“看图写诗”--基于图像内容的古诗检索毕业论文
2020-02-19 18:14:34
摘 要
诗歌是世界上最重要的文学之一,同时也是最受欢迎的文学之一,具有极大的研究价值。而写出一首优秀的诗歌通常需要具备深厚的文学素养,普通人很难写出精彩的诗歌。如何利用计算机技术从语料库中学习诗歌的创作知识、由机器自动生成诗歌成为了研究热点。
本文以自然语言处理技术和图像描述技术为基础,提出了一种中国古典诗歌自动生成模型,该模型可以生成与图像内容相关的诗歌作品。本文主要基于keras中的VGG16模型,完成对图像的英文标签提取,利用百度翻译api将标签翻译成中文,然后将中文标签作为古诗生成模型的输入生成一首诗。古诗生成模型基于RNN(Recurrent Neural Network),采用LSTM(Long Short-Term Memory)算法。
研究结果表明使用VGGNet和RNN模型自动生成古诗是可行且成功的,生成的古诗和图像具有一定的关联性。
关键词:深度学习;神经网络;古诗生成
Abstract
Poetry is one of the most important and popular literature in the world and has great research value. While writing a good poem requires profound literary skills, it is difficult for ordinary people to write a good poem. How to use computer technology to learn poetry creation knowledge from corpus and automatically generate poetry by machine has become a research hotspot.
Based on natural language processing technology and image description technology, this paper proposes an automatic generation model of Chinese classical poetry, which can generate poetry works related to image content. This paper is mainly based on the VGG16 model in keras to complete the extraction of English tags of images, and then use the baidu translation API to translate the tags into Chinese, and then use the Chinese tags as the input of the ancient poetry generation model to generate a poem. The generation model of ancient poetry is based on RNN (Recurrent Neural Network) and LSTM algorithm is adopted to generate ancient poetry.
The research results show that it is feasible and successful to use VGGNet and RNN model to automatically generate ancient poems, and the generated ancient poems and pictures have certain relevance.
Key Words:Deep learning; Neural network; Poetry generation
目 录
第1章 绪论 1
1.1 研究背景、目的及意义 2
1.2 国内外研究现状 2
第2章 背景知识 3
2.1 VGGNet 4
2.2 RNN循环神经网络 5
2.2.1 RNN循环神经网络介绍 5
2.2.2 RNN循环神经网络应用 8
2.2.3 LSTM算法 8
2.3 TensorFlow 9
第3章 自动生成古诗研究 12
3.1 词嵌入 12
3.2 数据集 12
3.3 模型研究 12
第4章 实验过程 14
4.1 实验安排 14
4.2 预处理 14
4.3 构建模型 15
4.3.1 组织数据集 15
4.3.2 编写训练模型 16
4.3.3 编写预测模型 17
4.3.4 图像标签提取 17
4.4 训练 18
4.4.1 参数设置 18
4.4.2 训练截图 18
4.5 古诗生成 18
第5章 评价与分析 20
5.1 生成古诗举例 20
5.2 评价方法 23
5.3 评价得分 24
5.4 分析与总结 24
参考文献 27
致 谢 28
第1章 绪论
1.1 研究背景、目的及意义
古诗是我国独特的传统古典文化的一种形式。它起始于先秦,兴盛于唐宋,迄今为止已经有了两千多年的悠久历史。古诗的背诵是学生时代必经的事情,今天人们几乎都能随口吟出一首古诗,但是所吟出的诗句往往是前人之作,要写一首好诗需要掌握深厚的文学技巧,很难完成。近年来深度学习在自然语言处理上成果颇丰,效果显著。如机器翻译,图像识别等,在当今日常生活中很常见实用。如何利用计算机技术从语料库中学习古诗的创作知识、由机器自动生成诗歌成为了研究热点。
在现代社会,中国文化受到全世界人民的喜爱。不可否认,中国古典诗歌是中国特有的文化遗产之一。中国被称为“诗歌王国”,这不仅因为中国诗歌的悠久历史,也因为诗人和作品的数量。诗歌是所有语言的载体,是最原始,最真实的艺术。有的诗歌带有一定的韵律,对仗工整,要求较为严格,而有的诗歌则不讲究对仗,押韵也比较自由。古典诗歌有着两千多年的悠久历史,它体现在人们生活的许多方面,例如,作为一种记录重要事件的方法,表达个人情感,或在特殊节日中传达信息。
随着技术的飞速发展,中国古典诗歌的自动生成在近几十年来受到了相当多的关注,大量的计算系统被编写出来用于在线生成诗词。同时,随着人工智能的快速发展,关于自然文本图像的描述的研究也随之取得了卓越的发展,实现了机器对图像的读取和对图像内容的描述。但是在中国的传统文化中,人们更喜欢用古典抒发情感的诗歌,人们常称之为 “山水抒情”。因此,本文提出了一种基于图像生成古诗的方法,这不仅有助于对机器学习的深入了解,还有利于对中国传统文化的认识和弘扬。
1.2 国内外研究现状
利用计算机生成诗歌的这项工作,最早起始于20世纪70年代。早期的方法是把各种各样的字词杂糅在一起,随机生成“诗”。近些年来,国内外还有不少关于计算机生成诗歌的研究。比如基于模板的方法,这种方法是将一首现有的诗歌去除一些字词后,用一些其他字词进行代替,以此来产生一首新的诗歌[1]。这种方法所生成的诗歌虽然在语法上有一定的提高,但是不太灵活。后来有了基于模式的方法,这种方法对每个词语的词性进行限制,设置诗句的韵律平仄,从而生成诗歌。再之后出现了基于遗传算法的方法,即将诗歌生成看成状态空间搜索问题,对产出的随机诗句借助人工定义的诗句评估函数,不断进行评估优化,最终得到诗歌[2]。此外,还有基于统计机器翻译的方法,将诗歌生成当作为机器翻译,将一句诗看成源语言,将对应的下一句当作目标语言,添加韵律平仄等约束,用机器翻译模板生成对应的下一句诗歌,循环生成直到生成完整诗歌。
以上这些方法,诗句会缺乏一定的灵活性和连贯性,并且还需要设计许多人工规则,并对生成的诗歌的韵律进行限制(比如几年前就学会了写中文诗的微软小冰)。但是,随着计算机性能的大幅度提升以及深度学习算法的改进,国内外关于计算机诗歌自动生成方面的研究,至今已经有了极大的改善和进步。比如,重庆大学的易勇利用隐马尔科夫模型、概率语言模型和基于转换错误率驱动的序列学习法分别建立了生成模型,能够得到对仗流畅的生成结果[3]。微软亚洲研究院与京都大学的部分学者共同创建了一个深度集成嵌入模型和一个基于RNN的生成模型,根据图像的特征和数据集中的skip-thought特征对嵌入模型进行训练,从扩展后的数据集中提取出更多有利于产生“诗意”的信息,最终完成由图像生成英文诗歌的任务[4]。四川大学的郭全、刘韦伯等提出了一种三阶段多模态的中国诗歌生成方法,使用层次关注的seq2seq模型,有效地捕捉语境中的人物,短语和句子信息,继而提高诗歌的对称性[5]。M.Ghazvininejad给出了一个名为Hafez的自动诗歌生成系统[6],对于一个任意话题,Hafez将展示一首英语现代诗歌。 该系统集成了递归神经网络(RNN)和有限状态接受器(FSA),通过调整各种风格配,Hafez可以让用户修改和修饰生成的诗歌。携程公司研发的Al产品“小诗机”通过建立海量的知识库,利用图像识别技术,使用LSTM、调优后的翻译模型算法和遗传算法,可以根据用户上传的风景照生成诗歌。
尽管如此,能由图像生成古诗的系统还很少,本文将尝试如何基于图像生成古诗,如何利用计算机技术完成对图像的识别,以及从语料库中学习古诗的创作知识、生成优雅的诗句是本研究的重点。
第2章 背景知识
2.1 VGGNet
VGG(Visual Geometry Group)是由牛津大学的K. Simonyan和A . Zisserman提出的一种卷积神经网络模型[7],也可以被称作为VGGNet。研究人员通过探索卷积神经网络的性能和深度之间的关系,反复堆叠2*2的最大池化层和3*3的小型卷积核,最终构建出了16~19层深的卷积神经网络,并且VGG获得了2014举办的大规模视觉识别挑战赛的亚军,在图像分类和目标定位上的top-5错误率为7.5%。到目前为止,VGGNet仍然被广泛使用,经常被用作于提取出图像的特征。
VGGNet的特点在于它全部使用3*3的卷积核和2*2的池化核,通过不断尝试加深网络结构来提升整体性能。由于参数量主要在最后的三个全连接层中,所以当其网络层数增加时,不会发生并不会参数量上的爆炸这一情况。同时,通过将2个3*3卷积层进行联合,转化为1个5*5的卷积层,通过将3个3*3卷积层进行联合,转化为1个7*7的卷积层。在参数量方面,3个3*3的卷积层是7*7的卷积层的一半,但是3个3*3卷积层具有3个非线性操作,而7*7卷积层只具有1个非线性操作,于是使用3个3*3卷积层会加强对特征的学习能力,从而学习到更大的空间特征。
VGGNet使用了1*1的卷积层来增加线性变换,并没有改变输出的通道数量。1*1的卷积层常被用来提炼特征,即多通道的特征组合在一起,凝练成较大通道或者较小通道的输出,而每张图片的大小不变。有时1*1的卷积神经网络还可以用来替代全连接层。VGGNet为了使收敛速度更快,VGGNet先训练简单网络,再使用简单网络的权重来初始化之后的复杂模型。VGGNet的作者总结出:使用越深的网络,得到的结果越好,但是LRN层所能做到的事情并不多,同时1*1的卷积虽然没有3*3的卷积效果好,但是也是有效的。
VGGNet的网络结构如图2.1所示。VGGNet包含许多不同级别的网络,深度从11层到19层不等,其中比较常用的是VGG16和VGG19。VGGNet把网络分成了5段,每段都把多个3*3的卷积网络串联在一起,每段卷积得后面接一个最大池化层,最后面是3个全连接层和一个softmax层。
图2.1 VGGNet各级别网络结构图
2.2 RNN循环神经网络
2.2.1 RNN循环神经网络介绍
循环神经网络RNN(Recurrent Neural Network)是一种每个节点之间定向联接成为环状的人工神经网络[8],它在自然语言处理(NLP)、语音识别、图像识别等多个领域都得到了极其广泛的应用和发展。RNN能够实现某种“记忆功能”,这是它和其他神经网络最明显的区别,在分析时间序列时选择RNN是最为明智的。RNN实现了类似于人脑利用记忆不断学习的这一机制,适当保留所处理过的信息,而其他神经网络往往不会做到这一点。在RNN之前的网络模型,是由输入层到隐含层,再由隐含层到输出层的,每一层是互相连接的,每层之间的节点是没有连接的。因为其网络结构的问题,造成了它在面对序列问题或者和时间密切相关的问题的时候,表现出的能力较差。打个比方,假如我们要估计一个句子的下一个单词,通常情况下要用到前面的那个单词,这是由于句子中先后单词不是互相独立的。RNN可以具体表现为网络会对前面的信息进行记忆,然后将其记忆的信息参与到当前输出的计算之中,也就是说隐含层之间的节点由没有连接而变得有连接,并且隐含层的输入既包含了输入层的输出,又包含了上一时刻隐含层的输出[9]。理论上,任何长度的序列数据都可以由RNN进行处理。但是在实际操作中,为了降低复杂性,一般都会假设当前的状态只与前面的几个状态相关。典型RNN结构图如图 2.2所示。
2.2所示。
图2.2 典型RNN
RNN包含输入单元(Input units),我们把输入集记为{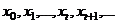 },还包含输出单元(Output units),我们把输出集记为{
},还包含输出单元(Output units),我们把输出集记为{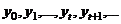 }。此外,RNN还包含隐含单元(Hidden units),我们将其输出集记为{
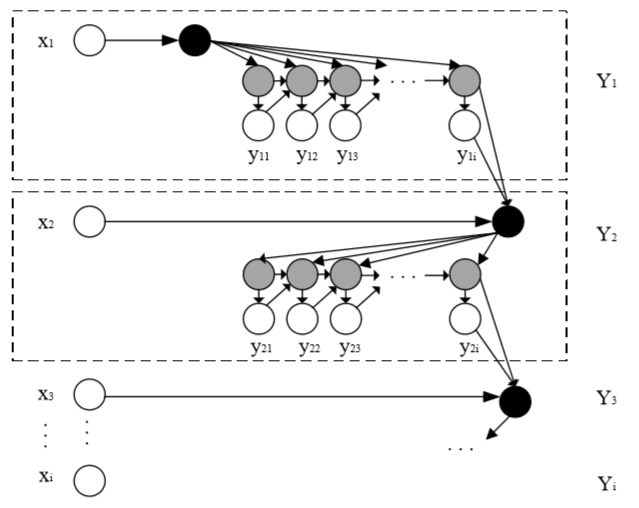
}。此外,RNN还包含隐含单元(Hidden units),我们将其输出集记为{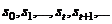 },最为主要的事情就是由这些隐含单元完成了。其中图2.3的右边可以看到:有两个单向的箭头代表着信息流的单向活动,分别是从输入单元到隐含单元的流动和从隐含单元到输出单元的流动。但是图中还有一个回流箭头,这代表着有些时候,RNNs会突破从隐含单元到输出单元的束缚,指引信息从输出单元回流到隐含单元,这种情况被叫做“Back Projections”。这会造成隐含层的输入不光包含当前状况,还包含上一隐含层的状况,也就是说隐含层内的节点能够自连也能够互连。
},最为主要的事情就是由这些隐含单元完成了。其中图2.3的右边可以看到:有两个单向的箭头代表着信息流的单向活动,分别是从输入单元到隐含单元的流动和从隐含单元到输出单元的流动。但是图中还有一个回流箭头,这代表着有些时候,RNNs会突破从隐含单元到输出单元的束缚,指引信息从输出单元回流到隐含单元,这种情况被叫做“Back Projections”。这会造成隐含层的输入不光包含当前状况,还包含上一隐含层的状况,也就是说隐含层内的节点能够自连也能够互连。
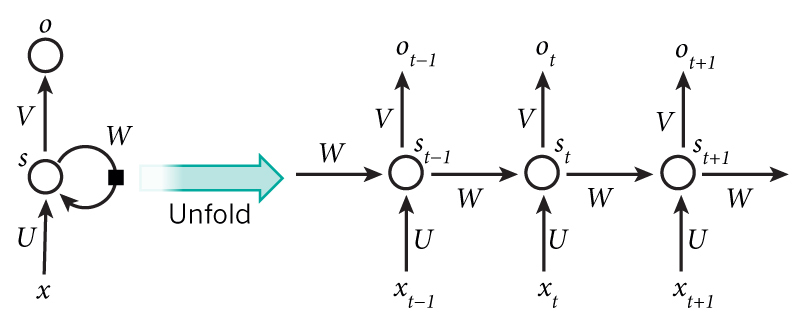
图2.3循环神经网络展开图
上图2.3将循环神经网络进行展开形成了一个全神经网路,该网络的计算过程如下:
(1)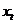 表示第t,t=1,2,3...步(step)的输入。比如
表示第t,t=1,2,3...步(step)的输入。比如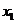 为第二个词的one-hot向量(根据上图2.2,
为第二个词的one-hot向量(根据上图2.2,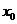 为第一个词);
为第一个词);
(2)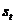 为隐含层的第t步的状态,它可以记忆。
为隐含层的第t步的状态,它可以记忆。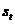 按照当前输入层的输出与上一步隐含层的状况进行计算。
按照当前输入层的输出与上一步隐含层的状况进行计算。
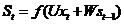 (2.1)
(2.1)
其中的f通常情况是非线性的激活函数,有tanh,ReLU等。在求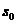 时,也就是第一个单词的隐含层状态的时候,需要
时,也就是第一个单词的隐含层状态的时候,需要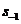 的数据,可是不存在这个数据,所以在实际实现过程中常设为0向量。
的数据,可是不存在这个数据,所以在实际实现过程中常设为0向量。
(3)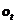 是第t步的输出,如下个单词的向量表示
是第t步的输出,如下个单词的向量表示
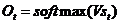 (2.2)
(2.2)
需要注意的是:
(1)St可以认为是网络的记忆单元,为了下降网络的复杂度,通常St只包含前面几步而非全部步的隐含层状况;
(2)与传统神经网络不同,在RNN中,每一层可以共享网络参数。也就是说,RNN只有输入不一样,但是每一步做着相同的事情,由此很大程度上下降了网络中需要学习的参数;
(3)每一步需要输入或输出都不是必须的。RNN最主要在于隐含层,它可以捕捉序列的信息。
2.2.2 RNN循环神经网络应用
当今有许多的实践证明RNN对NPL(神经语言程序学)是颇有成效的,如词向量表达,语句合法性测试,词性标注等。具体的来说,有语言模型与文本生成(比如自动生成诗歌),机器翻译(比如中英文互译),语音识别(比如车载导航),图像识别生成(比如识图造句)等[10]。在RNN中,当今运用最多最实用的模型即是LSTM(Long Short-Term Memory,长短时记忆模型)模型。该模型相比普通RNN,往往能够更好地对长短时依赖进行表达,它只是在隐含层与普通RNN有些不同。
2.2.3 LSTM算法
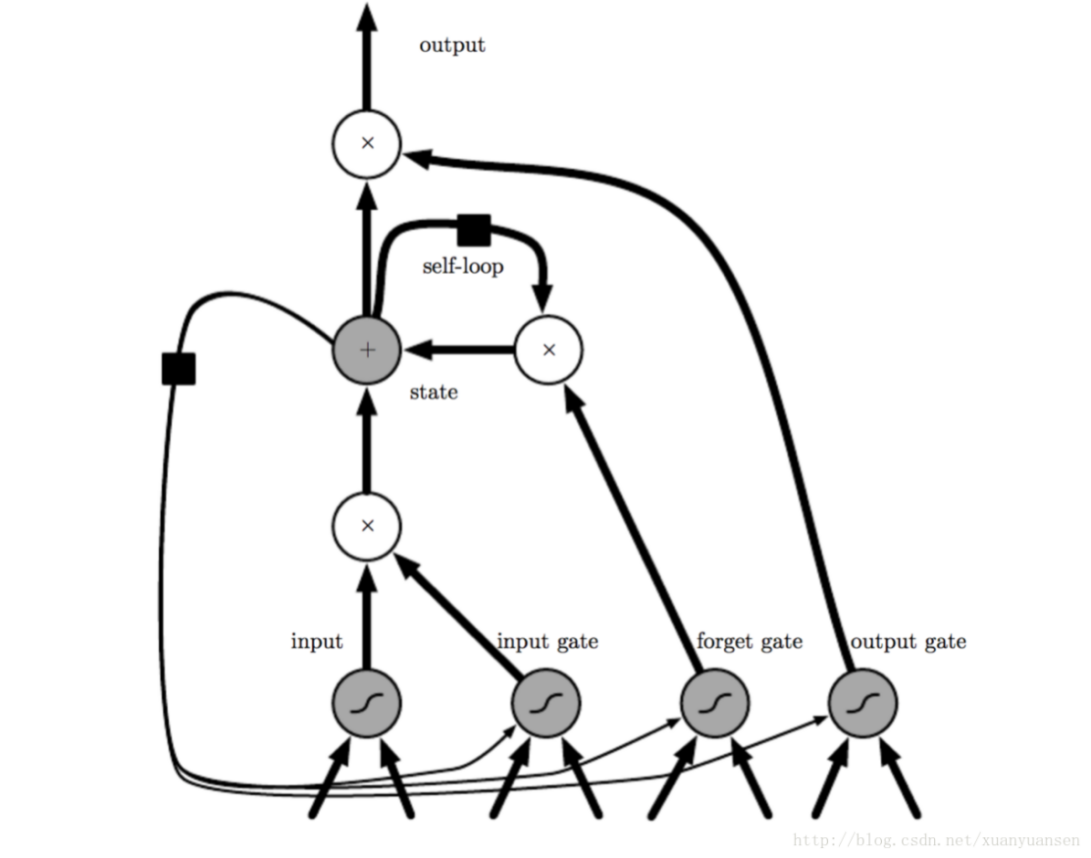
LSTM(全称Long Short-Term Memory)中文叫做长短期记忆网络,它是时间递归的神经网络,非常擅长处理时间序列间隔较远,延迟较长的节点之间的联系。这种LSTM算法最早是由Hochreiter S和 Schmidhuber J于1997年提出的[11],是一种特定形式的RNN。RNN在长期依赖方面有很大的阻碍,它在计算时间序列间隔较远的节点之间的联系的时候,会遇到雅克比矩阵的多次相乘,这经常会造成梯度消失的问题,有时候还会造成梯度膨胀的问题。很多学者发现了这个问题,自主研究后,提出了很多应对方法,包括回声状态网络ESN(Echo State Network),增加有漏单元(Leaky Units)等等。这许许多多的方法里最为成功,且用的最多的便是门限RNN(Gated RNN)。有漏单元设计了一个连接间的权重系数,通过这样的方法让RNN可以进行长期依赖的累积;而门限RNN是这个思想的泛化,它可以在不同时间,系数也改变,还能让网络忘掉当前累积的信息。
LSTM便是这样的门限RNN,也是门限RNN中最成功有名的一种,其单一节点的布局结构如以下的图2.4所示。LSTM添加了三个门限,分别为输入门限,遗忘门限和输出门限,这就是它巧妙的地方,因为这使得自循环的权重是变化的,这样做让不同时间的积分尺度能够动态改变,自然避免了之前提到的梯度消失和梯度膨胀的问题。当一个信息流入LSTM的网络之中,可以按照规则来判定是否有用。仅有匹配算法认证的信息才会留下,不匹配的信息则会通过遗忘门限遗忘。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: