互联网用户资金流入流出量建模方法研究毕业论文
2020-02-23 18:18:36
摘 要
近年来,我国的互联网金融迅速发展,互联网理财企业众多。理财企业拥有大量会员,其日常业务中涉及到相当庞大的资金流入和流出量。面对如此庞大的用户数量以及资金流量,人们的管理压力以及面临的风险相当大。为了降低资金的流动性风险,维护企业的正常运转,我们需要精确地预测资金的流入和流出量。互联网理财企业中,我们比较熟悉的是余额宝。余额宝提供了丰富的历史数据。充分理解这些数据的内涵,对其进行适当的处理,设计并运用科学的方法,力求对未来的资金流量进行精准预测,帮助其进行高效的运营与风险管控,进而帮助到其他互联网理财企业,造福社会,是本文的目的。
本文根据蚂蚁金服提供的官方历史数据,预测2014年8月每日的资金流入流出总量。运用观察折线图与DF检测等等方法选定训练集,之后开始预测。预测方法分为四种:1. BP神经网络直接进行预测;2. RNN直接进行预测;3. 将原始数据做STL分解后,借助BP神经网络预测trend,最终计算出要预测的数据;4. 将原始数据做STL分解后,借助RNN预测trend,最终计算出要预测的数据。预测结果的打分方式为:Score = 100-E,其中E为衡量误差大小的一个量。
方法1和方法2比较直接,预测误差在70%至75%左右,但是观察训练集与测试集的拟合情况可知,两种方法的训练集与测试集拟合效果都非常差,预测折线图几乎是直线。这与实际相当不符,所以二者均不可取。方法3和方法4中,首先使用STL分解法分解出周期(S),趋势(T),与剩余量(R),然后运用神经网络预测T值,并根据时间的特点算出2014年8月的S与R值,将三者加和成预测数据。该方法的预测折线图有明显的周期性,与真实数据比较后,发现周期性的拟合基本正确,预测数据的整体趋势也比较贴合原数据,最终得分比方法1和方法2稍有提高,预测精度增加了1%到5%不等。此外,本文发现,RNN理论上应当比BP神经网络预测的更加精准,但是并没有展现出应有的优势。这有可能是因为训练集数据量太小,也有可能是模型的固有缺陷。分析这个问题是今后的改进方向。
关键词:资金流入流出总量;时间序列;平稳性分析;STL分解;神经网络
ABSTRACT
In recent years, China's Internet finance has developed rapidly and there are numerous Internet finance companies. The wealth management company has a large number of members, and its daily business involves a considerable amount of capital inflows and outflows. Faced with such a large number of users and capital flows, people's management pressures and the risks they face are considerable. In order to reduce the liquidity risk of funds and maintain the normal operation of the company, we need to accurately predict the inflow and outflow of funds. Among Internet wealth management companies, we are more familiar with Yue Bao. Yue Bao provided a wealth of historical data. Full understanding of the connotation of these data, appropriate treatment of them, design and application of scientific methods, and strive to accurately predict future financial flows, help them to conduct efficient operation and risk control, and then help other Internet wealth management companies to benefit Society is the purpose of this article.
This thesis forecasts the total amount of capital inflows and outflows in August 2014 based on official historical data provided by Ant Financial Services. The training set was selected using the observation line chart and the DF detection method, and then the prediction was started. The prediction methods are divided into four types: 1. BP neural network directly makes predictions; 2. RNN directly performs predictions; 3. After the original data is decomposed into STLs, the BP neural network is used to predict trend and finally the data to be predicted is calculated; After the original data is decomposed into STLs, the RNN is used to predict the trend and finally the data to be predicted is calculated. The score of the forecast result is: Score = 100-E, where E is a measure of the size of the error.
Method 1 and Method 2 are relatively straightforward, and the prediction error is about 70% to 75%. However, observing the fit of the training set and the test set, it can be seen that both the training set and the test set have very poor fitting results. Almost straight. This is quite impractical, so neither is desirable. In methods 3 and 4, the STL decomposition method is used to decompose the period (S), the trend (T), and the remaining quantity (R), and then the neural network is used to predict the T value, and according to the characteristics of time, the calculation of August 2014 is performed. The S and R values add the three to the prediction data. The predictive line chart of this method has obvious periodicity. Compared with real data, it is found that the periodical fit is basically correct. The overall trend of the forecast data is also more consistent with the original data, and the final score is slightly better than methods 1 and 2. The prediction accuracy has increased by 1% to 5%. In addition, this thesis finds that RNN should theoretically be more accurate than BP neural network prediction, but it does not show its advantages. This may be because the amount of training set data is too small, it may also be the inherent defects of the model. Analyzing this issue is the direction of improvement in the future.
Key Words: total capital inflows and outflows; time series; stationarity analysis; STL decomposition; neural networks
目录
第1章 绪论 1
1.1 研究背景 1
1.2 研究意义 1
1.3 国内外研究现状 2
1.3.1国外发展研究现状 2
1.3.2国内发展研究现状 2
1.4 时间序列预测基本理论 2
1.4.1 时间序列预测简介 2
1.4.2 时间序列预测的基本步骤 3
1.5 论文组织结构 3
第2章 数据预处理 5
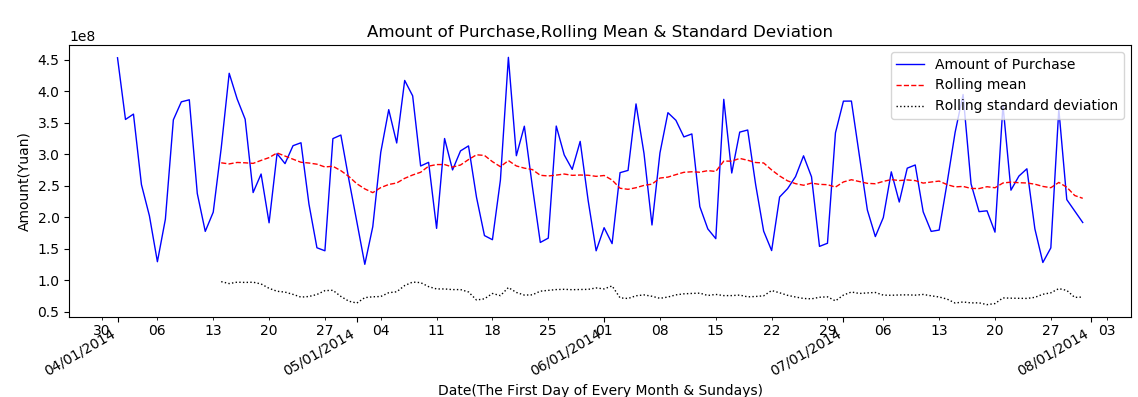
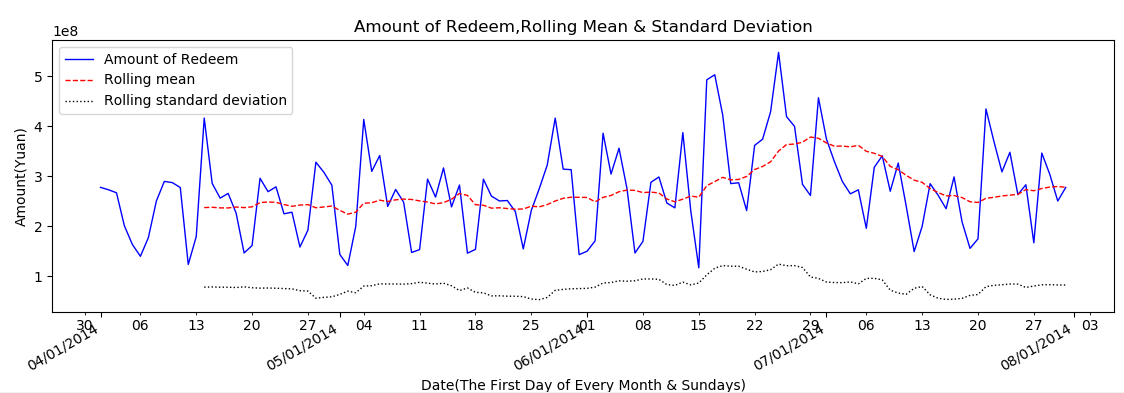
2.1 原始数据分析 5
2.2原始数据预处理 6
2.2.1 每日总量的计算 6
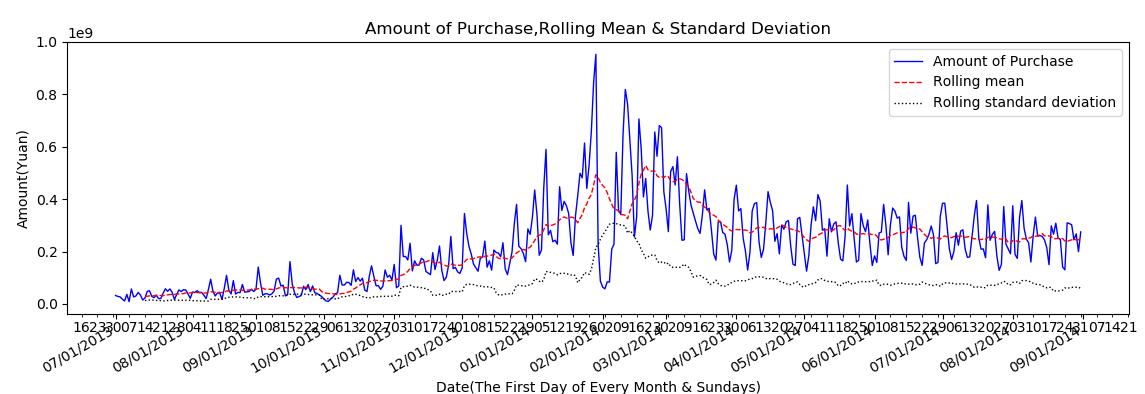
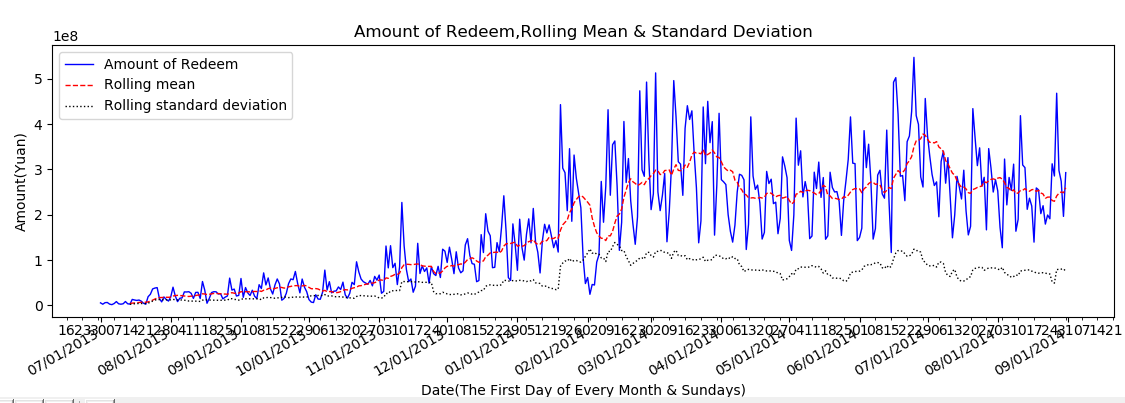
2.2.2 平稳性分析 7
2.2.3 截取训练集 10
2.2.4 观察训练集数据的周期 11
第3章 基于神经网络的时间序列预测 12
3.1 BP神经网络的基本内容 12
3.1.1 BP神经网络简介 12
3.1.2 BP神经网络的计算过程 12
3.2 基于BP神经网络的时间序列预测算法设计 14
3.2.1 BP神经网络的搭建及训练 14
3.2.2 BP神经网络预测实验结果 15
3.3 RNN基本内容 16
3.3.1 RNN简介 16
3.3.2 RNN的求解过程 17
3.4 基于RNN的时间序列预测算法的设计 18
3.4.1 RNN的搭建及训练 18
3.4.2 RNN预测实验结果 19
3.5 结果分析 21
第4章 运用STL分解法的时间序列预测 22
4.1 STL分解法简介 22
4.2 基本思路 22
4.3 STL分解结果与分析 23
4.4 结合STL分解法的BP神经网络预测方法 24
4.5 结合STL分解法的RNN预测方法 26
4.6 结果分析 29
第5章 总结与展望 30
参考文献 31
致谢 32
第1章 绪论
1.1 研究背景
当今互联网上的用户越来越多,互联网经济的体量也是越来越大,这使得“互联网 ”和传统金融业结合的需求变得更加迫切[1]。事实上,当前互联网正对各行各业进行渗透,互联网金融的产生也将是非常具有影响力的[2]。在2015年,互联网金融这一概念首次被纳入到了国家的五年规划建议中。这显示出国家的政策对互联网金融方面的重视[3]。
经济发展会导致消费金融的重要性的增加[4]。过去,在金融体系以及资本市场的中间,机构与公司的影响非常大,而家庭所起的作用比起前者来说相对较小[5]。随着经济的发展,人们可自由支配的收入增长了,一个家庭的财富也正在不断地积累。
大概在两年以前,虽然有所发展,但在某些国家中,还不存在组织能够针对家庭的资产的负债表去进行全面的了解[4]。同时,越来越多的商业模式正在和互联网渐渐结合在一起,二者正在逐渐变得密不可分。这就为互联网金融的蓬勃发展提供了十分有利的条件。
如今,互联网经济正在迅猛发展,随之而来的一些困难和问题也渐渐显现。一方面,互联网金融用户庞大的数量,使得数据的管理压力非常大;另一方面,由于用户众多,一旦出现预测失误等情况,损失将非常大。
1.2 研究意义
互联网理财企业其会员数量及其庞大,他们日常经营的成员涉及大量的资金流入和流出。面对如此庞大的用户群体,资金管理的压力将非常巨大。精准预测资金的流入流出量,对减小资金流动性风险、满足日常业务运转有重要的作用[6]。我们希望对余额宝的用户资金流量,尤其是其历史中的数据进行统计与建模,从而把握用户的行为及其特点,进而对未来的每日资金流入和流出的总数额进行有效的预测。
2013年6月13日,阿里巴巴旗下的“蚂蚁金服”推出余额宝,被广泛认为是中国互联网金融元年。而余额宝已成为普惠金融最典型的代表。由于天弘基金余额宝对接的增利宝公司货币基金,用户可以将资金存入其中,也可以提现或者用于购物缴费等支出,所以这将导致资金流量问题,即资金流入和流出的供给需求问题。阿里巴巴集团旗下的余额宝有庞大的用户群体,每天都有着巨大的资金的流入和流出;阿里巴巴集团希望实现盈利最大化,同时也要保证日常业务的正常运转,即确保广大用户不会出现提现或者消费时存量资金不足的情况。对于货币基金来说,资金流入是申购行为,资金流出是赎回行为。如果能相对准确地预测每天的资金流动情况,就可以在确保无资金流动危机的情况下,将可用的资金投入到其他领域,以获得最大化的收益。这对互联网金融公司来说是非常重要的。
1.3 国内外研究现状
1.3.1国外发展研究现状
近年来时间序列应用及其最新的动态主要表现在下面的几个方面:传统方法;谱密度分析与小波分析等正在越来越受重视 [7]。
- 传统方法
加拿大统计局已经将美国普查局拥有的X–12方法改进为X-2-ARIMA方法,以此来去除原本的方法序列两端不对称的影响[8]。
韩国银行在对韩国的经济时间序列进行季节调整时发现,X-2-ARIMA方法只考虑到西方国家的节假日因素,而对于韩国的一些特定节假日因素无法准确地分离,造成分析研究的误差[9]。人们为此创造了一些新的概念。
- 谱密度分析、小波分析等方法
分析时间序列时,除了ARIMA之外,某些国家正在将如谱密度分析以及小波分析等较新数理统计方法引入时间序列应用研究。
1.3.2国内发展研究现状
理论上的进展主要表现在以下两个方面:一个是单位根理论;另一个是非线性模型理论。我国的学者在非线性的时间序列分析方面获得了许多高水平成果[10]。
朱力行、安鸿志、陈敏等人关于非线性自回归模型的平稳性、遍历性和高阶矩取得了一定成果。成果展示出了有拥有这些性质所必须的最低条件。他们首次给出了完全对立的假设检验方法,无论从原理和应用都表明此方法有明显优点。他们研究了条件方差为非常数的回归和自回归模型的平稳性、遍历性和检验方法[10]。
1.4 时间序列预测基本理论
1.4.1 时间序列预测简介
时间序列预测法是一种针对历史资料的延伸预测。时间序列,是将一种统计数值,按照时间的先后顺序排到所得到的数列。时间序列预测法就是收集、编写与分析时间序列,得到其内在信息,并根据时间序列所反映出来的趋势、程度和内在规律(如周期等),对其进行类推,以预测下一段时间或更长时间内可能会达到的水平[11]。
1.4.2 时间序列预测的基本步骤
首先,将历史数据绘制成统计图,也就是收集历史数据。时间序列分析传统的分类方法是把各种因素按其特点或影响分为四类:长期趋势(T)、季节变动(S)、循环变动和不规则变动(I)。
第二,分析这一个时间序列,因为时间序列往往是由各种不同的因素相互作用而成的一个集合。
第三,求T,S,I的值,并用各种方法去拟合这三个值,得到对应的数学模型。
最后,求出它们的数学模型之后,就可以利用它们预测未来的T和S值,并用适当方法预测I值。然后,可以通过以下两个模式得到实际预测值:
加法模式T S I=Y
乘法模式T×S×I=Y
若I值难以求得,可以仅仅应用T和S值,按照两种模式进行数据的预测。另外,若某一序列并没有季节变动,那么可以仅仅凭借T值进行预测,T值既是预测值。但要注意,这样的预测值实际上最多只能大概代表未来数据的平均值,实际数据将围绕这一平均值而上下波动。 本文模型采取加法模式。
1.5 论文组织结构
本文第一章主要讲解本文的绪论,包括本文相应研究的研究背景,研究意义,国内外研究现状,以及时间序列预测的简介和基本步骤等。
本文第二章讲解对题目的数据预处理过程,包括对原始数据的预览,对要操作的数据进行的总量的计算,对原始数据的平稳性分析,对原始数据的截取,以及对原始数据周期的观测等。
本文第三章讲解基于神经网络的时间序列预测,包括BP神经网络与RNN的一些基本知识,以及应用它们进行预测的过程和结果,并分析了这两个结果。
本文第四章讲解运用了STL分解法的时间序列预测。该章节是对上一章节的改进,在神经网络预测中加入了STL分解,主要介绍了STL分解法的基本内容与分解结果,以及应用了STL分解法和神经网络的时间序列预测的结果及其分析。
本文第五章对本文作了总结,并提出了本文的不足之处与某些相应的改进方法。
第2章 数据预处理
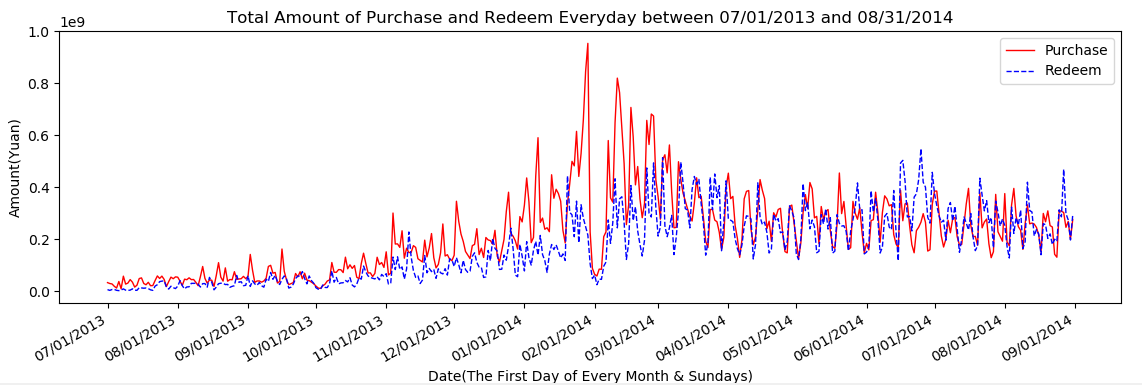
2.1 原始数据分析
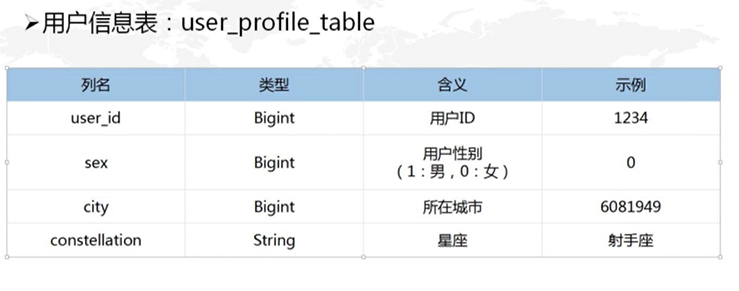
原始数据包含四张表:
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: