用了角度来进行相似性度量,通过对随机投影向量的分组,再对其正交化,而正交化的汉明距离比原LSH的汉明距离小,从而提升了代码质量。但SBLSH和LSH一样都是非数据驱动方法,检索的准确率仍然较低。对于它们来说,如果想要提高检索的准确率,就必须增加哈希码长度,但是这会导致存储空间大大上升,这与哈希图像检索技术的初衷相悖。
为了能解决上述问题,得到紧凑的哈希编码,Kulis等人在局部敏感哈希的基础上引入了核函数,提出了核化位置敏感哈希方法[10],(Kernelized Locality-Sensitive Hashing,KLSH ),这个方法采用核函数对LSH泛华和扩展,并对图像库处理构造哈希函数,由于这个方法对数据进行了关联,提高了图像检索的准确率。但是因为引进了核函数,增加了计算的复杂度,实现也变得更加复杂。而Wiess等人将图论知识与哈希方法结合,提出了谱哈希方法[11](Spectral Hashing,SH),该方法用图的分割方式来实现哈希函数的学习过程,采用了拉普拉斯矩阵,使哈希函数为矩阵的门线特征向量的子集。SH方法与LSH与SBLSH不同,是数据驱动型算法,保留了数据的相关性,提高了检索准确率。之后Liu等人在谱哈希的基础上引入了锚概念,提出了锚点图哈希方法[12](Anchor Graph Hashing,AGH),AGH与SH一样都采用拉普拉斯矩阵获取哈希码并且两者都是数据驱动型算法,检索准确率较高,AGH与SH不同之处在于AGH通过对数据构建二分图生成近邻矩阵。因为大规模的数据存在结构性,所以数据驱动型哈希方法能够实现快速图像检索。
图像数据除了其本身具有的信息,还具有一些附加信息,在机器学习和模式识别等领域具有重要作用。因此,人们对这类哈希函数学习方法也进行了研究。Jun Wang等人提出了顺序投影学习哈希方法[13][14](Sequential Projection Learning for Hashing,SPLH),SPLH按照顺序获得每一个投影向量,每获得一个投影向量,就对错误项进行更新,防止在下一次投影中发生更大的错误。Norouzi等人提出了一种最小损失哈希[15](Minimal Loss Hashing,MLH),该方法是一种建立在结构化支持向量机[16]基础之上的监督学习哈希。
1.3本文主要内容及结构
第1章绪论部分,首先简单介绍了图像检索技术的研究背景及意义,然后介绍了图像检索的发展现状和面临的问题,并对本文这要内容及结构作了介绍。
第2章对基于内容的图像检索相关的知识进行了系统描述,先介绍了两种不同的图像检索方法:基于文本的图像检索和基于内容的图像检索,然后介绍了图像特征的提取,包括颜色特征,纹理特征和形状特征。最后对图像哈希方法进行了介绍,列举了置敏感哈希(LSH),谱哈希(SH),锚点图哈希(AGH)几种典型的哈希图像检索方法。
第3章是本文的核心,在前人的迭代量化哈希方法与多特征哈希方法基础上提出了一种多特征迭代哈希方法,重点讲解了该方法的设计与实现过程。
第4章将本文提出的多特征迭代哈希方法(MFIH)与迭代量化哈希方法(ITQ),位置敏感哈希方法(LSH)和移不变核位置敏感哈希(SKLSH)在公开数据集CIFAR-10上进行对比实验,实验证明本文提出的算法要优于其它算法
第5章对前面的内容进行了总结,并对哈希图像检索的发展进行了展望。
第2章哈希图像检索相关知识
2.1图像检索基础知识
从图形检索的发展历史看,图形检索方式主要分为两种:基于文本的图像检索(Text-based Image Retrieval,TBIR)和基于内容的图像检索[17](Content-based Image Retrieval,CBIR)。
2.1.1基于文本的图像检索
基于文本的图像检索(Text based Image Retrieval,TBIR)技术研究始于20世纪70年代末期,数字图像数据刚开始发展,图像数据集的规模还不算太大。它是利用文本或关键字对数据库中存储的图像进行描述,将图像的存储路径与图像关键词建立对应联系。在检索过程中,基于文本的图像检索将已经较成熟的传统文本检索技术直接移植到图像检索上,进而将图像检索问题转化为对图像所关联的关键字的查找。本质上,这是一种关键字的匹配和查找。
基于文本的图像检索首先要有专业的人员预先对新加入图像数据库中的图像一一进行文本标注,之后用户才能通过输入关键字对数据库中所包含的图像进行查找。总体而言,基于文本的图像检索主要包括以下两个步骤:
第一步,对图像文件标注相应的关键词或描述字段,建立图像索引数据库。通常是依据图像的名称、编号、内容、大小、来源、所在位置、作者和拍摄时间等信息,一般采用人工标注的方法建立对应文本描述信息,同时进行图像特征提取,以此建立图像索引数据库。
第二步,使用建立的文本数据的检索方式对用户所输入的信息进行全数据库的匹配、查找。
整个检索过程如图2.1所示。
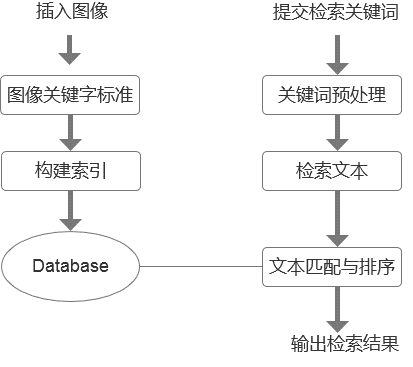
图2.1 基于文本的图像检索流程图
2.1.2基于内容的图像检索
由于基于文本的图像检索的质量较差而且不稳定,并且随着图像数量的不断增加,这种检索方法的缺点变得愈发明显。为了解决基于文本的图像检索技术的缺点,上个世纪八十年代前后出现了基于内容的图像检索(Content-based Image Retrieval,CBIR)。基于内容的图像检索的查询条件本身就是一个图像或是对于图像的描述,这种检索方法建立索引的方式是先提取图像特征,然后计算这些特征与查询条件间的距离,通过这些距离来判断两个图像的相似程度。检索过程如图2.2所示。
基于内容的图像检索方式和基于文本的图像检索相比,具有以下特点:
(1)直接从图像内容中提取特征线索。
(2)检索方式多样。包括基于草图、基于检索实例等许多检索方式。
(3)采用相似性匹配检索。基于内容的图像检索通过匹配算法将输入的图像特征与库中的元数据进行相似度匹配,按照相似度大小将结果排列,返回给用户。
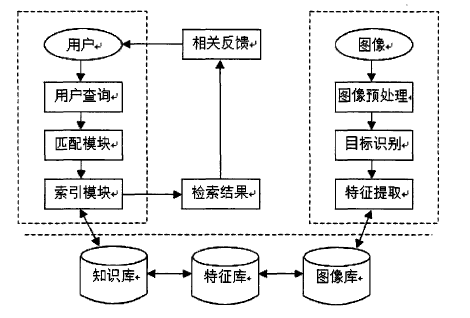
图2.2 基于内容的图像检索流程图
2.2图像的特征提取
基于内容的图像检索是通过提取图像的颜色、形状、纹理等特征对视觉内容进行表征。在检索的过程中,相似度对比是建立在特征提取的基础之上的,如果提取的特征不能很好的反应图像内容,就可能搜索到与所查图像不相似的图像。所以,如何准确提取图像特征就变得非常关键。
2.2.1颜色特征
颜色特征是图像最显著的特征,由于颜色特征计算简单,具有很强的鲁棒性,是基于内容的图像检索系统中应用很多的一种特征,常见的颜色特征包括RGB空间、HSV颜色空间、CMY颜色空间等。常见的颜色特征有颜色直方图,颜色布局,颜色矩等等。
但由于颜色特征无法考虑到人眼对于不同空间、比例相同的颜色的感受差异,而且颜色特征只能识别出具有相同颜色分布的图像,所以颜色特征经常作为图像检索系统中的初级特征表示。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: