编译程序词法分析核心算法在线评测子系统的设计与实现毕业论文
2020-02-19 18:15:15
摘 要
编译原理是计算机专业的一门重要专业课旨在介绍编译程序构造的一般原理和基本方法。内容包括语言和文法、词法分析、语法分析、中间代码生成、存储管理、代码优化和目标代码生成。而编译程序是现代计算机系统的基本组成部分之一,从功能上看,一个编译程序就是一个语言翻译程序。一个编译程序的重要性体现在它使得多数计算机用户不必考虑与机器有关的繁琐细节,使程序员和程序设计专家独立于机器,这对于当今机器的数量和种类不断增长的年代尤为重要。
编译程序在线评测系统力求在整体上展现整个编译过程的实现,它将编译过程拆分成一个个模块(阶段),各个模块之间又有着紧密联系, 提供一套完整的编程接口供用户进行调用与调试,以实现编译程序的编写和实现。
通常编译程序分为词法分析,语法分析,语义分析,中间代码生成和目标代码生成几个部分,每个部分又有不同的实现方法和算法。词法分析器是编译系统的第一个阶段,是编译器的重要组成部分。本论文编制编译程序在线评测系统之一--词法分析核心算法的在线评测子系统软件,设计词法分析各核心算法的编程接口与模板,供用户进行调用与调试。
词法分析三大核心内容是从正规式到NFA,从NFA到DFA以及最小化DFA,其中分别用到了“子集法”和“分割法”来实现从NFA到DAF,最小化DFA两个算法,在实现算法后对其进行接口编程和模块化处理,为后续的编译程序提供调用。
关键词: 词法分析器,正规式,NFA,DFA,模块化
Abstract
Compilation principle is an important professional course of computer science. It is intended to introduce the general principles and basic methods of compiler construction. Content includes language and grammar, lexical analysis, parsing, intermediate code generation, storage management, code optimization, and object code generation. Compiler is one of the basic components of modern computer systems. From a functional point of view, a compiler is a language translator. The importance of a compiler is that it makes it unnecessary for most computer users to consider the cumbersome details associated with the machine, making programmers and programming experts independent of the machine, which is especially important in the growing number and variety of machines today.
The online evaluation system of the compiler tries to show the implementation of the whole compilation process as a whole. It divides the compilation process into modules (phases), and each module has a close relationship, providing a complete programming interface for the user to call. And debugging to implement the compilation and implementation of the compiler.
Usually the compiler is divided into lexical analysis, parsing, semantic analysis, intermediate code generation and object code generation. Each part has different implementation methods and algorithms. The lexer is the first stage of the compilation system and an important part of the compiler. This paper compiles one of the online evaluation systems for compilers--the online evaluation subsystem software of the lexical analysis core algorithm, and designs the lexical analysis of the programming interfaces and templates of each core algorithm for users to call and debug.
The three core contents of lexical analysis are from normal to NFA, from NFA to DFA, and minimizing DFA. The "subset method" and "segmentation method" are used to realize the two algorithms from NFA to DAF and minimize DFA. After implementing the algorithm, it performs interface programming and modular processing to provide calls for subsequent compilers.
Key Words:Lexical analyzer, regular, NFA, DFA, modular
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1 背景及意义 1
1.2 国内外研究现状 2
1.3 论文结构 2
第2章 词法分析程序的设计 3
2.1 词法分析程序与语法分析程序的接口方式 3
2.2 词法分析程序的输出 3
2.3 词法分析程序中如何识别单词 4
2.4 词法分析程序各核心算法的模块化 4
第3章 主要模块算法 5
3.1 从正规式到NFA 5
3.1.1 算法的主要实现步骤 5
3.1.2 所用数据结构和算符优先 6
3.1.3 程序流程 6
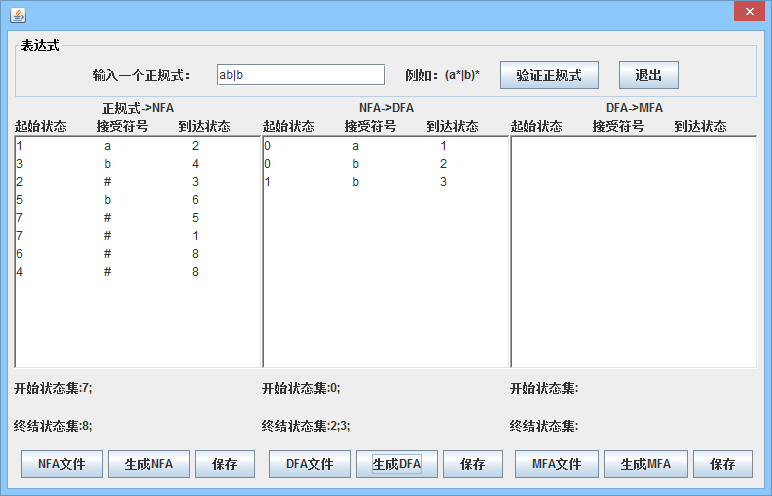
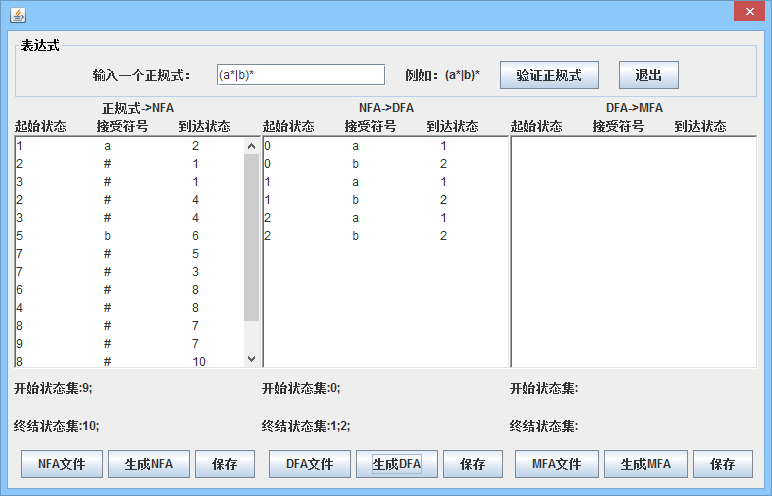
3.2 从NFA到DFA 7
3.2.1 子集法 7
3.2.2 实现思路和方法 8
3.2.3 程序流程 8
3.2.4 注意事项 8
3.3 DFA的最小化 9
3.3.1 分割法 9
3.3.2 主要数据结构 9
3.3.3 程序流程 10
3.4 本章总结 10
第4章 算法实现与测试 11
4.1 开发环境 11
4.2 测试用例 11
4.2.1 正规式验证 11
4.2.2 正规式转为NFA 12
4.2.3 NFA转为DFA 13
4.2.4 DFA转为MFA 14
4.3 本章总结 15
第5章 总结与展望 15
5.1 总结 15
5.2 展望 16
参考文献 17
致谢 53
绪论
背景及意义
编译原理是计算机科学的重要专业课程,它旨在介绍编译器构造的一般原则和基本方法。内容包括语言和语法,词法分析,解析,中间代码生成,存储管理,代码优化和目标代码生成。编写原则是计算机专业设置的重要专业课程。编译器在线评估系统努力展示整个编译过程的实现,并将编译过程分成模块(阶段)。每个模块都与引入编译器构造的一般原则和基本方法密切相关。内容包括语言和语法,词法分析,解析,中间代码生成,存储管理,代码优化和目标代码生成。编写原则是计算机专业设置的重要专业课程。虽然只有少数人从事编写工作,但课程在理论,技术和方法上为学生提供了系统有效的培训,有利于提高软件人员的素质和能力。
编译程序是现代计算机系统的基本组件之一,并且大多数计算机系统配备有多种高级语言的编译器。对于某些高级语言,甚至配置了几个具有不同性能的编译器。从功能上讲,编译器是一种语言翻译器。编译器的重要性在于,它使大多数计算机用户无需考虑与机器相关的繁琐细节,使程序员和编程专家独立于机器,这在当今越来越多的机器中尤为重要。编译器的基本任务是将源语言程序翻译成等效的目标语言程序。有数千种源语言,从常用语言(如FORTRAN,Pascal,C,Java和C )到各种语言。计算机应用领域的特殊语言,两种目标语言也各种各样,加上编译器由于结构不同而具有不同的功能,并分为各种类型,如一趟编译,多趟编译,调试或编译尽管存在这些明显的复杂性,但是任何编译器执行的主要任务基本相同。通过这些理解任务,相同的基本技术可用于各种源语言和目标语言设计和构建编译程序。
编译器的在线评估系统力求展示整个编译过程的实现, 它将编译过程划分为一个个模块(阶段),每个模块都有紧密的关系,为用户提供完整的编程接口, 并调试实现编译器的编译和实现。
通常编译程序分为词法分析,语法分析,语义分析,中间代码生成和目标代码生成几个部分,每个部分又有不同的实现方法和算法。词法分析器是编译系统的第一个阶段,是编译器的重要组成部分。本论文编制编译程序在线评测系统之一--词法分析核心算法的在线评测子系统软件,设计词法分析各核心算法的编程接口与模板,供用户进行调用与调试。
编译器的第一阶段是词法分析。 它的主要任务是从左到右逐个字符地扫描源程序,并生成一系列用于解析的单词序列。 词法分析工作可以独立完成,将字符流的来源更改为单词序列,并将其输出到中间文件,作为语法分析程序的输入继续编译程序。 但是,更一般的情况是将词法分析器设计为子程序,只要语法分析程序需要一个单词就会调用它。
国内外研究现状
编写原则“是计算机科学的核心专业课程之一。其主要任务是使学生掌握高级语言编写技术和高级编程程序的设计原则和构造技术,并根据编写程序设计一些程序。 因此,编译器在线评估系统的开发具有重要的实际意义。一方面,复杂的编译器可以简化,小型化和独立,使编译器的实现可以一步一步,从小到大,从易到难;另一方面,它提供了一个完整的实践模型,用于学习和使用编译器,帮助学生建立写复杂程序的信心,并大大方便课程的教学。
目前,前国内外已经有大学研究和开发了这样的程序平台,大部分用来实践和教学所用,例如北京大学将在线测评用于“数据结构”的教学,北京航空航天大学用于“c语言”的教学和实践。然而,目前在线评估在教学中的应用仅限于算法课程,不能应用于其他课程。 例如,在线评估和编制原则课程的应用仍然空缺。主要原因是编译程序是大中型软件,这比较复杂。它通常由多个程序模块组成,程序模块密切相关,每个模块的执行结果不一定是唯一的,这些因素都使编译器难以在线评估。
其中lex是目前unix环境下非常著名的工具,其主要功能是生成一个词法分析器的C源码。描述规则采用正则表达式。Lex是一个程序生成器,专为字符输入流的词法处理而设计。它接受一个用于字符串匹配的高级,面向问题的规范,并以通用语言生成一个识别正则表达式的程序。正则表达式由用户在给Lex的源规范中指定。 Lex编写的代码在输入流中识别这些表达式,并将输入流分区为与表达式匹配的字符串。在字符串之间的边界处执行用户提供的程序部分。 Lex源文件关联正则表达式和程序片段。当每个表达式出现在Lex编写的程序的输入中时,执行相应的片段。
用户提供除完成其任务所需的表达式匹配之外的附加代码,可能包括由其他生成器编写的代码。识别表达式的程序是在用于用户程序片段的通用编程语言中生成的。因此,提供高级表达语言来写入要匹配的字符串表达式,同时用户的写入动作的自由度不受损害。这避免了强迫希望使用字符串操作语言进行输入分析的用户以相同且通常不适当的字符串处理语言编写处理程序。
Lex不是一种完整的语言,而是一种代表新语言特性的生成器,可以添加到不同的编程语言中,称为“主语言”。正如通用语言可以生成在不同计算机硬件上运行的代码一样,Lex可以用不同的主语言编写代码。主机语言用于Lex生成的输出代码以及用户添加的程序片段。还提供了用于不同主机语言的兼容运行时库。这使Lex适应不同的环境和不同的用户。每个应用程序可以针对适合于任务的硬件和主机语言的组合,用户的背景以及本地实现的属性。目前,唯一受支持的宿主语言是C,虽然Fortran(以Ratfor [2]的形式在过去已经可用.Lex本身存在于UNIX,GCOS和OS / 370;但Lex生成的代码可能是在适当的编译器存在的任何地方。
论文结构
本文的内容结构由以下几个部分构成:
- 词法分析程序的主要设计。
- 介绍词法分析的三个核心算法。
- 对系统的用例与测试。
词法分析程序的设计
词法分析是编译的第一个阶段,它的主要任务是从左至右逐个字符地对源程序进行扫描,产生一个个单词序列,用于语句分析。本章主要介绍词法分析程序的接口方式,输出以及如何识别单词。
词法分析程序与语法分析程序的接口方式
词法分析程序完成第一阶段的编译工作。词法分析工作可以独立完成,将字符流的来源更改为单词序列,并将其输出到中间文件,继续编译过程作为解析器的输入。但是,更一般的情况是将词法分析器设计为子程序,只要解析器需要一个单词就会调用它。词法分析器每次调用时,都会从源文件中读取一些字符,直到它识别出一个单词并通过第一个字符直到下一个单词为止。在此设计中,词法分析器和解析器放在同一个传递中,从而消除了中间文件或存储。
词法分析程序的输出
当从语法分析程序接收到下一个单词的请求时,词法分析器从左到右读取源程序中的字符流以识别下一个单词。 在识别出下一个单词并验证其词汇正确性之后,词法分析器将结果以单词符号的形式发送给语法分析程序以响应其请求。 如果在单词识别过程中发现词法错误,则返回错误消息。
单词符号一般可分为下列5类:
- 关键字,也称保留字,如pascal语言中的begin、end、if、while和var等。
- 标识符,用来表示各种名字,如常量名、变量名、和过程名等。
- 常数,各种类型的常数,如25、3、TRUE、和“ABC”等。
- 运算符,如 、*、lt;=等。
- 界符,如逗号、分号、括号等。
词法分析程序输出的单词符号可以用以下二元式形式表示:(单词类型,单词本身的值)单词类型语法分析所需的信息,单词本身的值是编译所需的信息其他阶段。语句“const i = 25,yes = 1;”中的单词25和1 在PL / 0中都是常量,并且常量的值25和1对于代码生成是必不可少的。有时,对于某些词,不仅需要它的价值,还需要一些其他信息来编译。例如,对于标识符,需要记录其类别,层次结构和其他属性。如果这些属性都在符号表中收集,则可以按如下方式设计单词的二元式表示:
(标识符,指向该标识符所在符号表中的位置的指针)
如上述语句中的单词i和yes的表示为
(标识符,指向i的表项的指针)
(标识符,指向yes的表项的指针)
词法分析程序中如何识别单词
词法分析中识别下一个单词的过程,简单来看就是逐个读取字符,然后将它们拼在一起的过程。词法分析程序的作用就是在这个拼单词的过程中如何获得下一个有意义的单词符号,即识别出单词种别以及单词自身的值。
要识别出有意义的单词符号,主要是依据程序设计语言的词法规则描述。描述一个语言的词法规则,通常需要借助形式化或半形式化的描述工具,以保证没有歧义性。常见的可用于词法描述工具又状态转换图、扩展巴克斯范式(EBNF)、有限状态自动机、正规表达式以及正规文法等。在词法规则的基础上,进一步设计单词符号的结构。
在识别出一个有意义的单词后,词法分析程序将单词种别连同单词自身的值一起构成一个单词符号,返回给调用它的语法分析程序。
有限状态自动机、正规表达式以及正规文法是适合于正规语言的描述以及处理的形式模型。在现实程序设计语言中,几乎任何一种有意义的单词种别对应的单词合集都是正规语言,这些模型的表达能力足以描述任何程序设计语言的词法规则。另外,基于这些语言模型处理正规语言的方法以及非常成熟。因此,以这些模型为基础来设计词法分析的自动构造工具是人们目前普遍采取的途径。
词法分析程序各核心算法的模块化
词法分析主要有三大核心算法,从正规式到NFA,从NFA到DFA,以及最小化
DFA,设计各算法的接口和模板化有如下优点:
- 使整个编译器的结构更简洁,清晰和有条理。 词法分析比语法分析简单得多,但由于源程序结构的一些细节,识别单词的工作通常非常曲折且耗时。
- 编译程序的效率会改进。大多数编译时间都花在扫描字符以分隔单词符号上。 因此分离词法分析,使用专门的技术来读取字符和分离单词可以大大加快编译速度。此外,可以通过有效的方法和工具来描述和识别单词的结构,并且可以建立用于词法分析程序的自动构建工具。
- 增强编译程序的可移植性。在相同语言的不同实现中,或多或少地与设备相关的特征相关,例如ASCII或EBCDIC字符编码。此外,语言字符集的特殊性,一些特殊符号,可以放在词法分析程序中解决,而不会影响编译器的其他组件的设计
主要模块算法
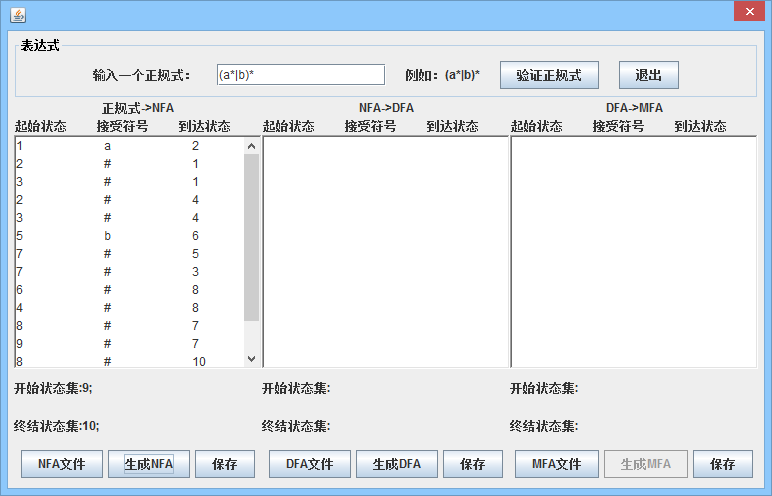
词法分析的三个核心算法分别是从正规式到NFA,从NFA到DFA,最小化DFA。
从正规式到NFA
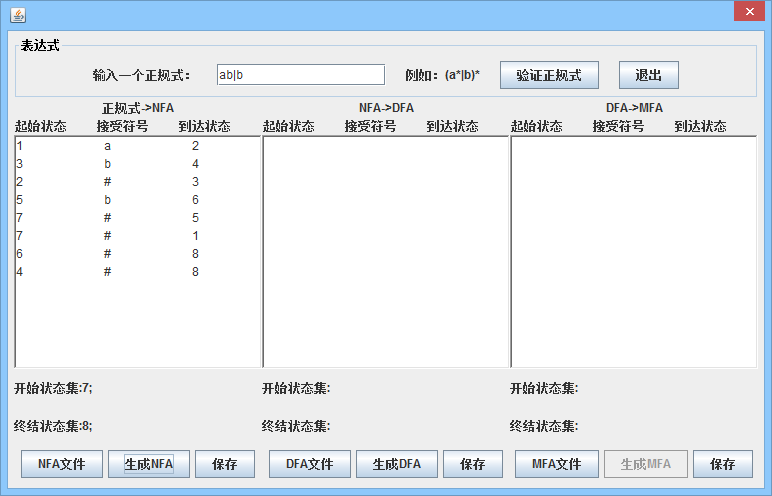
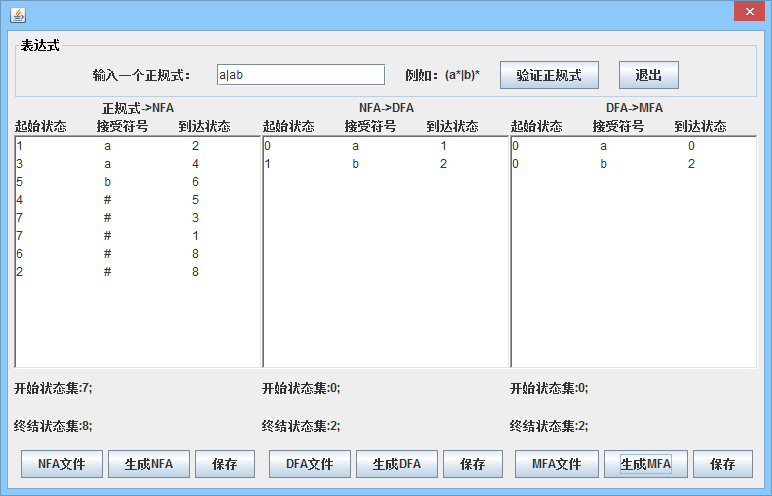
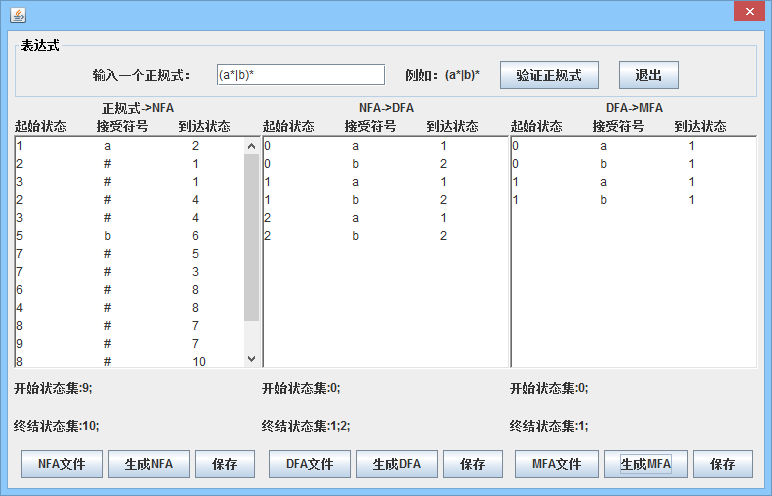
对正规式进行验证后,根据算法将其转换为NFA,得到起始符号集,最终符号集和符号集,并激活NFA到DFA的功能; 也可以单击打开按钮以选择符合规范的格式的NFA文件,并激活NFA转换为DFA的功能; 它还可以保存获得的NFA。
算法的主要实现步骤
- 首先构造识别和字母表中一个符号的NFA。

以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: