负虹膜识别算法的重现毕业论文
2021-03-13 22:56:48
摘 要
近些年来,随着生物识别技术的研究深入,人们越来越注重生物特征的安全性,如何在保护生物特征同时实现安全的生物识别是研究的热题。由于图片捕获期间的失真等原因,从个人导出的生物特征数据将产生略微变化,高性能的生物特征识别算法能够弥补这些损失。负数据库(NDB)技术是一种新兴的隐私保护技术,已有多种算法被提出用于生成难以逆转的负数据库。人们用于生物识别的特征在生命周期内通常是稳定的,而相对于其他生物特征,虹膜表现得更为稳定,本文所研究的主要内容是虹膜识别。在本文中,首先介绍经典的虹膜数据的采集和处理过程,然后在移位(Shifting)和掩蔽(Masking)匹配模式下重现负虹膜识别算法,证实了负虹膜识别算法在经典数据库CASIA-IrisV3-Interval上具有很高的准确性,最后提出在已有负虹膜识别算法上进行改进的思路及后续工作展望。
关键字:负虹膜识别,p-hidden算法,负数据库,生物特征模板保护
Abstract
In recent years, with the deepening of biometric technology research, people pay more attention to the security of biometric data. How to protect biometric data while achieving secure biometric recognition is the hot topic of research. Due to the distortion during image capture, the biometric data derived from the individual will produce a slight change. Those biometric recognition algorithms of excellent performance can compensate for these losses. Negative database (NDB) technology is an emerging privacy protection technology. A variety of algorithms have been proposed to generate the negative database difficult to reverse. The biometric data of one person are usually stable in his or her life time , and iris behaves more stable than other biometric features. Thus the main contents of this essay are about iris recognition. In this essay, we first introduce the classical ways of acquisition and processing iris data, and then reconstruct the negative iris recognition algorithm using the matching and shifting rules, which proves that the negative iris recognition algorithm has high accuracy in the classical CASIA-IrisV3-Interval. Finally have a try on improving negative iris recognition algorithm and look forward the future work.
Key Words:Negative iris recognition, p-hidden algorithm, Negative database, Biometric template protection
目录
第1章 绪论 1
1.1 引言 1
1.2 国内外研究现状 1
1.3 研究的目的与意义 2
1.4 全文结构概述 2
第2章 负虹膜识别技术介绍 3
2.1 经典的虹膜识别流程 3
2.1.1 图像采集 3
2.1.2 图像预处理 3
2.1.3 特征提取 3
2.1.4 特征匹配 4
2.2 虹膜识别的通用操作模式 4
2.3 负数据库技术 5
2.4 负虹膜识别背景知识 6
2.4.1 p-hidden算法 6
2.4.2 虹膜码相似度计算方式 6
2.4.3 负虹膜识别操作模式 7
2.4.4 性能评价方式 8
2.5 本章小结 9
第3章 负虹膜识别重现实验 10
3.1实验方法 10
3.2 OSIRIS系统相关工作 10
3.3 p-hidden算法的实现 11
3.4 模板生成 13
3.5 匹配结果 14
3.6 负虹膜识别改进思路 15
3.7 本章小结 16
第4章 总结与展望 17
4.1 总结 17
4.2 展望 17
致谢 21
第1章 绪论
1.1 引言
随着社会的进步和信息技术的发展,越来越多的场合需要身份认证,如何进行可靠的身份鉴别成为近年来研究的热题。生物特征识别就是利用人类自身的生物特征来达到身份认证的目的,与传统的基于密码的认证方法相比,生物特征识别具有方便、快捷、无需记忆、不易丢失和复制等优点[1]。此外每个人的生物特征信息不相同,而在人的一生中生物特征信息一般保持不变,因此面部、指纹、虹膜等人类所固有的生物特征逐渐开始被人们研究用于生物特征识别。而虹膜相比于其他的生物特征更加稳定,研究表明,基于虹膜的生物识别技术通常要比基于其他生物特征的识别技术表现出更良好的性能。
生物特征识别技术中存在一些问题,生物特征模板的安全问题就是其中之一(生物特征模板是指存储在系统中当作模板以用于后续匹配过程的经过处理后的生物特征数据),一旦攻击者用假的生物特征数据成功入侵,原有的生物特征模板就可能永久丢失,这样会对用户身份的隐私性和安全性产生极大威胁[2]。因此,如何对生物特征模板进行保护,以达到安全生物特征识别的目标是一个重要课题。时至今日,已经有很多技术方案被提出,安全认证方案也应用在了虹膜识别领域,随之产生了各种虹膜识别算法。本文将对经典的虹膜数据的采集和处理过程进行概述,以此来介绍虹膜识别的基本流程,然后对一种高效的虹膜识别算法——负数据库虹膜识别算法进行分析和重现,再尝试对已有的负数据库虹膜识别算法进行改进。
1.2 国内外研究现状
安全虹膜识别技术是建立在已有的生物特征保护技术主要分为两大类:生物特征加密技术和可撤销生物特征模板技术[3]。其中生物特征加密方案又分为三类:密钥生成方案;以Bioscrypt、Fuzzy commitment (模糊承诺)、Fuzzy vault(模糊保险箱)为代表的密钥绑定方案;以Secure sketch为代表的密钥释识别技术之上,迄今为止,生物特征识别技术历经了长足的发展。作为生物特征识别技术中的其中,生物特征模板放方案,这些方案都要基于辅助数据。而以Biohashing为代表的可撤销生物特征模板技术则是使用某种参数可调的单向变换函数对原始生物数据进行变换,如果变换模板被盗,只须改变参数,就能生成新的模板[4]。这些方案也陆续应用于虹膜识别:1998 年,Davida等人将私有模板方案用于虹膜识别,但此方法被证明存在严重的安全漏洞。模糊承诺方案也于1999年应用于虹膜识别,它是密钥绑定方案中最简便的方案之一,它表明通过通用特征提取方案获取的虹膜码能够检索和绑定加密密钥,能够应用于通用密码系统。2002年,Juels和Sudan成功应用模糊保险箱方案实现虹膜识别,它需要以实值的特征向量作为输入。后续也有在这些方法上的改进,例如在2008年,Reddy和Bab改进了经典的模糊保险箱方案,提高了虹膜识别的安全性;Nandakumar 和Jain创立了基于虹膜和指纹的多生物特征模糊保险箱方案。2010年,Ouda, Tsumura和Nakaguchi提出了无令牌的可撤销模板虹膜识别方案[5]。此后也出现了更加高效的虹膜识别方案,负虹膜识别技术就是其中之一。
1.3 研究的目的与意义
本文对安全虹膜识别技术进行研究、分析以负虹膜识别为代表的性能良好的虹膜识别算法、对负虹膜识别算法进行重现为了设计出更优化的虹膜识别算法,设计出符合人们需求的、安全的、高效的虹膜识别系统。虹膜识别技术在近些年来虽然取得了很大发展,也通过某些手机产品携带虹膜识别功能等渠道逐渐进入公众的视野,不过由于虹膜识别技术自身的局限性和一些其他原因,目前虹膜识别并未“大红大紫”,它主要还是被应用于门禁、刑侦等冷门场所。本文对安全虹膜识别技术进行研究,将助推此技术的发展与完善,为今后生物特征识别技术大范围推广打下基础,也是对社会的发展和时代的进步做出贡献。
1.4 全文结构概述
第1章绪论,对本文所选课题的背景和研究目标进行详细地说明,之后介绍国内外的研究现状,再阐述对该课题研究的目的与意义。
第2章介绍负虹膜识别技术的背景知识,先通过对经典虹膜识别系统的工作流程的概述来介绍虹膜识别,再具体介绍负虹膜识别技术中用到的相关技术及性能评估方式。
第3章介绍负虹膜识别重现的实验方法,通过具体实验来重现负虹膜,在将实验与已有数据进行对比来判断重现是否成功,并在已有的理论基础上提出负虹膜识别算法的改进方案。
第4章进行总结和展望,总结本文所做的工作和在研究这一课题的过程中所遇到的问题与收获,并对所研究的课题接下来的工作内容进行展望。
第2章 负虹膜识别技术介绍
在本章中,首先将概述经典的虹膜识别流程和其通用操作模式,以此对虹膜识别进行基本的介绍,然后展开对负虹膜识别技术的介绍(负虹膜识别就是将负数据库技术用于虹膜识别中),包括负数据库技术、p-hidden算法、虹膜数据相似度的计算方式等。
2.1 经典的虹膜识别流程
Daugman的虹膜识别算法形成了当今虹膜虹膜识别系统的基础,它主要分为四个部分:(1)图像采集;(2)图像预处理;(3)特征提取;(4)特征匹配[6]。下面将分别介绍这四个部分。
2.1.1 图像采集
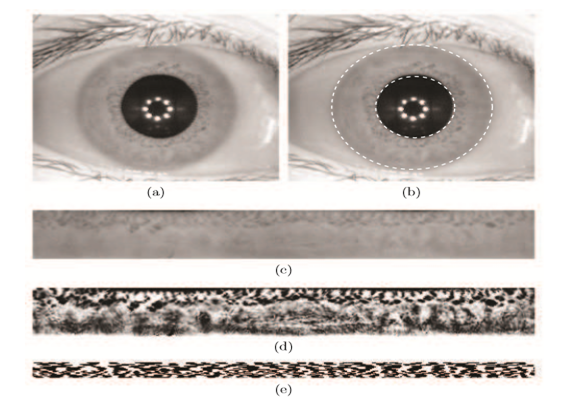
图像采集就是对用户的虹膜图像进行采集,这是虹膜识别系统的首要步骤,因此虹膜识别系统要求用户与系统完全配合。采集到的虹膜图像如图2.1(a)所示。
2.1.2 图像预处理
在预处理的过程中,需要先检测虹膜的内外边界,其中内边界是指虹膜与瞳孔的边界,外边界是指虹膜与巩膜的边界,检测后的结果如图2.1(b)所示。接下来,根据Daugman在2004年提出的“橡胶板”方法,瞳孔和虹膜环之间的区域会被归一化为512×64像素的矩形纹理,得到的虹膜纹理示例如图2.1(c)所示。然后使用直方图拉伸方法增强所得到的虹膜纹理的对比度,将得到如图2.1(d)所示的预处理结果。
2.1.3 特征提取
特征提取阶段将从预处理后的虹膜纹理中提取出二进制特征向量,这个二进制特征向量被称作虹膜码。通常可以采用两种算法进行特征提取[7], 第一种是由Ma等人在2004年提出的,在这种方法中,对预处理后的虹膜纹理上部的512×50像素进行分析,虹膜纹理被分成10个条纹,获取了5个一维信号,每个信号为5个相邻行像素的平均值。然后对所得到的10个信号进行二次小波变换,并从每次变换中选择两个固定子带,得到总共20个子带。 每一个子带在适当的阈值上都会获取一个最小值和最大值,随后提取在每个极值点处的0-1交替位码代码。 每个信号都使用512位,这样最终虹膜码总共包含512×20 = 10240位。第二种特征提取方法应用Log-Gabor函数获取的滤波器,在虹膜纹理的像素上进行复杂Log-Gabor滤波器的逐行卷积并将所得像素的负数值的相位角离散成两位。为了得到与方法一中相同长度的虹膜码,在应用一维Log-Gabor滤波器之前要将相同的纹理尺寸与行平均值应用于10个信号之中。两位的相位信息用于产生一位2进制码,这样产生的虹膜码的长度仍然是512×20=10240位。特征提取后的结果如图2.1(e)所示。
2.1.4 特征匹配
在一般的虹膜识别算法中,经常使用汉明距离来表示不同虹膜数据之间的差异,汉明距离越小表明差异越小,越相匹配,反之亦然。在计算汉明距离时,会通过逐位异或运算来计算不匹配的位,为了补偿头部倾斜通常会通过对虹膜码在左右两个方向的循环移位来实现模板对齐,比较每次移位所得的汉明距离,最小距离时的对准被称为最佳对准。