基于机器学习的文本内容识别分类系统——识别模块毕业论文
2020-02-23 18:19:24
摘 要
在现在这个信息技术高速发展的时代,人们都开始选择使用网络来进行信息交流,这就导致了文本数据的爆炸式增长,如何处理这些数量庞大的文本数据成为了一个难题。传统的处理文本的方法显然早已经无法满足日益增长的需求,人们急需一种方法来对文本进行快速而且准确分类管理。而基于机器学习的文本分类方法,在分类的速度以及分类结果的准确率上相比传统的文本分类方法要更胜一筹。
论文主要介绍了当下较为常用的三种基于机器学习的文本分类算法:朴素贝叶斯算法、K最近邻算法以及支持向量机算法。根据使用不同的数据所获取的实验结果,对三者的分类时间、准确率、召回率以及F1-Score进行分析比较。实验结果表明,朴素贝叶斯算法的分类速度最快,而支持向量机的分类准确率最高。
关键词:文本分类;朴素贝叶斯;K最近邻;支持向量机
Abstract
At the time of the rapid development of the information technology, t people have begun to use the Internet for information exchange, which leads to the explosive growth of text data. How to deal with these huge amounts of text data has become a problem. The traditional method of document processing has apparently been unable to meet the ever-increasing demands and people need a way to classify and manage the document quickly and accurately. The text classification method based on machine learning is superior than the traditional text classification method in terms of the classification efficiency and the accuracy of classification results.
This paper mainly introduces three mainstream text classification algorithms based on machine learning: the Naive Bayes, the K Nearest Neighbor and the Support Vector Machine. According to the experimental results obtained by using different data, the classification time, accuracy, recall rate and F1-Score of the three groups were analyzed and compared. The experimental results show that Naive Bayes algorithm has the fastest classification speed, while support vector machine has the highest classification accuracy.
Keywords:Text classification,Naïve Bayes,K Nearest Neighbor,Support Vector Machine
目录
摘 要 Ⅰ
Abstract Ⅱ
第1章 绪论 1
1.1 研究背景与意义 1
1.2 国内外研究现状 1
1.3 论文研究工作概述 2
1.4 论文组织结构 2
第2章 文本分类基础部分介绍 3
2.1 文本分类的一般过程 3
2.2 中文文本预处理 4
2.2.1 文本标记处理 4
2.2.2 中文分词 4
2.3 文本特征处理 5
2.3.1 文本特征提取 5
2.3.2 特征权重矩阵 6
2.4 本章小结 6
第3章 基于机器学习的文本分类方法 7
3.1 朴素贝叶斯方法 7
3.2 K最近邻方法 7
3.3 支持向量机方法 8
3.4 本章小结 9
第4章 文本分类实验及结果分析 10
4.1 文本分类系统功能介绍 10
4.2 文本分类实现 12
4.2.1 文本语料库 12
4.2.2 文本预处理 12
4.2.3 特征处理 13
4.2.4 分类器训练以及分类 13
4.2.5 分类结果评价 14
4.3 实验结果与分析 14
4.4 本章小结 17
第5章 总结和展望 18
5.1 总结 18
5.2 展望 18
参考文献 19
致谢 20
第1章 绪论
1.1 研究背景与意义
随着信息技术的飞速发展,数字文档信息或者说文本数据,已经成为了互联网时代最为常见的的数据形式之一。与此同时,文本数据的总量也是呈现出指数级的增长,人们已经无法再通过传统的人工操作的方法来对文档以及信息进行处理。所以,人们开始利用能高速运算的计算机来帮助自己对文本数据进行识别以及处理。这不仅解决了传统方法处理文本数据困难的问题,还极大地提高了文本数据处理的效率。
基于这一现状,人们开始研究如何使用计算机对文本数据进行处理,其中包括了信息检索、特征提取、文本分类等研究方向。这些研究的目的都在于帮助人们更加快速高效地对互联网上的文本数据进行搜索、识别、分类,甚至于对其中的特征进行提取。
而在这些研究方向中,文本分类是文本信息处理的一个重要基础,其目的是对已知文本类别的训练集文本进行训练,来构建一个分类器,这个分类器可以根据在新的文本内容中提取出的某些特征,来判断它的类别[1]。传统的文本分类的方法是由人们手工来进行分类,在进行大规模文本数据处理的时候,需要大量的时间和人力,而且因为个人的原因,分类的效果或者说准确度并不能得到很好的保证。而利用高速运算的计算机来进行文本分类,这是一个很好地解决时间和人力问题的方法。20世纪90年代以来,基于机器学习的文本分类算法如朴素贝叶斯、K最近邻、支持向量机等开始广泛被应用,这些方法相较于传统的分类方法,在分类的速度以及精度上都要更胜一筹,取得了很好的分类效果。
1.2 国内外研究现状
1958年,IBM公司科学家H.P.Luhn发表了论文《The Automatic Creation of Literature Abstracts》,并在论文中率先提出了词频统计的方法。在1961年,Maron率先在文本分类中使用到了贝叶斯公式,这一举措对文本分类的研究产生了重要的影响[2]。随后以K.Spark、G.Salton等人为代表的众多学者也开始对文本分类进行研究。60年代一直到80年代,文本分类大多是采用知识工程的方法,即使用人工的方法来构建分类器。直到90年代以后,文本分类开始采用机器学习的方法。基于机器学习的方法不论是在效率上还是在准确率上都要优于传统的文本分类方法,很多机器学习的算法都被应用于文本分类之中,并取得了显著的成果。
由于国内本身技术和环境的限制,文本分类的研究要比国外晚了很多年,1981年侯汉清教授率先对国外的文本分类研究现状进行了介绍和探讨,随后,国内许多学者也开始了文本分类研究。其中比较有代表性的有吴军和王作英所发表的汉语语料自动分类系统,李晓黎、刘继敏和史忠植发表了概念推理网及其在文本分类中的应用,范焱、陈恩红等人在KNN和Bayes的基础上,提出了一种新的协调分类超文本算法。
1.3 论文研究工作概述
论文是对三种常用的基于机器学习的中文文本分类方法的研究,对分类过程中的文本预处理、特征处理以及文本分类进行了系统的探讨,并对其进行了实验分析。论文的主要研究内容是三种较为常见的文本分类算法:朴素贝叶斯、K最近邻和支持向量机。并在深入理解了这三种算法的原理的基础之上,利用实验分析比较了这三种算法之间的优缺点,从而为研究新的算法和对已有算法进行优化打下了基础[3]。
1.4 论文组织结构
论文中的所有内容都集中在文本分类这一个主题上,对文本分类的过程进行了详细地描述,并通过实验来对三种算法进行分析比较。具体来说,论文的组织结构如下:
第一章是“绪论”,主要说明了论文的研究背景与意义,国内外的研究现状以及论文的主要研究内容和组织结构。
第二章是“文本分类基础部分介绍”,主要说明了在进行文本分类之前需要对文本进行的一系列处理,包括文本预处理和特征处理等。
第三章是“基于机器学习的文本分类方法”,主要介绍了三种常见的用于文本分类的机器学习方法。
第四章是“文本分类实验及结果分析”,主要是对三种方法进行文本分类实验,并比较分析了三种方法的实验结果。
第五章是“总结和展望”,主要是对论文所作的工作进行了总结,并提出一些需要改善的地方。
第2章 文本分类基础部分介绍
2.1 文本分类的一般过程
文本分类可以粗略地定义为:在已知训练集文本类别的情况下,可以根据新文本的内容来将该文本归到某一类别。文本分类系统会根据训练集文本的内容和类别归纳出一个分类的规律,然后根据这一规律来判定一个新的文本的类别。文本分类一般包含文本预处理、文本结构化表示、特征处理、训练分类器以及最后对分类结果的评价等。文本分类系统的主要功能为:
- 文本预处理:对训练集和测试集文本进行处理,将文本内容格式进行统一;
- 文本结构化表示:将文本内容结构化;
- 特征处理:从文本中提取特征,并建立权重矩阵;
- 分类器:选择分类算法,对训练集文本进行训练;
- 评价:对分类结果进行评价分析[4]。
文本分类系统的主要功能如图2.1所示:
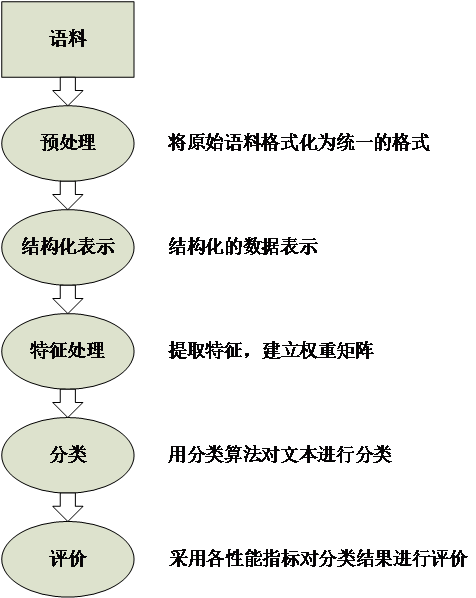
图2.1 文本分类系统的主要功能
2.2 中文文本预处理
文本预处理主要是对内容格式不相同的文本进行处理,使其转化为一个统一的格式,以便后续的统一处理。文本预处理的效果会直接影响到文本分类的精确度,这也是极为重要的一点。
2.2.1 文本标记处理
不同来源的文本,其自身可能带有一些与文本内容无关的标记。这些标记可能是标点符号;也可能是一些其他格式的信息,如图片、声音等;还有可能是一些乱码。这些标记和文本的内容毫无关联,对文本分类也起不到任何的帮助作用。因此应该删除这些无用的标记,将文本内容处理为统一的格式,以便后续地使用[5]。
例如,利用爬虫在网络上爬取下来的数据中,很多内容中都包含网页标签,这些标签都与文本内容无关,需要去除。
2.2.2 中文分词
英文文本中多是利用空格和标点符号来区分每一个词,而中文则不同于英文以及其他语种,中文文本的最小单位是字,由一个或多个字组成了词,中文的词才是有真正的含义,中文文本中标点符号区分的大多数是句子或段落,做不到在词上的区分,所以中文文本需要进行分词操作。并且,由于中文自身的特点,不同的分词方式可能会产生完全不同的含义,所以中文文本的分词处理会比较困难。在这一点上,就比英文文本的预处理要复杂得多[6]。
中文分词算法主要分为三类:利用字符匹配分词、对文本进行理解分词以及对文本进行统计分词。
字符匹配分词法:字符匹配方法是已知一个包含大量词语的词典,然后利用某种算法遍历词典中的所有词语来和待分词的文本内容进行匹配,匹配成功则表明找到了一个词语,然后再进行下一轮匹配,以此来完成分词操作。在进行字符匹配分词时,不同长度优先匹配的是最大匹配和最小匹配;扫描方向的不同的是正向匹配以及逆向匹配。一般有以下几种分词方法:
1)正向最大匹配法;
2)逆向最大匹配法;
3)最小切分法;
4)双向最大匹配法。
理解分词法:这种分词方法是让计算机拥有人的思维理解能力,对文本进行理解然后再进行分词。理解法一般包含三个部分:总控、句法语义子系统和分词子系统。在总控的控制下,句法语义子系统先对文本进行分析,然后将分析结果传递给分词子系统,最后分词子系统根据分析结果对文本进行分词。这种分词方法需要让计算机能模拟出人的理解思维能力,而由于中文语言本身的复杂程度很高,所以理解法还无法做到大规模使用。
统计分词法:在一个文本中,如果频繁地出现几个相邻的字,则证明这几个字很有可能是一个词语。因此字与字相邻出现的频率就能反映出这几个字组成一个词的可能性。统计文本中相邻的几个字出现的次数,再计算几个字的相邻出现概率,这一概率就能代表了这几个字是一个词的可能性。当概率达到某一个值时,在进行分词的时候就把这几个字作为一个词语进行切分。统计法只用统计文本中所有的相邻的几个字出现的次数,所以并不需要用到词典[7]。
2.3 文本特征处理
2.3.1 文本特征提取
由于中文文本本身词汇量的庞大,建立的词向量空间维数也就变得巨大,而这就直接导致了文本词向量空间的高维性和稀疏性,文本分类也因此变得困难。所以,在构建词向量空间的时候就需要进行降维操作,常用的方法包括最为简单的停用词移除或在建立词向量空间的时候通过对函数中参数的值的设置来去除一些文档频率过高的词语。
在文本分类的特征提取中常用到的应该是频率统计方法,而文本分类中常用到的频率统计则是词频和逆文档频率。
就词语这一方面而言,词语在文本中出现的频率,我们通常将之称为词频。在某一个文本中,一个词语出现的越频繁,说明这个词语与该文本的关系越紧密,越有可能成为该文本的特征词。同时,词频一般会被正规化,以此来避免偏向长文本[8]。
而就文本这一方面而言,在已知的训练集文本中包含某一词语的文本数量,我们将其称为文档频率。而逆文档频率则表示计算倒文档频率。其主要作用就是减少一些在文本中经常使用但和文本内容相关性不大的词语对后续分类产生的影响。在训练集文本中,包含某一词语的文本越少,则其逆文档频率越大,对分类越有帮助。但是在理论上来说,文本中有一个词语经常出现,那么这个词语应该与这一文本的关系非常紧密,其很有可能是这一文本的特征词,应该予以重视。这一点也是逆文档频率不足的地方。
2.3.2 特征权重矩阵
从文本中提取出的特征词,在一定程度上与文本的主题是相关的。那么,按照一定的公式或规则来赋予特征词相应的权重,这一权重可以反映该特征词与文本内容的相关度以及区分文本类别的能力[9]。由于之前已经完成了对特征词出现频率的统计,因此我们就可以通过特征词的频率特性计算其权重,从而获得特征权重矩阵。
论文采用了较为常见的TF-IDF方法来计算权重(TF代表词频,IDF代表逆文档频率)。在上一节中,已经说明了TF和IDF的基本含义。TF-IDF方法就是在词频权重的基础上加入了对文档频率的考虑,文档频率越大的词权重越低。因此,TF-IDF更倾向于保留文本中的重点词语,同时去除文本中经常使用的词语[10]。
TF-IDF的计算公式为:
(2.1)
其中,n表示在某一类文本中词语x出现的次数,N表示该类中所有词语的数目,D表示训练集文本的总数,d表示包含词语x的文本数。(分母加1是为了避免分母为零)
2.4 本章小结
本章系统地介绍了进行文本分了所需要的一些基础操作,主要是文本预处理和特征处理。其中的中文分词、特征提取和建立权重矩阵都是进行文本分类不可获取的步骤。
第3章 基于机器学习的文本分类方法
3.1 朴素贝叶斯方法
朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法,用以计算文本属于某一类的概率,分类时根据计算结果将文本分配到概率最高的那一类中去[11]。
朴素贝叶斯分类算法在理论上要比其他的分类算法有着更高的分分类准确率。但是实际上,朴素贝叶斯分类算法并不能做到这一点。这是因为朴素贝叶斯分类算法是假设文本的多个特征对于该文本在进行分类的时候的影响是相互独立的,即文本的多个特征之间是互不相关的。但在实际应用中,这一假设几乎不可能成立,这也是为什么在贝叶斯的前面加上朴素两个字的原因。
首先,贝叶斯公式为:
(3.1)
基于这一公式,可以得到最终的朴素贝叶斯公式[12]:
(3.2)
朴素贝叶斯分类方法内容容易理解,而且实现也比较简单,具有较快的分类速度和较高的准确度,被广泛的应用于许多领域之中。
3.2 K最近邻方法
K最近邻方法是一种基于分类与回归的方法。K最近邻方法的原理是已知训练集文本,对于待分类的文本,在其中找出距离最近的K个文本,如果这K个文本大部分都是一类,那么待分类文本就被认定属于这一类[13]。在K最近邻方法使用的模型中,训练集文本会对向量空间进行划分。对于K最近邻方法模型而言,距离度量、K值的选择和分类决策规则来是其三个关键点:
- K最近邻模型的向量空间中两个文本的相似程度可以由这两个文本之间的距离反映出来,其通常使用n维实数向量空间Rn 作为特征空间,并使用欧式距离来进行计算
- K值的大小会直接作用于K最近邻方法分类的结果。如果选择较小的K值,那么就只有几个与待分类文本距离较近的文本会对分类结果产生影响。而如果这几个文本正好是噪声点,那么分类结果就可能会出错。这也就意味着分类结果会对着K个文本非常敏感。即较小的K值会使得整体模型变得复杂,从而导致过拟合的发生;如果选择较大的K值,那么就会有很多距离较远的文本也会对待分类文本的分类结果产生影响,从而导致分类出错。所以一般使用K最近邻方法时,都会选择一个比较小的K值。
- 多数表决是K最近邻方法经常采用的分类决策规则,也就是对于待分类的文本,在其中找出距离最近的K个文本,如果这K个文本大部分都是一类,那么待分类文本就被认定属于这一类。
根据已知的距离度量,在训练集文本中找出与文本x距离最近的K个文本,包含这K个文本的x的邻域记作Nk(x),在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:
(3.3)



