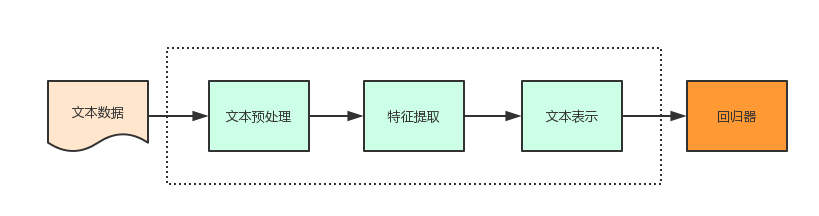
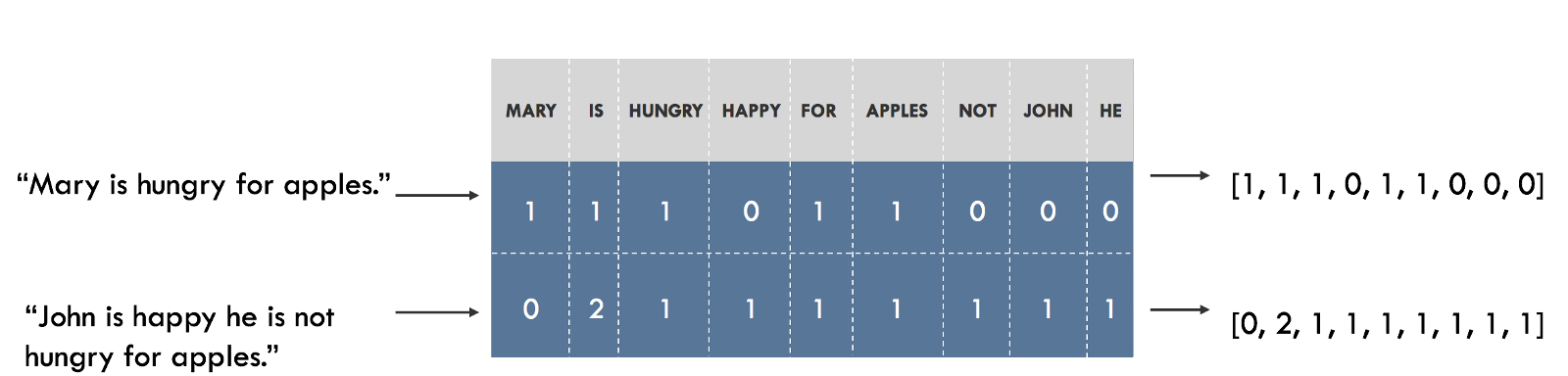
基于多因子融合的问答流行度预测方法设计与实现毕业论文
2020-02-23 18:21:02
摘 要
社区问答网站正日益成为重要的信息来源。由于在社区问答网站中的快速增长的问题和答案数量,保证高质量的内容的同时,提高信息的传播效果也显得越发重要。
本文通过多因子特征融合,预测答案在社区问答网站的流行度(例如有多少人点赞等),了解什么样的内容更适合网站,从而尽早发现网站中流行度高的答案,使得网站获得积极的反馈。预测答案流行度的好处在于不用细化到具体问题,网站可以按预流行度在首页推送问题-答案对,提高网站的传播互动效果。
对于社区问答网站,现有的大多数文章都在基于深层语义匹配模型的基础上预测所需结果,近期也有部分文章开始考虑回答问题的用户对于结果的影响。本文除了以上因素之外,还考虑了提问者对于问答整体流行度的影响。
本文在Stack Exchange 的真实数据集上进行了实验,实验结果表明论文方法的有效性。
关键词:特征设计;文本特征;线性回归;卷积神经网络;长短记忆网络
Abstract
Community question and answer websites are increasingly becoming an important source of information. Due to the rapidly growing number of questions and answers in community question and answer websites, it is increasingly important to improve the dissemination of information while ensuring high quality content.
This article uses multifactorial feature fusion to predict the popularity of answers in community Qamp;A sites (for example, how many people like it, etc.) and understand what kind of content is more suitable for websites, so as to find out the popular answers in the site as soon as possible, and make the site active. feedback of. The advantage of predicting the popularity of answers is that they do not need to be detailed to specific issues. The website can push question-answer pairs on the front page according to pre-popularity to improve the effectiveness of the site's communication and interaction.
For the community question and answer website, most of the existing articles are based on deep semantic matching model to predict the desired results, and some articles have recently begun to consider the impact of the user who answers the question on the results. In addition to the above factors, this paper also considers the questioner's influence on the overall popularity of the question and answer.
This article has conducted experiments on the real dataset of Stack Exchange. The experimental results show the effectiveness of the proposed method.
Key Words:Feature design; text feature; Linear Regression; Convolutional Neural Network; Long Short Term Memory
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 研究现状 2
1.3 本文工作 3
1.4 本文结构 3
第2章 数据说明与数据预处理 5
2.1 数据集说明 5
2.2数据预处理 7
第3章 非文本特征与文本特征提取 8
3.1 非文本特征提取 8
3.2文本特征提取 10
3.2.1 文本预处理 10
3.2.2 BOW 11
3.2.3 TF-IDF 11
3.2.4 Word2Vec 13
3.3 本章小结 14
第4章 流行度预测方法 16
4.1 模型概述 16
4.1.1 线性回归 16
4.1.2 随机森林回归 17
4.1.3 神经网络 17
4.2 实验设计 20
4.2.1 实验设置 20
4.2.2 实验结果 23
第5章 结论 26
5.1 总结 26
5.2 展望 26
参考文献 28
致 谢 31
第1章 绪论
1.1 研究背景
互联网改变了人们提供、搜索和分享信息和知识的方式。在搜索引擎中直接提交关键字来表达需求,搜索引擎会立即列出大量或多或少与需求关联的网页供用户选择。但是,搜索结果可能无法为用户的问题提供确切的解决方案,并且查看所有这些内容可能非常耗时,同时无法保证用户能够找到所需的答案。2002年,问答网站Naver[1]的出现,奠定了现代社区问答的基础。社区问答(CQA)网站的发展引人注目,它为用户提供了一个以更快速和更有效的方式获得所需知识的选择。
CQA是社区问答(Community Question Answering)的简称,它允许用户向其他用户发布问题从而从其他用户那里获取答案[1]。社区问答网站为用户交流和分享知识提供了一个平台,用户可以提问并回答问题,并为这些问题以及答案提供反馈(例如通过投票或评论)[2]。它旨在提供基于社区的知识创造服务,任何人都可以成为内容的创造者和获取者,所以内容的发布更自由,交换更快捷,增长更迅速。一个社区中的用户可以被分为三种类型:1)只提出问题的用户,2)只回答问题的用户,3)提出问题并回答问题的用户[3]。缺少某个特定领域的知识的提问者向熟悉该领域的用户提问以解决问题。提问者通过这种方式获取所需知识,替代其他的信息来源,如搜索文档或数据库。
随着互联网的快速发展,社区问答网站的价值已经得到了广泛认可[4],社区问答网站正日益成为重要的信息来源,用户可以在这些网站上分享了解各种主题的知识。社区问答网站发展至今数目众多,国外著名的社区问答网站主要有:Yahoo!Answer[2],Quora[3],Stack Overflow[4]等,国内著名的社区问答网站主要有:百度知道[5],知乎[6]和爱问知识人[7]等。据估计,在社区问答网站上的问题数量已经超过图书馆参考服务回答的问题数量[5]。社区问答网站因此吸引了众多研究者的目光。
与搜索引擎只提供匹配用户检索的关联信息不同,社区问答网站具有自己独特的社区属性。1)它能够直接解决用户的问题,有更明确的解决问题的属性,2)社区问答网站上的问题有相当一部分是人们共同关心的问题,一个好的回答能够帮助很多拥有相同问题的人,即好的回答可以被长期重复利用,3)网站内容的传递是双向的,内容在提问者和回答者之间传递。
而社区问答网站和传统的问答网站之间的一个主要区别在于用户本身对网站的影响。除了发布问题/答案之外,大多数现有的社区问答网站都允许网站用户对这些问题/答案进行投票(例如支持或不支持)。一方面,投票机制及其声誉体系为全网站的紧密参与和生产性竞争提供了主要动力。另一方面,这种投票的结果,例如问题/答案从网站用户收到的支持和不支持的数量之间的差异(称为“投票得分”),为网站提供了一个好的内在指标用以评价问题/答案的价值[2]。在某种程度上,问题/答案的投票得分类似于论文收到的引用次数,反映了对问题/答案持积极态度的用户净数量。
由于社区问答网站数量众多,一个社区问答网站需要保证高质量的内容以区分其他网站,这就需要维持用户的活跃度,吸引更多的用户参与到问题的回答中,网站拥有的内容越多,高质量的内容才会越多,也能吸引更多的用户,达到良性循环[6]。社区问答网站在满足用户的信息获取需求的同时,网站中快速增长的问题和答案数量,提高内容的传播效果也显得越发重要。
因此,社区问答网站需要了解什么样的内容更适合网站。使用流行度(如答案获得的投票得分)作为指标对答案进行排序,可以判断问答对是否适合网站,这对于网站来说具有重要价值。通过流量的分发控制,网站使得有潜力的问题-答案对可以在前期获得更多的曝光,提高了传播互动量,同时提高了用户的积极性,促使用户提供更多的内容。
1.2 研究现状
近年来社区问答网站中的问题和答案库快速增长,积累了数以万计的问题答案对。社区问答网站也因此吸引了众多研究者的目光。在社区问答领域中,给定一个问题数据(包含问题和答案等信息),预测答案的排序是一个热门方向。预测答案排序的主要目的是得到质量最佳的答案。答案质量的定义可能是与问题相关性最高的,也可能是影响力最大的,或多种因素综合考虑得到。尽管对答案质量定义的并不统一,但高质量的答案的重要性已在大量的研究中得到认可[7][8][9]。在实际应用中,答案排序不仅根据答案的内容,也会参考答案的元数据(如答案的投票得分、用户的权威性等)对答案进行排序。
在已有的研究中,大多数文章都在基于语义匹配模型的基础上预测答案的排序[10],即学习问题与答案的语义和句法的匹配程度。使用传统的自然语言处理方法的工作有很多。例如文勖[11]提出改进的编辑距离与向量空间模型相结合的方法,在一定程度上克服了简单词袋模型的缺点。Qin等人[12]通过计算问题和答案的主题语义距离来对答案进行排序。
随着深度学习的快速发展,深度学习模型在预测答案排序的探索获得了广泛关注。Hu等人[13]提出了多层的卷积神经网络捕获不同层次上的语句匹配模型。Wang等人[14]采用了长短记忆网络(LSTM),首先序列化读取问题和答案语句的词语,然后输出问题和答案的联合表示来预测答案的排序。该方法先应用CNN学习问题和答案的联合表示,然后将这作为LSTM模型的输入来标记问题中每个答案的匹配程度。为了进一步捕捉语句间的语义相关信息,Qiu等人[15]提出将卷积神经张量网络首先进行卷积和池化操作得到问题和答案固定长度的向量表示,如何通过加入一层张量层对它们进行交互。Yin等人[16]通过构建语句对词层面和语句层面的关注矩阵来学习语句间的关系。
用户是社区问答网站中的核心角色,因此近期也有部分文章在基于语义匹配模型的基础上开始考虑提供答案的用户的权威性对答案排序的影响[17]。Suryanto等人[18]将用户的权威性应用到了问题和回答的搜索中。Li等人[19]提出了一种将问题发送到权威回答者的方法。Zhao等人[20]将回答者的权威性和问答之间的相关性用非对称的深度学习框架结合在一起来解决回答质量评估的问题。
1.3 本文工作
本文根据答案的流行度(如答案的投票得分)来判断问答对是否适合网站,通过尽早发现网站中流行度高的答案,使得网站获得积极的反馈。这本质上仍然是一个排序问题。给定一个问题,预测答案的质量排序是CQA领域中的重要方向。在已有的研究中,大多数文章都在基于深层语义匹配模型的基础上预测答案的质量排序[10],近期也有部分文章开始考虑提供答案的用户的权威性对答案排序的影响[17]。预测答案的流行度与预测某一答案在一个问题下的排序不同,考虑的是问题和答案对在社区问答网站中的流行度,因此除了考虑预测答案质量排序时需要考虑的所有因素之外,本文还考虑了提问者对于问答整体流行度的影响。
本文试图通过多因子特征融合的方法,预测答案在社区问答网站的流行度。多因子是指考虑的因素较多,包括问题、答案和用户等信息。显然,答案和问题的流行度具有高度相关性,流行度高的答案会吸引更多的用户回答,使得该问题的影响力更大。高影响力的问题预计会吸引更多的用户注意力,有更多的答案尝试,使得问题能够在短时间内获得最佳的答案。
通过预测流行度高的答案可以帮助社区问答网站发现用户广泛认可的高影响力的内容。预测答案流行度的好处在于不用细化到具体问题,网站可以按预测的流行度在首页推送问题-答案对。通过流量的分发控制,网站使得有潜力的问题-答案对可以在前期获得更多的曝光,提高传播互动量,同时提高用户的积极性,促使用户提供更多的内容。这同时也增加了高质量内容产生的概率,它们一方面可以帮助用户有效解决问题,另一方面丰富社区的知识储备。
本文在Stack Exchange 的真实数据集上进行了实验,实验结果表明论文方法的有效性。
1.4 本文结构
本文共有五个章节,具体的组织结构安排如下:
第一章介绍了社区问答网站的定义及其研究背景和意义,并介绍了研究现状与本文的研究工作。
第二章介绍了本文使用的实验数据集以及对于实验数据的预处理。
第三章主要是特征提取的工作,包括非文本特征以及文本特征,为后续的模型学习做准备。并介绍了文本特征提取的三种基本方法。
第四章探索了特征组合输入对流行度预测的影响。实验使用三种常见的回归模型,分别是传统机器学习中的线形回归模型、随机森林模型以及神经网络模型,并对实验结果进行了对比。
第五章对研究工作进行了总结,并指出不足之处和进一步的研究方向。
第2章 数据说明与数据预处理
2.1 数据集说明
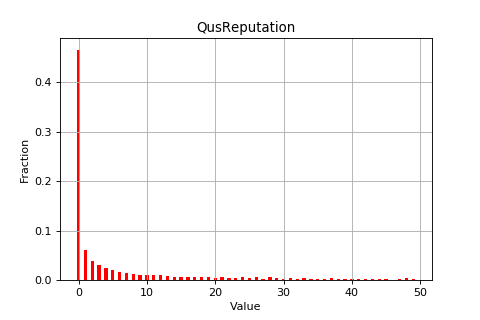
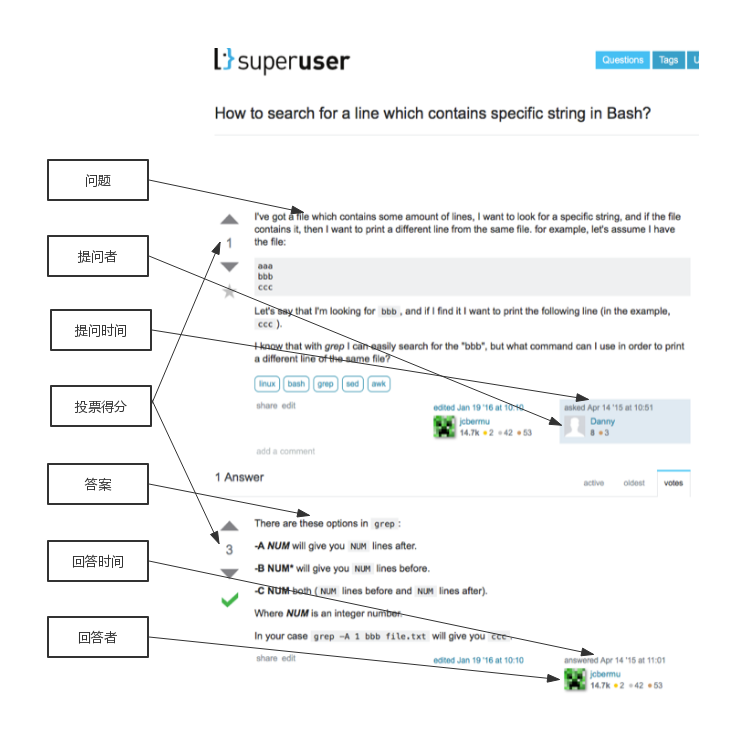 图2.1 Superuser网站问答实例
图2.1 Superuser网站问答实例
本文使用的数据集来自Internet Archive[8],该网站是一个数据图书馆,Stack Exchange所有网站的截止至2018年3月的历史问答数据都可以从中下载。Stack Exchange是一系列社区问答网站,每一个网站包含不同领域的问题。著名的Stack Overflow网站是Stack Exchange系列网站的第一个成员[7]。
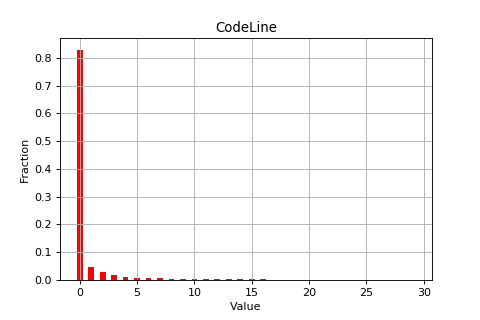
由于Stack Overflow网站的问答数量据过于庞大(遍历该站点文件可知,仅2012年就包含1646361个问题,2843917个答案),受条件限制处理数据需要耗费较长时间,而另外的大部分网站的数据不够丰富。从实验进度和实验效果考虑两个方面考虑,本文选取的数据集来自网站Superuser[9],与Stack Overflow同意属于Stack Exchange系列网站,从表2.1可知该数据集包含了370840个问题,550348个答案。图2.1为Superuser网站的一个问答实例,图中标注了一些基本属性,下文它们会被经常提及:问题、提问者、提问时间、答案、回答者、回答时间、投票得分等。
表2.1 superuser网站数据集大小
类别 | 数量 |
问题 | 370840 |
答案 | 550348 |
Internet Archive中每个网站的数据存档使用xml格式存储,共包含8个文件,分别为Commments、PostHistory、Posts、Users、Badges、Votes、PostLinks和Tags。本文使用的实验数据来自Superuser网站的Posts文件,文件的结构信息可见表2.2。所有的问题和答案都由root标签中的row标签分隔,每个row标签中包含一个post,即一个问题或答案。
表2.2 Posts文件的信息
属性 | 类型 | 描述 |
Id | Integer | 问题/答案的唯一标识符 |
PostTypeId | Integer | 用于区分问答类型:1代表问题 2代表答案 |
ParentID | Integer | 标识答案属于哪一个问题(问题没有这个属性) |
AcceptedAnswerId | Id | 问题接受的答案(答案没有这个属性) |
CreationDate | Datatime | 问答的创建时间 |
Score | Integer | 问答的投票得分(支持 1,不支持-1) |
Body | String | 问答的文本 |
OwnerUserId | Id | 拥有这个问/答的用户的唯一标识符 |
ViewCount | Integer | 用户查看次数 |
AnswerCount | Integer | 答案数量 |
CommentCount | Integer | 评论数量 |
FavoriteCount | Integer | 喜欢的数量 |
Title | String | 问题的标题 |
2.2数据预处理
原始数据为XML格式,这种格式处理速度慢,且读取不方便,所以需要格式转换,本文在数据的处理过程中,按需将其转存为csv、pkl和json格式的文件,便于之后实验合并、读取数据。
对于原始数据,显然需要放弃一部分无法帮助回归器预测答案流行度的属性。但这必须谨慎选择,虽然有些功能不直接影响回归,但仍然需要保留。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: