微信平台朋友圈信息分析系统的设计与实现毕业论文
2020-02-19 18:14:17
摘 要
随着web2.0时代的发展,今天的互联网已经从单一的搜索引擎至上过渡到全员社交,社交方式也从即时通讯逐渐向动态社交转化。微信随着版本迭代,功能日趋丰富,已逐渐发展成为人们生活和工作中信息交流和社交活动的重要工具。作为微信最重要的功能之一,微信朋友圈在当前的网络社交媒体中具有很强的代表性,它不仅极大的改变了人们的社交模式和信息交流习惯,而且为很多企业的营销和布局提供了一些新的机会与思路,值得我们对其内容进行挖掘。本文将主要从微信朋友圈的用户信息入手,进行深入分析。
近年来提出了LDA模型(文档生成模型,Latent Dirichlet Allocation模型)针对文本格式的复杂性和难以直接进行分析计算的特点,将文本数值化,并采用贝叶斯概率模型和词袋(bag of words)方法对特征稀疏、语义依赖强、不遵循语法等特点的短文本进行分析计算。
本文提出了一种以LDA主题模型为理论基础来计算好友相似度的思路,并使用该思路设计并实现了相应系统。主要包括以下步骤:构建语料库、获取主题分布、相似度矩阵计算、聚类分析、隐藏人际关系挖掘。测试表明:主题提取结果符合预期,聚类结果符合感性分类结果。
关键词: 微信朋友圈;LDA主题模型;Gibbs抽样;好友相似度
Abstract
With the development of the web2.0 era, today's Internet has moved from a single search engine to a full-time social interaction, and social interaction has gradually shifted from instant messaging to dynamic social interaction. With the iteration of the version, WeChat has become more and more abundant, and has gradually developed into an important tool for information exchange and social activities in people's lives and work. As one of WeChat's most important functions, WeChat's circle of friends is highly representative of current online social media. It not only greatly changes people's social patterns and information exchange habits, but also serves as marketing and layout for many companies. It provides some new opportunities and ideas, and it is worthwhile to mine its content. This article will focus on the user information of WeChat friends circle for in-depth analysis.
In recent years, the LDA model (document generation model, Latent Dirichlet Allocation model) has been proposed to quantify text and use Bayesian probability model and bag of words for the complexity of text format and the difficulty of direct analysis and calculation. The method analyzes and calculates short texts with features such as sparse features, strong semantic dependence, and non-compliance with grammar.
This paper proposes an idea to calculate the similarity of friends based on the LDA theme model, and uses this idea to design and implement the corresponding system. It mainly includes the following steps: constructing a corpus, obtaining topic distribution, similarity matrix calculation, and cluster analysis. Hide interpersonal relationship mining. The test shows that the topic extraction results are in line with expectations, and the clustering results are consistent with the perceptual classification results.
Key Words:WeChat circle of friends;LDA topic model;Gibbs sampling;friend similarity
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 2
1.2.1 文本分析综述 2
1.2.2 LDA研究进展 3
1.2.3 LDA改进扩展模型 3
1.3 课题研究内容 4
第2章 主题提取与聚类理论 5
2.1 lda主题模型 5
2.1.1 LDA贝叶斯模型 5
2.1.2 MCMC与Gibbs Sampling 5
2.1.3 LDA文本建模 7
2.1.4 使用Gibbs采样求解LDA 8
2.2 聚类算法 9
2.2.1 相似度计算 9
2.2.2 聚类方法 10
第3章 微信朋友圈信息分析系统设计 11
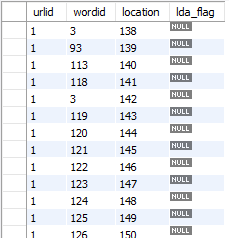
3.1数据库设计 11
3.2 分析流程设计 12
第4章 微信朋友圈信息分析系统实现 13
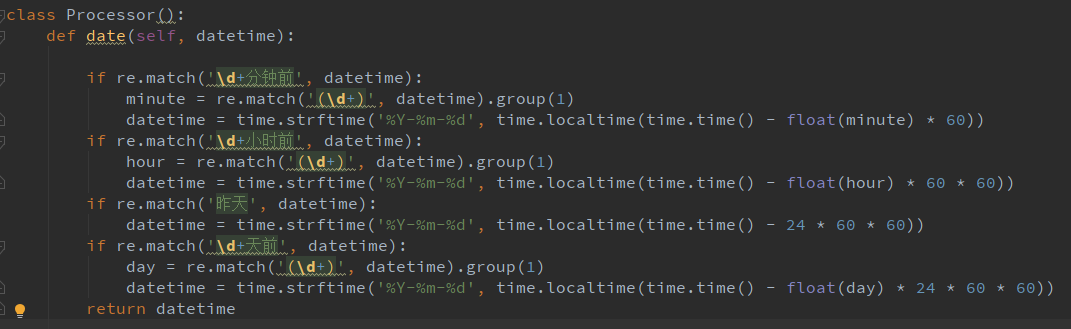
4.1微信朋友圈数据采集 13
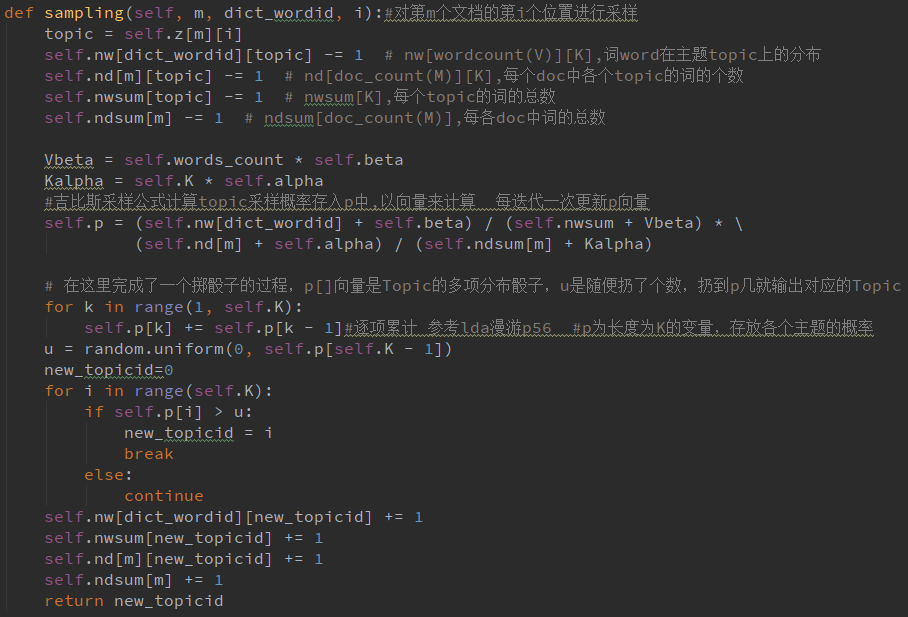
4.2 LDA-Gibbs模型 14
4.2.1 训练LDA模型 14
4.2.2 使用LDA模型获取分布 15
4.3使用k-means聚类方法 16
第5章 总结与展望 18
5.1 总结 18
5.2 展望 18
参考文献 19
致 谢 20
第1章 绪论
1.1 研究背景及意义
在互联网时代,国内外出现了大量的不同的社交媒体与平台。微信应用平台作为其中成功的典型,用户量得到抛物线式增长。截至2018年9月,微信月活用户达到10.82亿。在社交方面,有数据显示在2015年到2018年的三年内,朋友圈平均每日发布视频数量增长了480%。不难看出微信朋友圈的影响力在微信用户数量的增长下也水涨船高。在微信4.0版推出了“朋友圈”之前,微信只是一个即使通信工具,有了微信朋友圈的出现,由于好友之间动态可见,好友有了更多的话题,促进了人与人之间更多的链接。人与人之间在网络中的联系由之前的点对点联系,转变变成了一个更加密集、更加复杂的网络关系。有数据显示,关于分享动态时社交平台的选择,有32.5%的人选择微信朋友圈,17.5%的人选择电话和短信,16.3%的人选择QQ空间。这表明朋友圈已成为人们更加青睐的社交平台,在构建人际关系和分享个人信息方面有着独特的优势,。
随着微信朋友圈的影响力逐渐增大,学术界对微信朋友圈内蕴含的信息也日益关注。在CNKI中用“微信朋友圈”作为关键词查询,从共1334条结果的关键词与摘要中我们可以大概总结出目前国内学者对于微信朋友圈的研究有以下几个方面:一是从社交角度对微信朋友圈进行研究,如吴少琼在《社交关系视角下的微信朋友圈90后女性自拍研究》中指出了微信朋友圈在社交方面的作用;二是从传播角度来研究微信朋友圈,如张梦在《微信朋友圈信息流广告用户体验的影响因素研究》中研究适合微信朋友圈的营销模式;三是从心理学角度来研究微信朋友圈,如刘旦旦在《微信朋友圈中的自我呈现研究》中详细的分析了微信朋友圈的心理因素。不难看出目前对微信朋友圈的分析主要集中在人文社科领域。
然而微信朋友圈由一开始的熟人社交逐渐过渡到用户关系链的“泛化发展”。这体现在用户添加的微信好友,在初期可能数量较少,且大多为线下亲近的熟人。而后增加了公司里的同事老板,最后各种微商也慢慢加入到你的朋友圈。这使得微信朋友圈中成员组成、人际关系复杂多样,包含的信息爆炸式增长,传统的统计分析方法由于效率等原因具有很大的局限性。
本论文希望借助计算机手段,自动获取微信朋友圈的信息并进行分析。针对发布动态的文本信息进行主题提取并进行聚类处理,从而利用微信朋友圈的信息获得好友相似度数据,此数据可以作为对朋友圈中不同群体精准分析的依据。
1.2 国内外研究现状
1.2.1 文本分析综述
在这个互联网飞速发展的时代,互联网上的数据以指数级的速度迅速增长,我们逐渐进入了大数据时代。文本数据作为海量数据的主体部分,具有很大的挖掘价值。如何从海量的文本数据中快速、准确、全面地抽取出有价值的知识,并利用这些知识重新组织成人们所需要的信息成为学者关注的对象。文本分析的分析方向大概分为文本的特征提取、分类、相似度分析和情感分析等,通常可以使用基于句法-语义规则的方法或统计数学方法进行分析。在此基础上短文本分析通常有显性分析和隐性分析两种方式:
显性分析方法是对人来说更加容易解释的分析方法,包括词汇角度和句法角度等。这种方法的基础是拥有匹配的知识库。词汇角度的分析上,已有的研究包括WordNet、Hownet、哈工大同义词词林等;ESA算法构建一个词与文本的共现矩阵,词向量的每一个维度代表一个明确的知识库文本,如Wikipedia文章或标题。句法分析通常与词汇分析共同使用,目前比较成熟的平台有Berkeley Parser ,Stanford Parser,哈工大LTP平台。它分析句子的句法结构(主谓宾结构)和词汇间的依存关系(并列,从属等)。通过句法分析,可以为语义分析,情感倾向,观点抽取等NLP应用场景打下坚实的基础。
隐性分析方法则是从统计学入手,将文本数字化,即转换为一组向量来表示。通过数学统计的规律来弥补缺失的文本语义,因此看出这种方法不注重可解释性。比较有效的方法有LSA方法和HAL方法,它们的向量维度是难以从人的角度进行解释的。LSA被Deer⁃wester等人于1990年提出,核心思想为若几个词在同一语境下出现,那么我们认为这几个词具有较高的语义相关性。在此基础上分析文档集合,构建一个Term-Document矩阵,再对这个矩阵做奇异值分解。对SVD分解后的矩阵进行降维得到一个原始向量矩阵的一个低秩逼近矩阵。最后使用这个降维后的低阶近似矩阵构建潜在语义空间。HAL从词与词的角度入手,构建目标词汇与语境词汇的共现矩阵。这个矩阵的每个维度代表一个语境词,运用数学统计学方法计算共现次数。
半隐性分析方法定义为可以在一定程度进行解释的算法。这种方法类似隐形分析方法,同样是将文本数字化,用向量表示词语和文本。但是可以在词语和文本中间插入主题的概念,形成文本-主题、主题-词语分布,这时候的向量维度就是概率的分布情况,能够被人理解。这一类的代表算法是LDA(Latent Dirichlet Allocation),算法结果为得到两个概率矩阵,分别对应文本-主题、主题-词语分布。
本论文的分析方法主要涉及到基于LDA主题生成模型的文本聚类分析。下面就国内外LDA的研究进展、LDA改进扩展模型进行阐述。
1.2.2 LDA研究进展
文本聚类是一种将相似度高的文本划分为同一类的方法。该方法不需要事先给文档打上标记,因此是一种无监督的机器学习方法。该模型经历了以下发展过程:
最早提出的VSM模型(向量空间模型,Vector Space Model)将文本表示为一个向量,看作向量空间中的一个点。TF-IDF模型对向量空间模型进行改进。它首先计算每个词的权重,将文本表示为文本中词的权重向量,并将文本看作向量空间中的一个点。权重计算基于以下两点:特征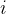 在文档
在文档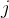 中出现次数越多,权重越高;文档集中含有特征的文档数n越大,权重越低。使用向量表示文本特征的方法会存在维度过高,数据稀疏的问题。同时无法解决同义词.和多义词问题[1]。
中出现次数越多,权重越高;文档集中含有特征的文档数n越大,权重越低。使用向量表示文本特征的方法会存在维度过高,数据稀疏的问题。同时无法解决同义词.和多义词问题[1]。
Deer⁃ wester等人于1990年提出的LSA模型(潜在语义分析,Latent Semantic Analysis)可以部分解决同义词问题。LSA是TF-IDF模型的改良模型,算法复杂度较高。它同样使用向量表示词和文本,但是将词和文本映射到潜在语义空间并挖掘其关系。
1999年Hofmann提出了PLSA模型(Probabilistic Latent Semantic Analysis)对LSA进行了改进。PLSA方法引入概率模型,将文本-主题、主题-词语的关系从概率的角度进行了数学化。
PLSA模型存在的问题是模型会随着文档和词的个数的增加而变得更加庞大。基于PLSA模型,Blei等人2003年提出了LDA模型(Latent Dirichlet Allocation),对PLSA模型进行了贝叶斯改进,把模型的参数看做随机变量,从而引入控制参数[2]。通过计算出参数的值就可以得到文档主题分布情况。模型的参数空间规模实现由人为给出,并不会随着文本集的扩大而变得庞大。因此更适用于大规模文本集。LDA模型最终就是要进行参数估计并求解得到一个近似的后验概率分布去逼近真实的后验概率分布。Blei提出了变分贝叶斯法,随后Griffiths等人提出了Gibbs Sampling算法,该算法计算量大,但采样效果更好[3]。
1.2.3 LDA改进扩展模型
在LDA模型被提出后,针对不同需求,出现了各种围绕LDA模型的扩展模型。
为了解释文本主题之间的关系,Blei等人提出了CTM模型(Correlated Topic Model)。该模型通过计算协方差矩阵来描述两个主题的关系。随后Li等人提出了PAM模型(Pachinko Allocation Model),将关系描述扩展到所有主题之间。
考虑到话题演化的情况,有时候我们需要用一个模型描述主题随时间变化的场景。Blei等人提出DTM模型(动态主题模型,Dynamic Topic Model),该模型通过将LDA模型中的超参数θ和φ设置为不断变化,实现了主题随时间变化的特性。且参数转移满足马尔科夫链的特点。随后Wang等人提出DTM的改进模型cDTM(Continuous Time Dynamic Topic Model),实现了原先离散时间片段的连续化。另外Alsumait等人提出的OLDA(On-line LDA)可以实现增量式的处理动态文本流,即根据当前新增的部分调整模型,同样能获取实时的主题结构。
针对短文本特征稀疏的特点,Liu等人于2014年提出了针对微博热点话题抽取的MA-LDA模型(Multi-attribute Latent Dirichlet Allocation),该模型扩展了时间属性和标签属性,能达到更好的效果。
1.3 课题研究内容
本文详细阐明了针对微信朋友圈传统的统计分析方法的已经不能满足朋友圈关系泛化后的复杂情况,严重限制了有关学者从海量朋友圈数据中获取有用信息的能力。进而引发了本课题的开发。在开发过程中发现没有微信并没有提供微信朋友圈的数据接口,因此本人针对项目需求使用抓包工具,通过模拟手机的操作,实时抓取朋友圈的响应数据,实现了数据的准备工作。
在以上研究背景和准备工作的基础上,我们希望从计算出好友之间相似度的角度简化微信朋友圈的关系网络。基于这个需求,本文基于LDA模型,运用Gibbs抽样算法估计出朋友圈动态-主题分布θ,构建朋友圈动态的主题空间,在主题层面上计算好友的相似度矩阵,进而进行好友聚类[4]。
第2章 主题提取与聚类理论
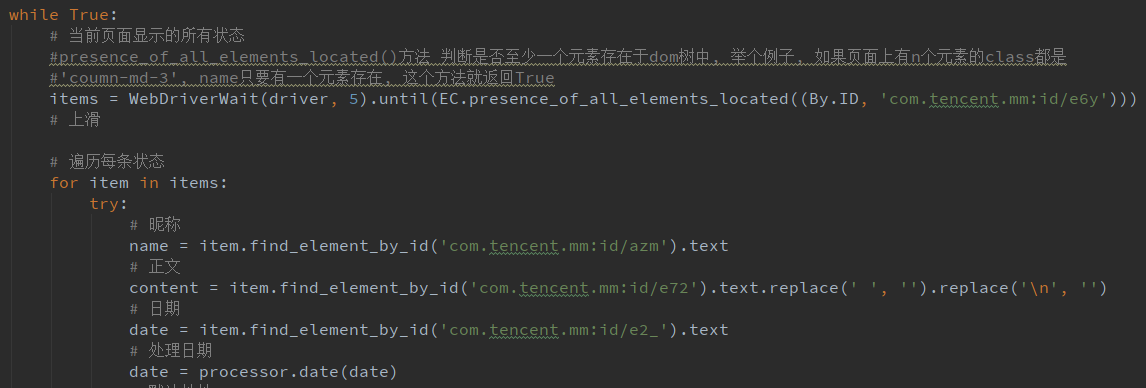
2.1 lda主题模型
隐含狄利克雷分布LDA(Latent Dirichlet Allocation)是一种概率主题模型,在主题模型中占有重要地位,通常用来文本分类。它通过分析文档中的词分布,抽取出文档的主题分布,以多项式分布的形式给出。之后我们可以根据主题分布的结果计算文档相似度,进行主题聚类。
2.1.1 LDA贝叶斯模型
LDA基于贝叶斯模型展开,因此离不开贝叶斯派的统计理论:如果某个随机变量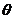 的后验概率
的后验概率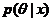 和其先验概率
和其先验概率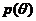 属于同一个分布簇的,那么称 和为共轭分布,同时,也称为似然函数
属于同一个分布簇的,那么称 和为共轭分布,同时,也称为似然函数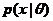 的共轭先验[5]。且先验分布 数据(似然)=后验分布。用数学公式表示为:
的共轭先验[5]。且先验分布 数据(似然)=后验分布。用数学公式表示为:
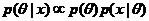 (2.1)
(2.1)
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: