基于时空约束的行人重识别方法研究毕业论文
2021-12-09 17:17:28
论文总字数:23697字
摘 要
行人重识别是指在不同相机的拍摄视域下识别出同一行人的任务。行人重识别技术是搜索给定图像与图像库中拍摄到同一行人的图像的技术。传统的行人重识别方法通过计算给定图像与所有查询图像之前的视觉距离,并通过返回的距离排序表确认结果。但这样的方法在相机分辨率不高,图片模糊的情境下很难有良好的表现。因此,有的研究者开始研究行人的体型结构信息和姿态信息,降低图片质量不佳的影响,提取到了较为稳定的视觉特征。
然而目前大多数的研究方法都忽略了时空约束信息对于行人重识别性能的巨大提升。时空约束分为时间约束和空间约束。空间约束即指相机网络结构对不同相机能否捕捉到同一行人的约束,时间约束即指相机之间的距离对于相同行人的步行速度来说不可达时,不同相机则无法捕捉到同一行人。时空约束信息能够有效地降低无关图像的影响并缩小搜索范围。
本文采用视觉特征和时空约束信息相结合的方法来获得输入图片的相似度。时空约束信息的挖掘本文采用了统计方法,近似计算出一个复杂的时空概率分布。通过时空约束信息,成功地减少无关的图像并缩小识别范围。为了融合视觉相似度和时空概率,本文通过修改sigmoid函数得到一个联合度量函数,将二者结合得到行人相似度的表达式。本文在Market-1501和DukeMTMC-reID上将准确率提升到94.53%和93.89%,超过了大部分的先进方法。
关键词:行人重识别;身份识别;视觉时空结合;时空约束;视觉特征
Abstract
Person reidentification refers to the task of identifying the same pedestrian from different camera views. Person reidentification technology refers to the technology of matching a given image with the image of the same pedestrian captured in the image library. The traditional pedestrian recognition method calculates the visual distance between the given image and all the query images and confirms the result by the distance sorting table returned. However, such a method is difficult to perform well in the context of low camera resolution and blurred images. Therefore, some researchers began to study the body structure information and attitude information of pedestrians to reduce the impact of poor picture quality and extract relatively stable visual features.
Most of the current research methods ignore the great improvement of pedestrian recognition performance by spatiotemporal constraint information. spatial-temporal constraints are divided into spatial constraints and temporal constraints. Spatial constraint refers to the constraint of camera network structure on whether different cameras can capture the same pedestrian, and temporal constraint refers to when the distance between cameras is unreachable for the walking speed of the same pedestrian, different cameras cannot capture the same pedestrian. Spatio-temporal constraint information can effectively reduce the influence of irrelevant images and narrow the search scope.
In this paper, visual features and spatio-temporal constraint information are combined to obtain the similarity of input images. In this paper, a statistical method is used to approximate a complex spatial and temporal probability distribution. Through spatio-temporal constraint information, the irrelevant images are reduced and the recognition range is narrowed successfully. In order to fuse visual similarity and spatio-temporal probability, this paper obtains a joint metric function by modifying sigmoid function and combining the two to obtain the expression of pedestrian similarity. In this paper, the accuracy was improved to 94.53% and 93.89% in Market-1501 and Dukemtmc-Reid, which exceeded most advanced methods.
Key words: person re-identification;identity recognition;combination of visual space and time;spatial-temporal constraints;visual characteristics
目 录
第1章 绪论 1
1.1 背景与意义 1
1.2 研究现状 1
1.3 论文结构 4
第2章 基于PCB的视觉特征提取算法 5
2.1 引言 5
2.2 局部特征提取算法 5
2.3 ResNet50和PCB 6
2.4 本章小结 8
第3章 时空约束信息提取算法 9
3.1 引言 9
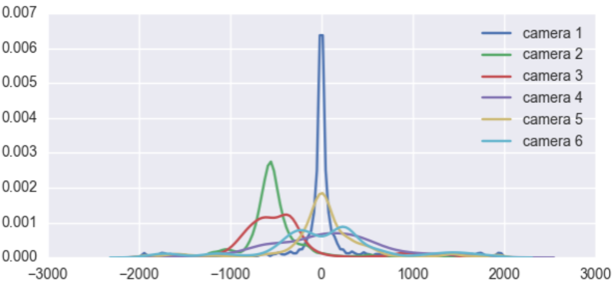
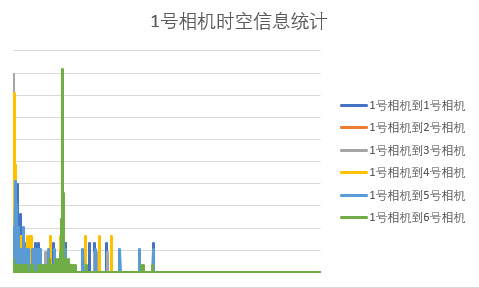
3.2 时空模型 10
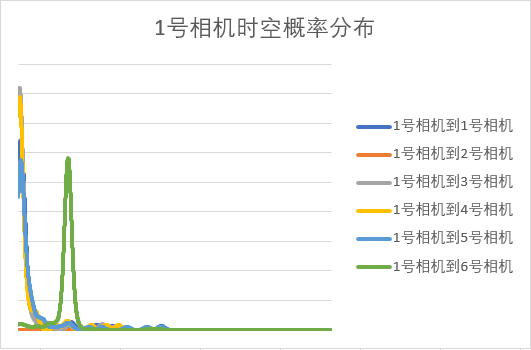
3.3 基于Parzen的时空概率分布模型 11
3.4 本章小结 12
第4章 基于视觉特征和时空约束结合的行人重识别算法 13
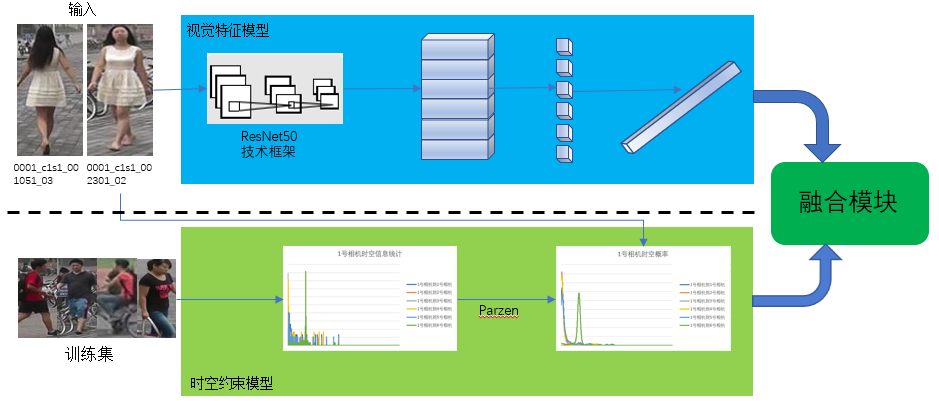
4.1 模型结构设计 13
4.2 模型实现细节 14
4.3 数据集 14
4.4 评价标准 15
4.5 实验数据 15
4.6 结论 18
第5章 总结与展望 20
参考文献 21
致 谢 23
第1章 绪论
1.1 背景与意义
行人重识别是利用计算机视觉技术识别处于不同摄像机拍摄区域下的同一行人。因而,行人重识别技术对维护公共安全和刑侦活动具有重大意义。目前人脸识别已经广泛应用于日常的安防监控活动当中,但无法获取较为清晰的人脸照片的情形仍然可能存在,甚至只能拍摄到模糊的人影或者行人身体的一部分。在这种情形下,行人重识别技术对于完善安全防护系统显得尤为重要,同时还能第一时间重现嫌疑人的活动轨迹,为刑侦活动提供最有效的情报。随着社会发展速度的增加,更多的监控设备被投入到日常生活当中,对于大量视频图片数据的处理需求与日剧增,填补行人重识别技术的空缺迫在眉睫。
随着行人重识别技术在计算机视觉领域获得越来越多的关注,近几年出现了大批较为优秀的成果,但距离实际应用都还有较大的差距。可见,行人重识别技术的突破是计算机视觉领域的一大挑战。但行人重识别技术应用前景极佳,一旦获得巨大突破将会对安全保障系统和刑侦活动带来天翻地覆的变化。
行人重识别技术分为识别和验证两大任务,识别即根据已有信息完成对输入图片行人的身份预测,验证则是根据对输入图片学习到的特征表达到搜索库中查询包含相同行人的图片。因此,行人重识别技术的研究方向基本集中在设计表达能力强的模型和提升搜索比对结果的算法。
目前为止大量的工作都采用提取视觉特征构建表达能力强的行人重识别模型的方式。但相机往往存在分辨率低,不同相机的光照和拍摄角度不同等问题,单纯地提取行人的视觉特征往往无法获得一个稳定的特征表达。为了解决这一问题,目前已经有人提出通过提取局部特征提供细粒度信息,这种方法在近几年的研究种中已经被证明效果非常好。
不同于继续在视觉特征领域提升行人重识别性能,本文提出一种结合视觉特征和时空约束信息的方法,在提取局部特征的基础上再次提升了行人重识别性能。时空约束分为空间约束和时间约束。空间约束即指相机网络结构对不同相机捕捉到同一行人的约束,如相机A和相机B之间不存在路径,即两者不可能捕捉到同一行人。时间约束即指相机之间的距离对于相同行人的步行速度来说不可达时,不同相机则无法捕捉到同一行人。可以预见,时空约束的介入能够有效地减少搜索图库种的无效图片,同时提升搜索效率和准确度。
1.2 研究现状
行人重识别技术的提出最早可以上溯到1996年,2006年行人重识别第一次在CVPR上提出并同时获得了不少的关注,2007年之后相关的研究便不断出现。2012年第一次行人重识别研讨会召开;2014年以后,随着深度学习技术的进一步发展,深度学习开始应用于行人重识别问题;2016年至最近,行人重识别的优秀成果不断涌现,尤其是深度学习有关的文章获得了大量的关注。随着深度学习在行人重识别领域的研究不断深入,依靠视觉特征提升行人重识别准确率已经渐渐遇到了瓶颈。随后,结合行人的时空约束信息便成为了提升性能的突破口。
起初,学者们研究利用手工提取特征的方法完成行人重识别任务。例如,BoW[1](Bag of Words),又称词袋模型,将输入图片均分后使用的图像块计算每个局部特征,并将之转化为直方图组成输入图片的全局特征。再经由几何约束(Geo)、高斯掩模(Gauss)、多重查询(MultiQ)和重排列(Rerank)优化后进一步提升模型的准确率。而论文最大的贡献是提出非常著名的数据集Market-1501。Null Space[2]通过将相同行人的图像压缩到中的一点上,以此缩小相同行人图片间的距离,扩大不同行人图片间的距离,该方法同时还具备较高的计算效率。
随着深度学习技术的兴起,为行人重识别提取视觉特征带来了新的启发。视觉特征方向的行人重识别方法可分为基于图像的行人重识别和基于视频的行人重识别两类,这两类对象都可以从特征描述、度量学习和返回结果的排序算法三个方面进行研究。特征表述可稍加细分为表征学习和局部特征,APR[3]将行人的属性特征与身份信息结合获得了成功。
度量学习经历了从对比损失到三元组再到四元组的方法变迁。例如,三元组损失[4]向网络输入三张图片,包括一对正样本对、一对负样本对,通过减小正样本对间的距离,扩大负样本对的距离在行人重识别的查询图库中形成聚类,达到行人重识别的目的;四元组损失[5]对比于三元组损失多出了一个负样本对,并以正负样本对的绝对距离推动模型学习到更好的视觉特征表达;边界挖掘损失[6]则同时兼顾正负样本对间的相对距离和绝对距离,并划定正负样本对的边界,因此在目前的损失函数中具备最优的效果。
请支付后下载全文,论文总字数:23697字
相关图片展示: