基于微博数据的用户画像系统的设计与实现毕业论文
2020-02-19 18:14:54
摘 要
本课题利用真实的微博用户数据针对微博用户制作用户画像系统,通过对微博用户的数据分析,给微博用户打上高度概括的短文本标并绘制各种图表,用于更加全面形象的描述微博用户。微博用户最后的分析结果以网页的形式呈现,所得结果对于企业营销人员、管理者、产品人员、运营人员和数据分析师具有重要的指导意义。
本系统的核心在于数据的爬取,用户画像系统对用户的描述是否全面准确且突出特点,主要在于数据爬取得是否全面,从系统最后制作的成果来看,也可以证明这一点。
本系统的特色在于不仅对用户有着精炼概括的短文本标签,还有各种统计图表,对微博用户有着比较全面的描述。除此之外本系统还分为单人用户画像和批量用户画像两种,不仅可以对单人进行全面的描述,还可以分析出部分用户群里的共同特点与爱好等。
关键词:用户画像;大数据;K-means聚类算法;
Abstract
This topic uses the real Weibo user data to create a user portrait system for Weibo users. Through the data analysis of Weibo users, the Weibo users are given a high-summary short text mark and draw various charts for a more comprehensive image. Describe Weibo users. The final analysis results of Weibo users are presented in the form of web pages. The results obtained are of great guiding significance for corporate marketers, managers, product personnel, operators and data analysts.
The core of the system lies in the data crawling. Whether the description of the user by the user portrait system is comprehensive and accurate, mainly depends on whether the data crawling is comprehensive. From the results of the final production of the system, this can also be proved.
The system features a short text label that not only refines the user, but also various statistical charts, which have a comprehensive description of Weibo users. In addition, the system is divided into single user portraits and batch user portraits. It can not only describe a single person in a comprehensive way, but also analyze the common characteristics and hobbies in some user groups.
Key words:user profile; large data; K-means clustering algorithm;
目 录
第1章 绪论 1
1.1 背景 1
1.2 研究目的与意义 1
1.3研究现状 2
1.4设计思想 2
1.5相关算法介绍 3
第2章 画像系统需求和可行性分析 4
2.1 系统需求分析 4
2.1.1 系统功能需求分析 4
2.1.2 系统性能需求分析 7
2.2微博数据获取分析 7
2.3系统可行性分析 10
第3章 画像系统概要设计 11
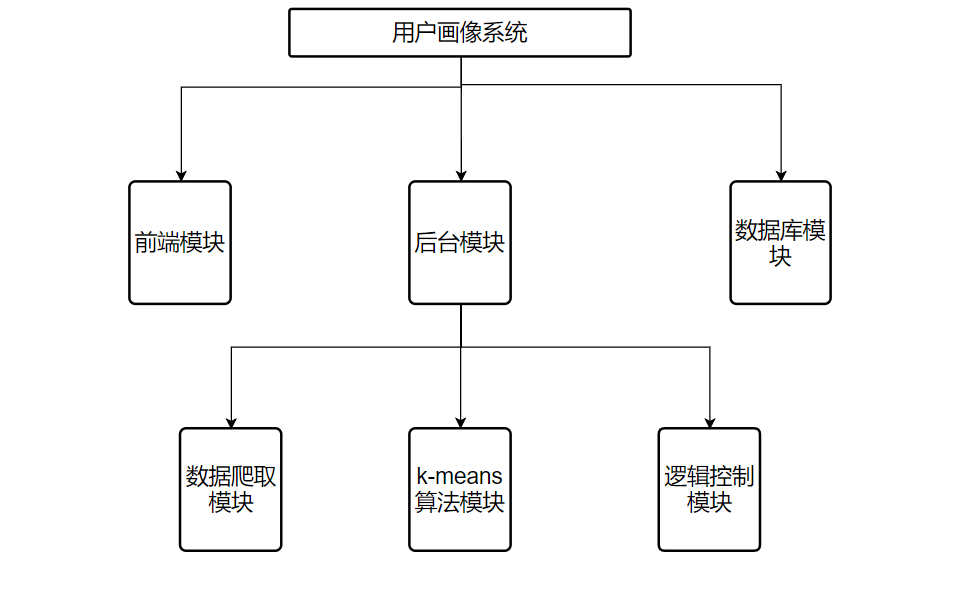
3.1系统总体设计 11
3.2系统功能设计模块 11
3.3数据库逻辑结构设计 13
第4章 画像系统详细设计 14
4.1数据库设计 14
4.2系统各功能模块实现 16
4.2.1 前端模块实现 16
4.2.2 后台模块实现 17
4.2.3 数据库模块实现 19
第5章 画像系统测试与结果分析 21
5.1系统测试方法与意义 21
5.2系统测试过程与结果分析 21
5.3系统测试结果 22
5.4本章小结 23
第6章 总结与展望 24
第1章 绪论
背景
“大数据”英文全称big data,这一词首次使用是在1997年,直到2005年时谷歌参加由美国官方举办的一个机器翻译大赛,最终由于使用了海量的相关数据而夺得第一,致使 “大数据”这个概念渐渐的被业内人士所传播,后来于2007年左右风靡媒体被更多人所知晓。现如今的每一个行业和业务职能领域中都会有大数据的身影,这使得它成为了当今世界一个非常重要的生产因素。伴随着大数据和生产力的发展,越来越多的企业开始关注产品的质量和成本问题,这势必就要从用户的角度出发分析用户需求, “用户画像”的概念也逐渐形成,最早是由“AlanCop⁃ per”提出的,即为“UserPersona” [1]。“用户画像”作为大数据的根基,它将抽象出一个用户的信息全貌,为进一步精准、快速地分析用户行为习惯、消费习惯等重要信息,提供了足够的数据基础。
微博作为最大的中文社交媒体,拥有数以“PB”(1024 TB)计的用户信息,每天都有丰富的信息在其上发布与传播,所以一个基于微博数据的用户画像系统的诞生是必然的。借助微博这样一个庞大的数据集,可以更加全面真实的还原出每一个活跃在微博上的用户,通过用户的基本信息和在微博上的动态分析可以得出用户的兴趣爱好、生活习惯等。这不仅有助于企业的精准营销,还可以提高被服务者的用户体验。
研究目的与意义
无论是一个企业想要更加具有竞争力,还是一个互联网产品想要做的更加贴合用户需求更具有市场,都缺少不了大数据技术[2],更精确的说是缺少不了对用户的大数据挖掘和分析,只有明确得了解用户的特点与需求才能做出更好产品提供更好的服务,提升企业或是产品的竞争力。
用户画像在不同时期、不同的领域与学科中可能有着不同的理解,但其本质是相差不多的。本系统主要将用户信息分成了两大部分,第一部分是用户属性,其中又分为用户静态属性和动态属性,第二部分是用户特征属性。用户属性是用户直接产生的信息,其中静态属性即用户的基本信息,如性别,年龄等;动态属性即为用户行为所产生的信息,如用户的关注、粉丝和微博数等。用户特征属性是从用户的基本属性中总结分析产生的[3],如通过用户关注的博主类型得出用户的爱好等。
本系统目的就是在微博庞大繁杂的用户数据基础上分析、统计、抽取用户的信息,抽象出高度精炼概括的短文本标签,这些标签通常通俗易懂,然后用这些标签描述用户,并尽可能的还原出用户的全貌,这为企业了解用户的特征爱好,实行精准营销,提高用户体验有着非凡的意义。
1.3研究现状
近几年来随着大数据的发展,数据分析工具也变得日益成熟,用户画像相关的研究工作也逐渐成为国内外关注的热点,相关的研究成果也不断变多。
在用户画像的研究成果方面,国内的研究成果还是比较少[4],且主要分布于学术界,其中比较多的在计算机科学、心理学等领域。少数比较大型的企业已经做出比较成熟的用户画像分析工具,例如阿里云画像分析,已经将画像技术应用在广泛的场景中[5],还有百度智能云、神策数据等。
在算法方面,现在可以用到的特征提取方法有很多,如k-means、LDA、NB、CNN等,K-means算法的优点在于可以在无标签的情况下进行聚类分析,并且实现也相对简单,缺点是实验初始值和噪声点对结果影响比较大,容易陷入局部最优的结果;LDA适用于文档比较大的情况,NB算法所需要的参数少,算法也比较简单容易实现;CNN提高了模型的准确度,有优异的特征自抽取能力[6]。
从总体上来看,用户画像的研究现在还处于一个蓬勃发展期。在大数据发展的背景中,随着研究的深入,用户画像发挥了越来越重要作用。
1.4设计思想
通过翻阅大量的文献和资料并结合系统的设计需求,决定本系统的主要设计思想是先采集大量的微博用户信息,然后通过聚类和统计等方法分析得出文本标签,并反馈在多个个html格式的也页面上。
采集用户数据是最为核心的部分,用户数据需要比较全面才可以比较完整的描绘出用户画像,必要时需要添加图表统计用户的相关信息。标签分为用户的静态属性标签、动态属性标签和一个用户类型标签,静态属性标签显示用户的基本属性。动态属性标签显示用户的粉丝、关注和微博数量,需加上统计图表并加以分析;用户类型标签需要用到聚类算法,寻找最优的分类个数并为用户打上用户类型标签。
由于python有较为全面的数据分析库、成熟的程序包资源库并且可方便快捷的实现数据可视化[7],所以编程语言选择python。编译环境则选择了pycharm,前端界面则选择了用python下的Django框架,同时还需要用到bootstrap框架。
1.5相关算法介绍
本系统主要用到的算法是k-means聚类算法,是一种典型的聚类算法。它与kNN有类似之处,均利用近邻信息来标注类别,但他们确是两类算法,kNN为监督学习中分类算法,k-means则为无监督学习中的聚类算法。机器学习中监督学习是给定一组数据我们知道正确的输出结果应该是什么样子,并且知道在输入和输出之间有着一个特定的关系,而无监督学习中,我们基本上不知道结果会是什么样子,但我们可以通过聚类的方式从数据中提取一个特殊的结构,给出的数据是与监督学习中不一样的。在无监督学习中给定的数据没有任何标签或者说只有同一种标签。k-means算法就是最为经典的无监督学习算法中的一个。K-means算法只有一个数据集对象,在处理图像和数据集方面表现很好,具有很好的聚类能力还不会受到数据集顺序的影响且比较好实现。
下面介绍k-means算法的原理。k-means算法中的k代表类簇的个数,means代表类簇内数据对象的均值,因此又被成为k-均值算法。算法过程开始是从n个数据中先找k个对象作为初始的聚类中心,然后计算每个对象到各种子聚类中心之间的距离,常用计算距离的方式有:余弦距离、欧式距离、曼哈顿距离等,最后把对象分配到距离最近的一个聚类中。这个算法是一个不断迭代的过程,当全部对象被分配完后,每个聚类的聚类中心会根据分配到的对象再被重新计算,直到聚类中心不在发生变化,计算停止。
第2章 画像系统需求和可行性分析
2.1 系统需求分析
系统需求分析在软件计划阶段是非常重要的,系统需求分析是否合理完善可能直接决定了软件的质量。需求分析如果做得不够完善将会在软件开发的过程中带来很多困难,例如业务流程和代码模块设计的不合理会导致模块之间的冲突,最终导致软件开发失败[9]。
2.1.1 系统功能需求分析
在功能需求分析阶段,本文都采用UML(UML modeling technology)进行需求分析。需求分析时UML建模语言是最为常用的。UML一共定义了9种模型图,分别是用例图、类图、对象图、状态图、活动图、序列图、协作图、构件图和部署图。在需求分析阶段主要使用类图、用例图、协作图、顺序图和状态图从面向对象的角度出发来定义应用需求[10]。
(1)用例图
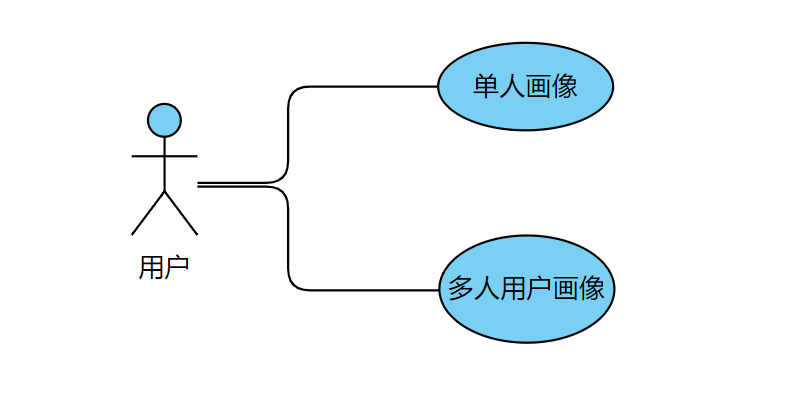
图2.1 用户访问用户画像系统用例图
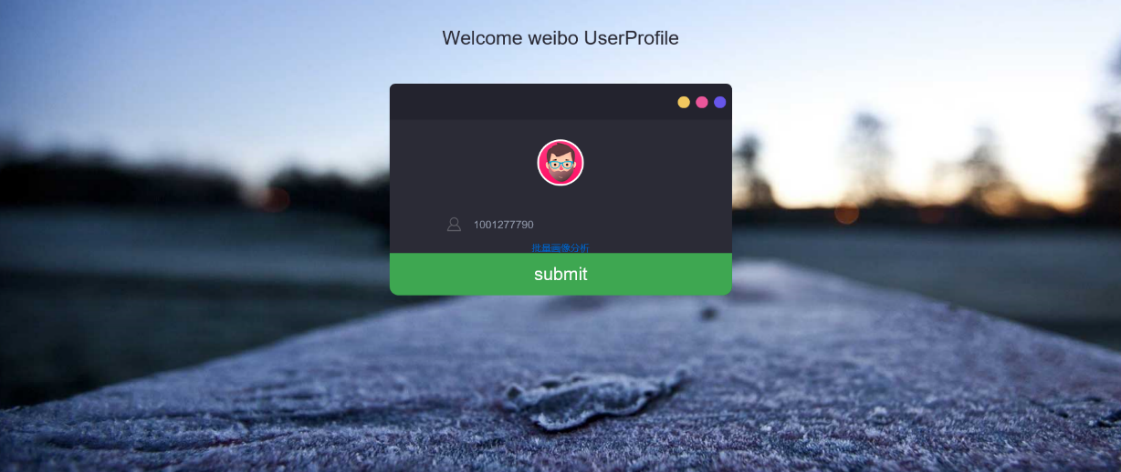
本系统有两种功能,用户可以选择单人用户画像或者是多人用户画像。
首先用户打开欢迎界面,该界面默认为单人用户画像的欢迎界面,用户可以在输入框中输入想要得到画像的用户uid,点击提交即可跳转到单人用户画像系统主界面,主界面上的内容分为单人用户画像即用户短标签、用户行为分析和用户爱好分析三种,用户可滑动页面查看。
表2.1 单人用户画像用例规约
用例名称 | 单人用户画像 |
用例功能 | 在主界面显示uid对应的用户画像分析结果 |
用例编号 | 1 |
前置条件 | 用户欢迎界面能被正常访问 |
后置条件 |
|
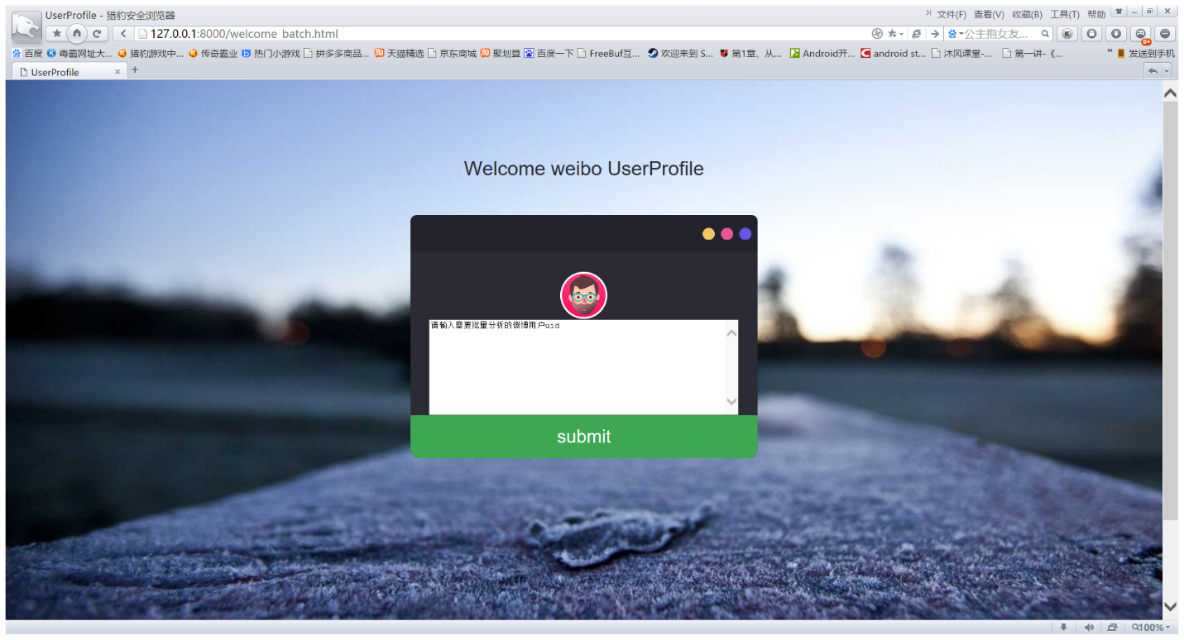
多人用户画像页面布局与单人用户画像一致,不同的地方在于多人用户画像的欢迎界面需要用户手动输入想要分析的uid并以逗号隔开,提交之后进入多人用户画像主界面,即可查看多人用户画像分析结果。
表2.2 多人用户画像用例规约
用例名称 | 多人用户画像 |
用例功能 | 在主界面显示对多个微博用户的用户画像分析结果 |
用例编号 | 2 |
前置条件 | 用户欢迎界面能被正常访问 |
后置条件 |
|
(2)类图
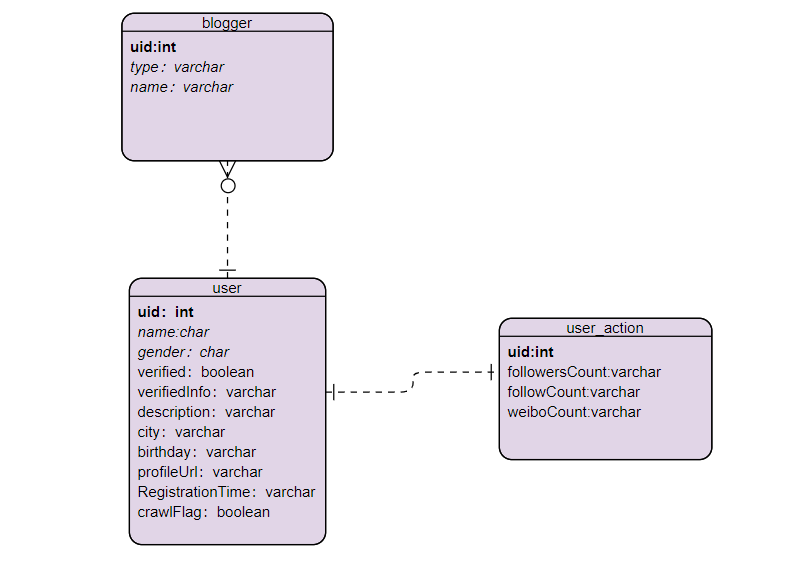
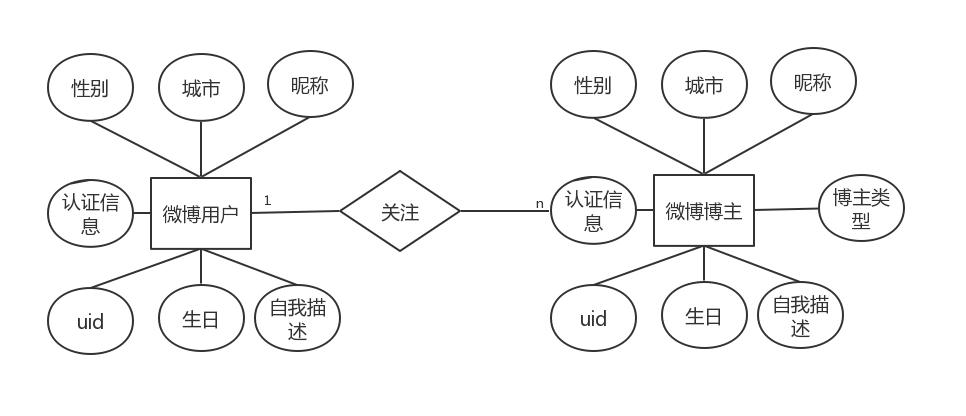
图2.2 用户画像系统类图
本系统有用户基本信息、用户行为信息和关注博主的信息。一个微博用户对应一个uid,其他基本信息有昵称、性别、认证信息和居住地等,且一个用户对应一个用户行为信息,这是一个动态信息,会随着用户的行为不断改变。一个用户可以关注多个博主,博主也是微博用户,但博主会比普通用户多一个用户认证类型。
(3)顺序图
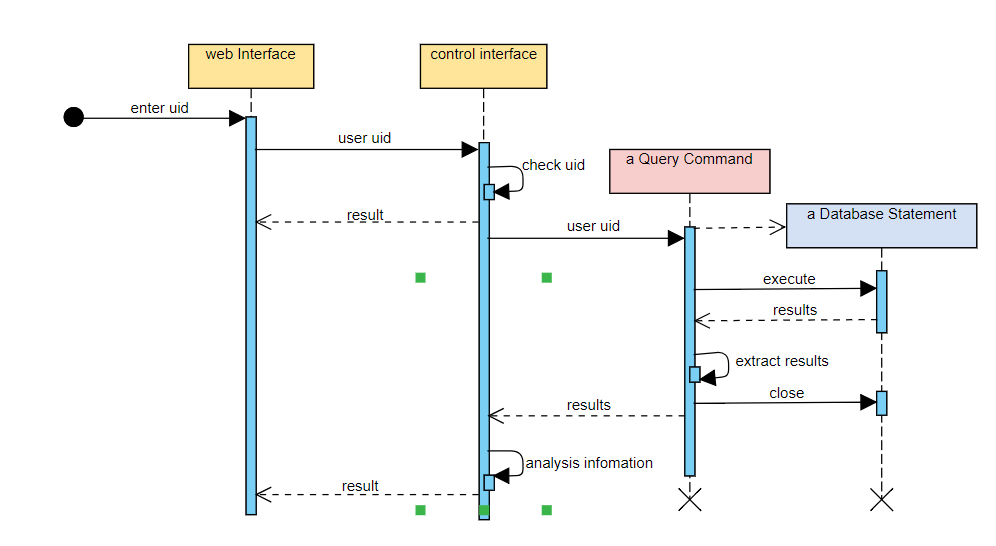
图2.3 用户画像系统顺序图
首先用户需要在前端web界面输入微博用户的uid,uid由前端界面传入后台,后台控制层将会对uid的正确性做一个校验,如果输入格式错误返回结果到前端界面,正确则到数据库中查询该用户的信息,查询到该用户信息返回给控制层,控制层再对返回的用户信息结果做分析,分析后的结果再返回到前端web界面。
(4)状态图
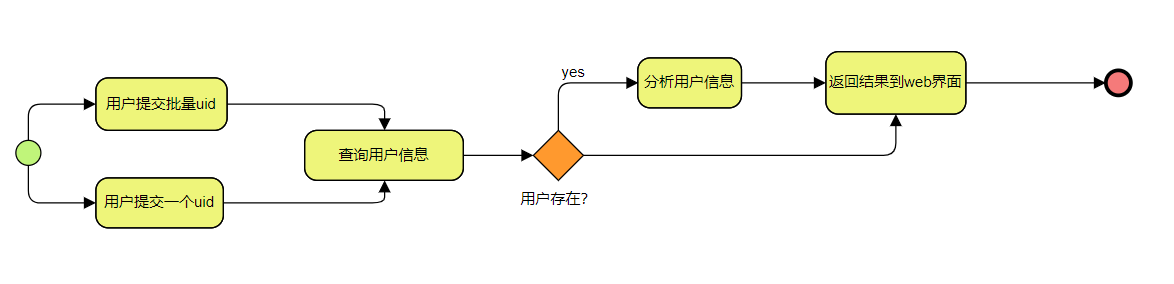
图2.4 用户画像系统状态图
2.1.2 系统性能需求分析
(1)系统安全性需求分析
系统安全性分析是软件开发的重要环节,这个环节通常从概要设计才开始,忽略了从需求分析开始注意软件系统的安全问题[12],故本系统从需求分析开始进行软件的安全性分析。本系统是一个轻量的小系统,访问量小,功能不复杂,不涉及到用户的隐私信息,泄露信息的几率小。在批量用户画像功能上也有用户uid输入数量限制,所以本系统基本不存在安全隐患。
(2)响应速度需求
本系统需要处理的数据量较小,访问及跳转页面基本可以控制在500ms以内。
2.2微博数据获取分析
微博数据的获取是这个系统最为基础的部分,需要有大量的数据信息作为支撑这个系统才能得以完成。为了获取微博的用户信息,需要用到爬虫一类的相关技术。爬虫就是按照一定的规则,在因特网上抓取信息的脚本。爬虫所涉及到的技术有BeautifulSoup、request和Ajax。BeautifulSoup可以抓取到网站的html代码,是一个python写的HTML/XML的解析器。request是python的一个HTTP客户端库,提供了大量的HTTP功能,网络数据爬取很多地方需要用到request库。Ajax是指一种创建交互式网页应用的网页开发技术,在网页开发时经常使用。
爬虫首先选择要爬取的网页,而随着智能手机的广泛使用,现在很多人都用手机浏览器浏览网页,相应的就出现了两种网页类型,一种是手机端网站另一种是电脑端网站。这两种网站最直观的区别就是二级域名不一样,目前有三种不同的二级域名,m、www和wap,网络上常常称作m站、pc站和wap站。www是我们最常见的一个域名,一般是使用在pc端的域名。而m是移动的缩写和wap是无线应用的缩写,顾名思义这两个站一般是使用在手机端的域名,在一般情况下做爬虫爬取网站时,首选的一般是m站,其次是wap站,最后是pc站,因为pc站的通常是各种验证是最多的,但是pc站的信息也通常最全。本系统虽然需要比较全面的用户信息爬取,但是pc站由于各种验证的原因不能完全爬取到用户信息,下比较之下发现m站的信息也基本可以满足系统的需求,所以最后选择爬取m站的信息。
新浪微博在2017年发布微博的PWA版本,全称Progressive Web Apps(渐进式网络应用),由谷歌主导推出,主要的特性是让Web App的体验能更接近原生应用,显著提高应用加载速度,甚至可以在离线状态下运行,类似于一个轻App——最主要的优点是其信息流是按照发布时间排列没有被打乱。PWA版主要是应用在手机端,其二级域名都是m,所以本系统的数据获取将从微博PWA版入手。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: