基于thriftrpc的微服务自测平台毕业论文
2020-02-19 18:13:55
摘 要
处于对开发高效性、部署便利性、系统稳定性、系统扩展性等因素的多重考虑,现业内大型互联网公司后端系统大多基于微服务架构。主流的微服务间通信方式有Thrift RPC、gRPC两种方式。目前这种基于RPC、微服务之间相互依赖的架构,使代码开发完成之后的测试变成一件十分繁琐的事情。为提高基Thrift RPC通信的微服务的开发人员的开发效率,本文设计了一个自动化的自测系统。
论文主要研究工作如下:
- 基于特定服务的Thrift IDL文件与一些元信息,自动化的生成加载运行特定服务的Thrift客户端或者服务器。
- 基于用户提供的测试数据,自动化的触发特定服务的特定接口,按预期调用下游服务和进行当前服务的逻辑处理之后,返回结果,供用户验证结果是否符合预期。
- 在测试服务、测试接口、测试数据三个维度,为用户提供数据的维护与管理。
本系统的最终目标是提供一个自动化的自测系统,帮助开发人员在自测阶段搭建测试环境和维护测试用例等,以提高其工作效率。
关键词:微服务;Thrift RPC;beego;自测
Abstract
Considering the development efficiency, deployment convenience, system stability, system scalability and other factors, most of the back-end systems of large Internet companies in the industry are based on micro-service architecture. There are two main modes of inter-service communication: Thrift RPC and gRPC. At present, this architecture based on the interdependence between RPC and micro-services makes testing after code development become a very tedious task. In order to improve the development efficiency of micro-service developers based on Thrift RPC communication, an automatic self-test system is designed in this paper.
In the process of implementing this application, this article has done the following work:
1. Based on Thrift IDL files and some meta-information for specific services, the system automatically generates and loads Thrift clients or servers for specific services.
2. Based on the test data provided by users, specific interfaces of specific services are triggered automatically. After calling downstream services as expected and processing current services logically, the results are returned for users to verify whether the results are in line with expectations.
3. Provide users with data maintenance and management in three dimensions: test service, test interface and test data.
The final goal of this system is to provide an automated self-test system to help developers build test environment and maintain test cases during the test phase, so as to improve their work efficiency.
Key Words:Micro service; Thrift RPC; beego; Self-test
目 录
第1章 绪论 1
1.1 背景 1
1.2 业内现状 1
1.3 目的及意义 2
1.4 预期目标 2
第2章 关键技术分析研究 3
2.1 Thrift RPC 3
2.1.1 Thrift RPC 概述 3
2.1.2 Thrift RPC 软件栈 3
2.2 beego框架 4
2.2.1 beego 框架架构 4
2.2.2 HTTP请求处理流程 5
2.3动态链接机制 6
2.3.1 编译与链接 6
2.3.2 静态链接库与动态链接库 7
2.3.3 动态链接库的使用 7
第3章 系统设计 8
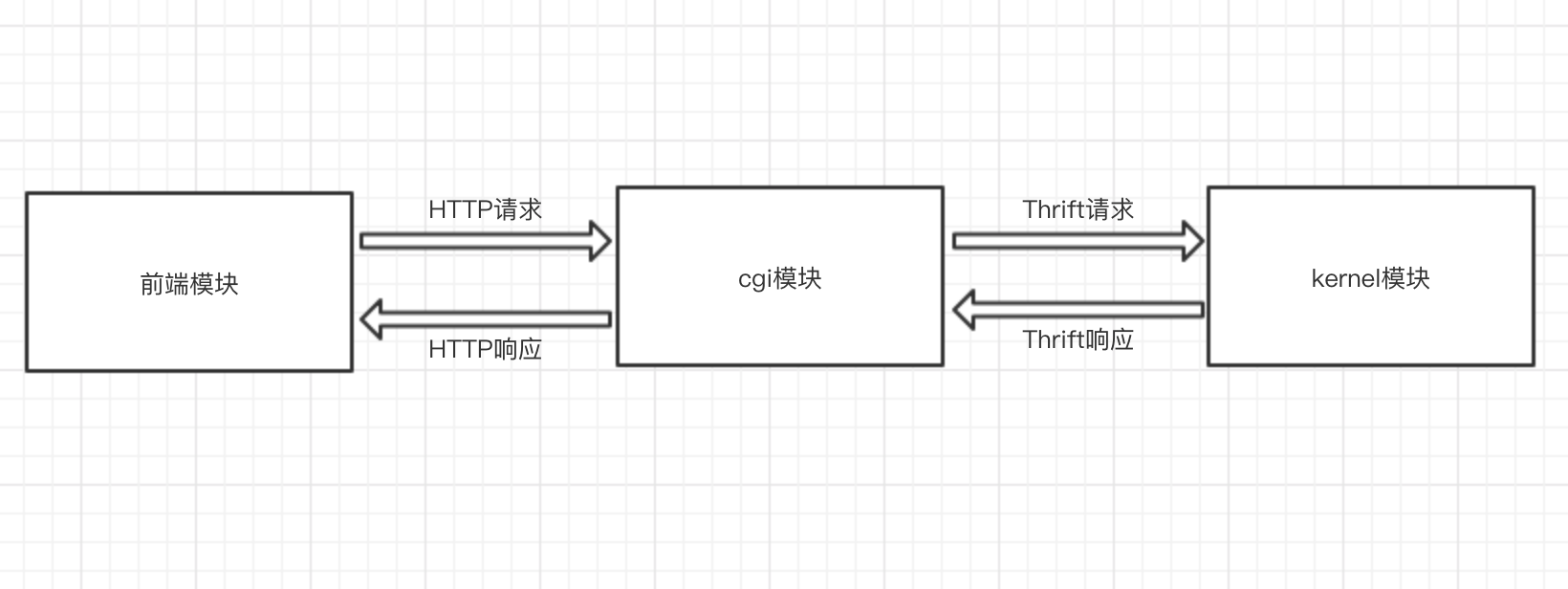
3.1 系统总体架构设计 8
3.2 kernel模块设计 9
3.2.1 GetServiceList接口 9
3.2.2 AddService接口 9
3.2.3 FillData接口 10
3.2.4 RequestTrigger接口 11
3.3 CGI模块设计 11
3.5.1数据库设计 11
3.5.2 CGI模块接口设计 13
3.5.3 CGI架构设计 13
3.4 本章小结 14
第4章 系统关键功能实现 15
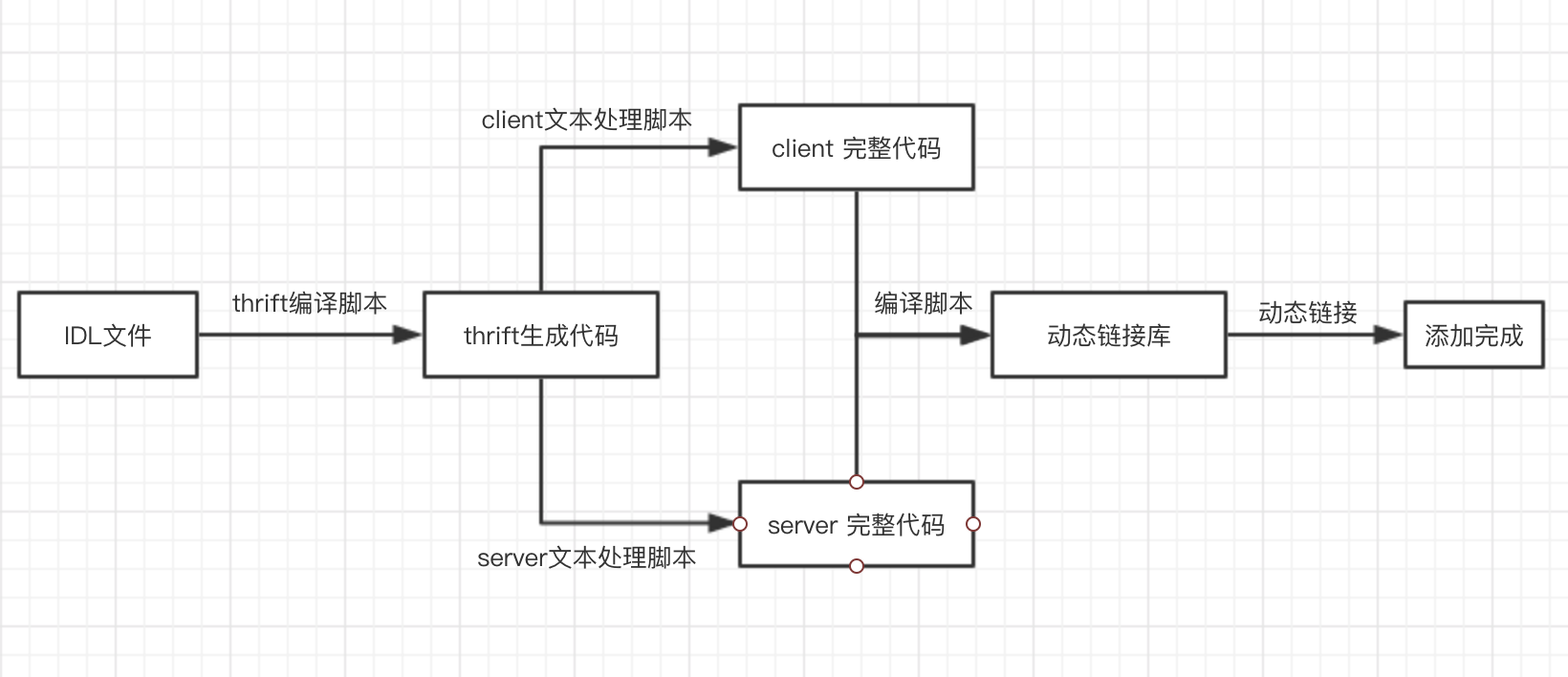
4.1添加服务功能实现 15
4.1.1 何时添加服务 15
4.1.2 添加服务流程概述 15
4.1.3 添加服务要点详述 16
4.2 填充数据功能实现 18
4.2.1 TJSONProtocl协议 18
4.2.2 填充数据流程 18
4.2.3 FillData接口实现逻辑 19
4.3 本章小结 20
第5章 系统测试 21
5.1 kernel模块测试 21
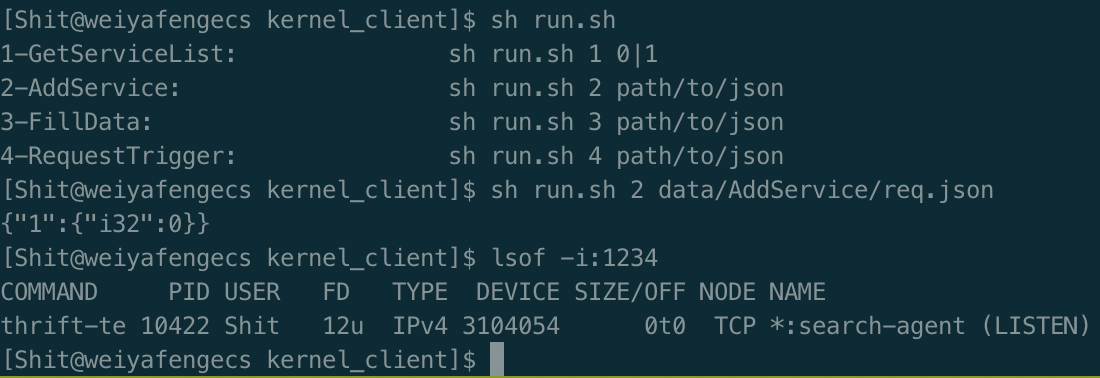
5.1.1 AddService接口 22
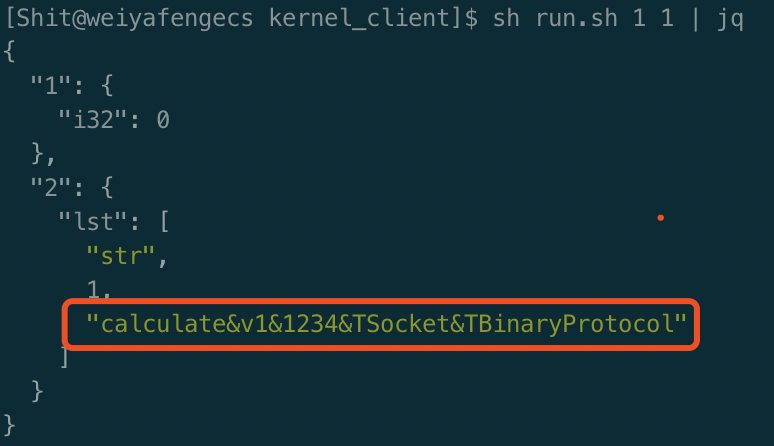
5.1.2 GetServiceList接口 23
5.1.3 FillData接口 24
5.1.4 RequetTrigger接口 25
5.2 CGI模块测试 25
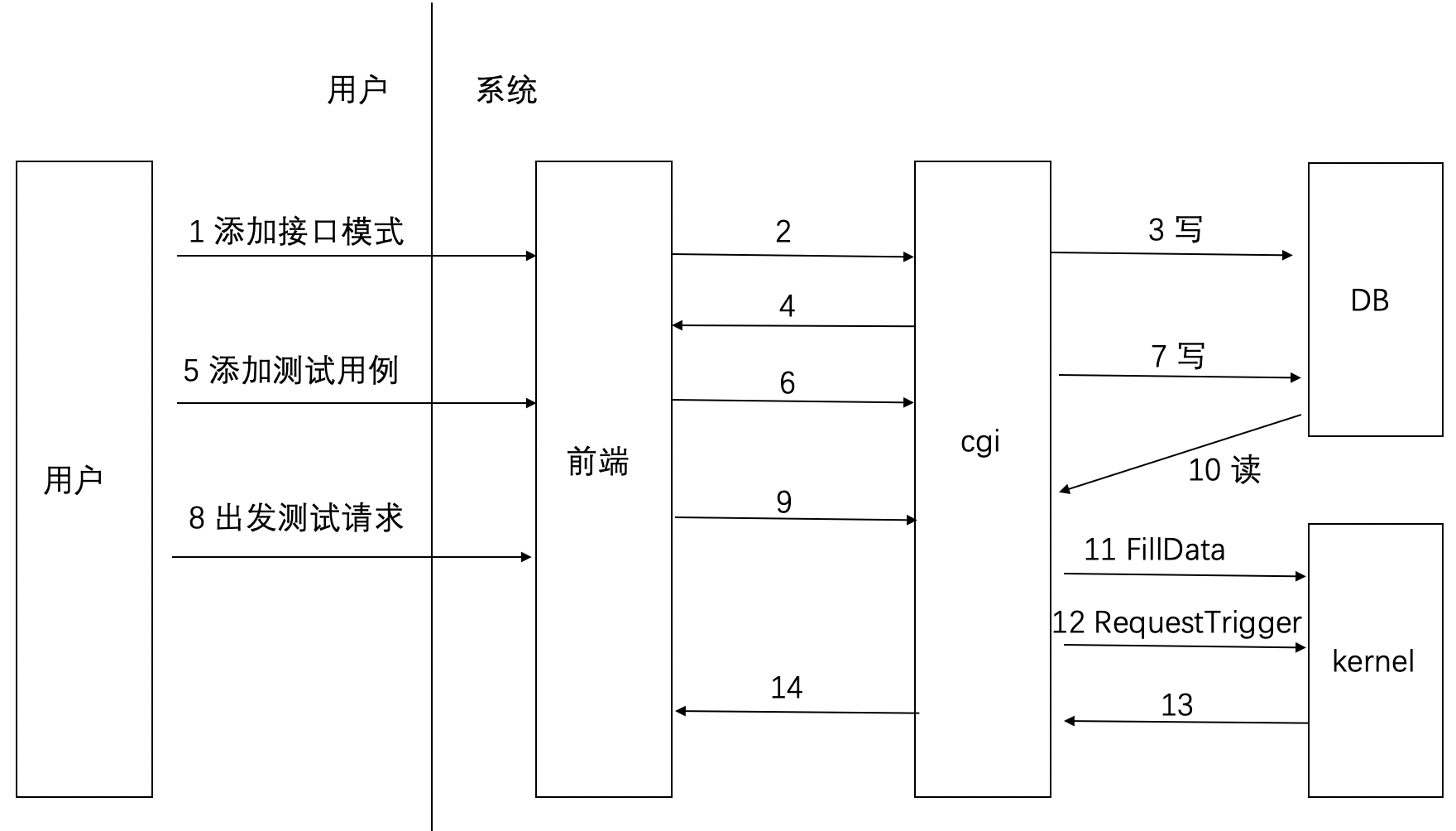
5.2.1 添加服务模式 25
5.2.2 添加接口模式 26
5.2.3 添加测试用例 27
5.2.4 触发测试用例 28
5.3 本章小结 29
第6章 结论 30
6.1总结 30
致谢 2
第1章 绪论
1.1 背景
过去的十年中,互联网对我们的生活产生了翻天覆地的变化,而互联网产品通常有两大特点:需求变化快与用户基数大。在这种业务场景下,现代大型互联网公司后端系统大多采用微服务架构。
微服务是一个软件架构层面的理念。这种架构理念提倡当需要实现某种用户需求时,采取通过多个独立的小体量的服务相互协调的方案,而不是将所有的需求任务使用一个单一大体量的程序完成。其中多个独立的小体量的服务常被称为微服务。微服务与微服务之间常通过RPC机制进行通信。
作为一种主流的微服务通信机制解决方案,Thrift RPC是一种完备的、跨语言的、可伸缩的RPC解决方案[1]。在系统总体架构为微服务架构的前提下,通常,针对某个微服务,常通过实现一个Thrift RPC服务器,向上游提供服务;上游仅需要实现一个针对当前微服务的客户端,实现对当前微服务的调用。相对的,当前微服务也具有一个或多个下游服务,并通过实现对各个下游微服务对应的客户端的方法,调用下游依赖提供的服务。
工业环境下,针对某个需求的开发流程大致是:开发;自测;集成测试;上线。其中,集成测试一般由QA部门进行统一测试,并具有完善的全套的测试环境。自测指开发人员开发完成后,由开发人员进行针对微服务新特性的测试,所以一般并不会对每个开发人员配备完善的测试环境。而在上述通过Thrift RPC实现的微服务架构场景下,各个微服务之间常存在复杂的相互依赖关系,这使得针对特定服务的特定业务场景的测试成为一个业界难题。
1.2 业内现状
当某个开发人员完成对特定的微服务的新特性开发后,通过需要模拟出能够触发当前微服务的新特性的业务场景,测试当前微服务的新特性是否能按预期运行。这一过程在业内没有统一的解决方案,每个开发人员都有个人的解决方案。虽然各个解决方案实现起来有较大差异,但针对这个问题解决方案的大致思路都是一致的,如下所述:
- 实现一个当前微服务对应的Thrift客户端,用以调用当前微服务。
- 针对每一个下游微服务,实现一个下游微服务的Thrift服务器,以供当前微服务调用。
- 针对每一个下游微服务的特定接口,模拟出特定的响应数据。
- 针对当前微服务代测试的某个接口,模拟出特定的请求数据,并触发这个特定接口。
- 针对当前测试用例(包涵当前微服务的请求数据与下游服务的响应数据),结合被测试接口的响应数据与当前微服务的打印日志,判断当前微服务新特性时候按预期运行。
总体来讲,这个解决问题的思路至少有如下两个问题:
- 针对每一个所开发的微服务,开发人员同时也要维护当前微服务所有的上下游服务,这会大大增大开发人员的开发量。
- 当业务场景越来越多时,对于测试用例的管理也会给开发人员带来很大的负担。
1.3 目的及意义
依上文所述,当针对某个微服务的新特性进行测试时,存在上述问题。为解决上述用户需求,本课题设计了本文所述的自测系统。
本系统所要实现的功能,主要是帮助开发人员进行自动化的生成Thrift客户端与服务器,并帮助用户进行测试数据的管理与维护,以达到提高开发人员工作效率的目的。
1.4 预期目标
本课题的预期目标如下:
- 基于特定服务的Thrift IDL文件与一些元信息,自动化的生成加载运行特定服务的Thrift客户端或者服务器
- 基于用户提供的测试数据,自动化的触发特定服务的特定接口,按预期调用下游服务和进行当前服务的逻辑处理之后,返回结果,供用户验证结果是否符合预期
- 在测试服务、测试接口、测试数据三个维度,为用户提供数据的维护与管理。
第2章 关键技术分析研究
本章主要对本系统的实现过程中涉及到的一些核心技术进行分析与研究。
2.1 Thrift RPC
2.1.1 Thrift RPC 概述
Thrift RPC是一种开源的RPC框架,其包含两部分。一是用以支持Thrift底层通信协议的库文件,二是Thrift编译器。其主要特定如下:
- 开发速度快:开发人员仅需根据微服务间通信协议编写IDL文件。Thrift编译器利用IDL文件即可自动生成服务端框架代码与客户端桩代码。这些代码结合Thrift提供的库文件,即可实现RPC机制。整个过程接口编解码、消息传输、服务器多线程模型等基础工作均有Thrift实现,用户仅需实现业务代码即可。
- 接口维护简单高效:使用Thrift协议规定的IDL文件格式,即可作为微服务之间通信的接口使用文档。可以直接根据IDL文件生成接口代码,使得代码与文档可以保持一致性。而且IDL文件本身也提供了良好的版本控制方案。
- 学习成本低:因为其来自Google Protocol Buffers开发团队,所以其IDL文件风格类似Google Protocol Buffers[7],且更加易读易懂;特别是RPC服务接口的风格就像写一个一般的面向对象的Class一样简单[6]。
2.1.2 Thrift RPC 软件栈
Thrift RPC协议本身定义的软件栈提供了清晰的分层,下层协议向上层协议提供服务,各个协议层可以松散的耦合。Thrift 软件栈如下图2.1所示。
具体来讲,Thrift软件栈有如下层[12]:
- Transport: 传输层,定义数据传输方式,即定义获取字节流的方式,可以通过文件获取字节流,通过内存获取字节流,通过网络获取字节流等。
- protocol: 协议层, 定义数据传输格式,即定义字节流与Thrift所提供标准数据结构的编解码规则,可以为JSON、XML或二进制格式等。
- Processor: 处理器层,此协议层由Thrift编译器根据用户定义的IDL文件生成,对通信协议的输入输出进行了封装,并托付给用户实现的处理器进行处理。
- Server: 服务层, 整合上述组件, 提供网络模型(单线程/多线程/事件驱动), 最终形成真正的服务。
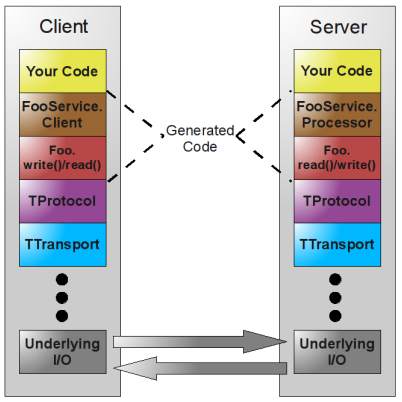
图2.1 Thrift RPC软件栈
2.2 beego框架
beego是一个基于Go语言的HTTP框架,它为后端服务在处理HTTP请求时常见的问题,提供了较为通用的解决方案[14]。
2.2.1 beego 框架架构
beego 是基于八大独立的模块构建的,是一个高度解耦的框架,如图2.2所示。
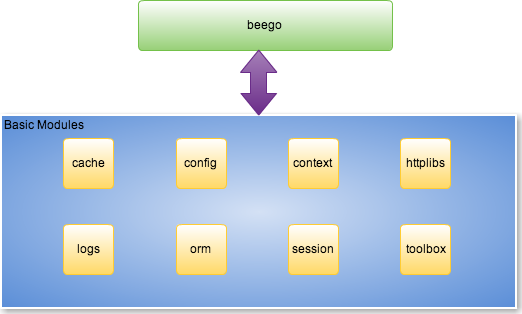
图2.2 beego框架架构
其中,每一个模块都独立负责解决Web开发中某一方面常见的问题。在本课设的设计中,用到的beego模块主要有如下几个:
- session模块:负责进行会话管理,即维护用户的登录状态。
- config模块:负责维护系统所需要的配置信息。
- logs模块:负责系统的日志系统。
- orm模块:提供了go语言中的Struct 与数据库中表的映射,基于这种映射封装了一些对于数据库的操作。
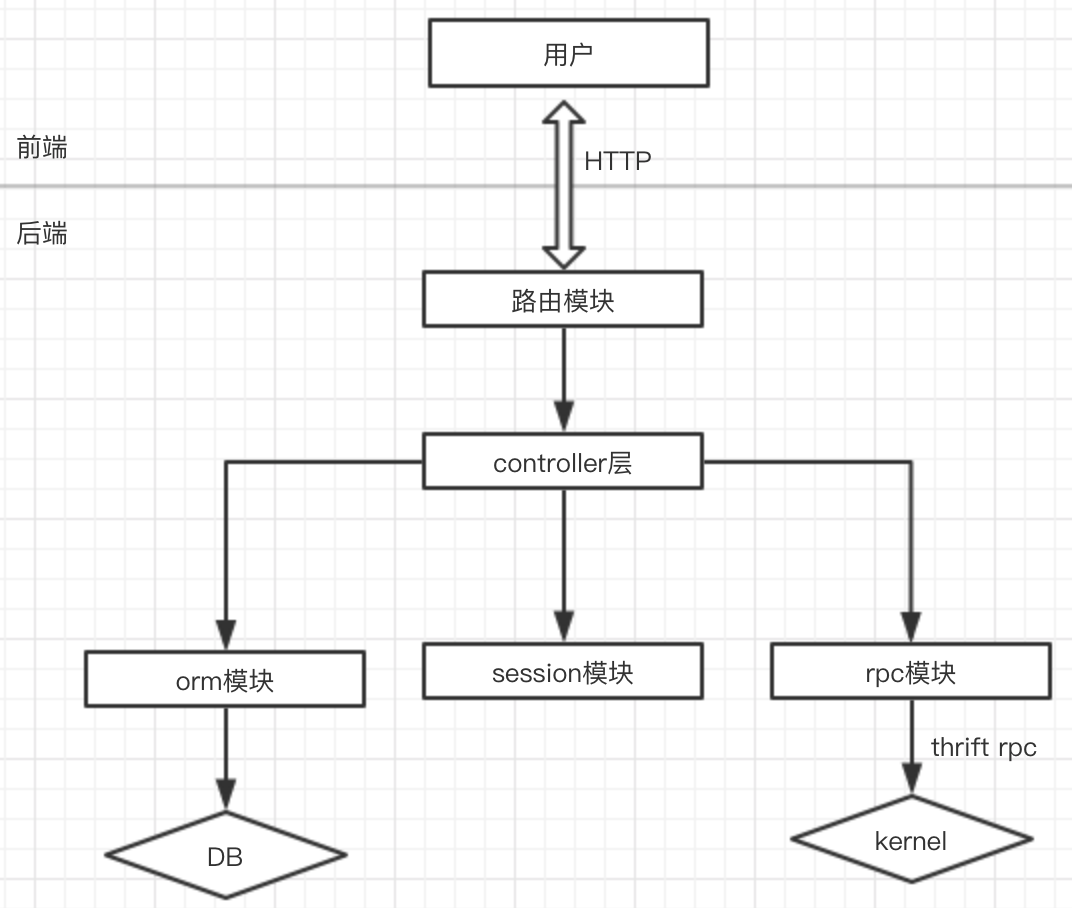
2.2.2 HTTP请求处理流程
beego作为一个成熟的Web框架,从请求处理的角度看,采用了典型了MVC架构,具体来讲,beego框架处理一个请求的流程如下图2.3所示:
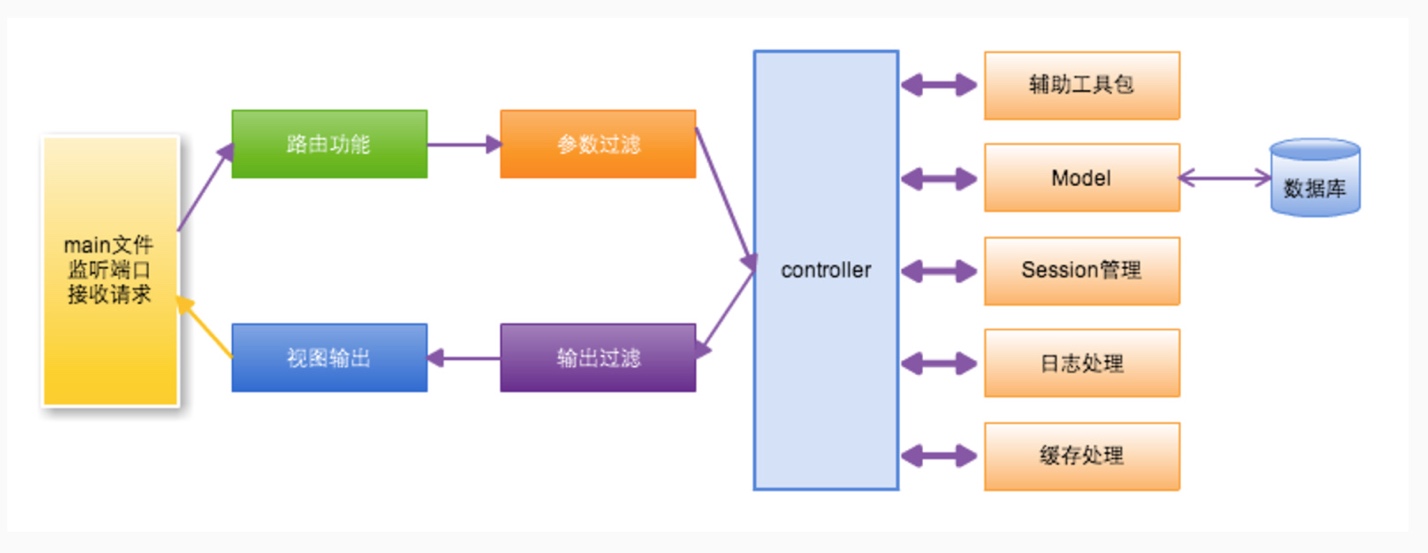
图2.3 beego请求处理流程
如上图所述,当beego框架接收到一个HTTP请求时,会根据路由规则,利用HTTP请求行中的URL结合一些用户添加的参数过滤规则,降不同的请求路由至不同的controller实现类,再根据HTTP请求的请求方法将请求映射到具体实现类的某个特定方法上。
controller 层接收到请求时,负责处理主要的业务逻辑,若业务逻辑涉及到对于数据库的操作,则会把对于数据的操作单独封装为model模块,这是为了将数据操作与业务处理分离,实现系统更好的模块化。在controller 层,也会调用其他的一些模块,类似于调用Session模块用于会话管理,调用日志模块用户处理日志等。
在controller层处理完业务逻辑后,一般会输出一些处理结果给前端展示,beego的视图层根据controller层的输出结果与用户定义的一些输出过滤规则,结合一些事先定义的视图模板,会展现给用户最终的页面效果。
2.3动态链接机制
此处的动态链接机制,指的是Linux系统下,C/C 程序的动态链接机制。在本系统的实现中,最核心模块的关键功能,依赖于对这一技术的灵活应用。因此,下文对动态链接机制,做概要性的叙述。
2.3.1 编译与链接
在Linux系统下,编译器将一个C/C 程序,从源代码转换为一个可执行程序的过程,总体上分为下图所示四个过程。
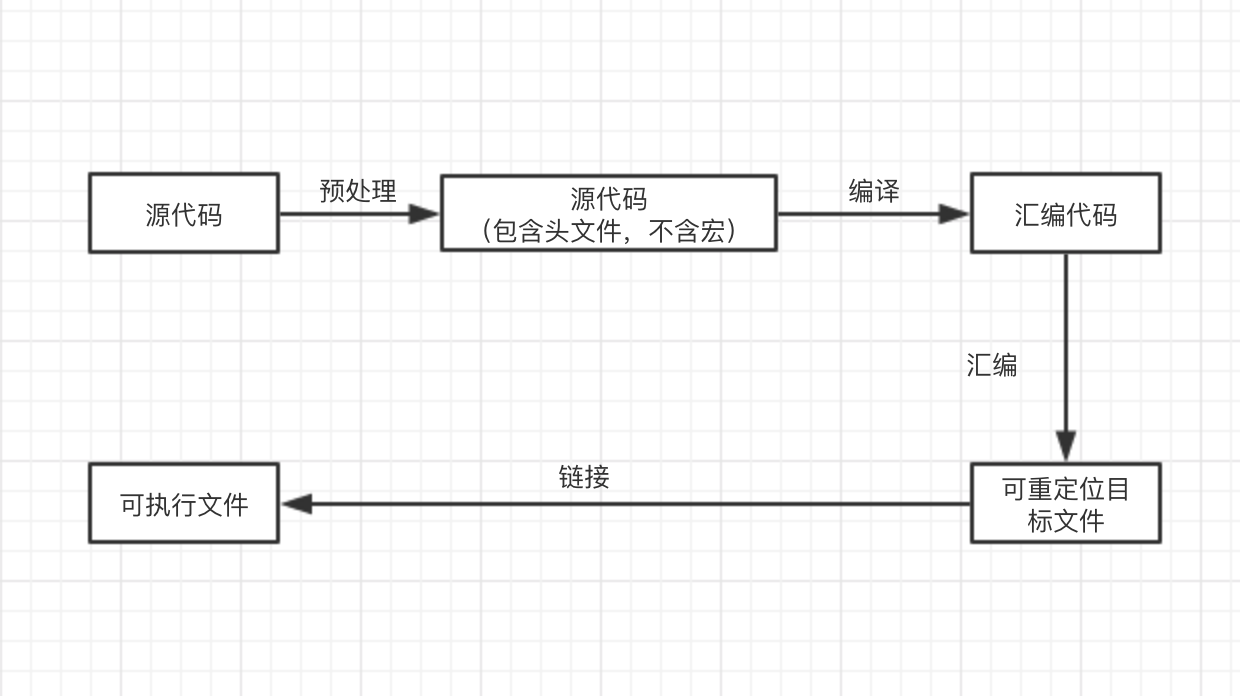 图2.4 C/C 程序编译流程
图2.4 C/C 程序编译流程
在上述四个过程中,前三个过程常被宽泛的统称为编译。编译过程是编译器针对单个源代码文件进行的,负责将单个以文本形式存储的源代码文件,翻译成以二进制形式存储的可重定位目标文件。每个可重定位目标文件,本质上是原程序对应最终可执行文件的部分指令集合,再加上一些用以描述这些指令的段表、符号表等信息构成的。
链接过程是编译器针对多个可重定位目标文件进行的,实质是根据每个可重定位目标文件中的符号表信息,将多个可重定位目标文件链接成一个可执行文件的过程[2]。因此,理解链接过程的核心,是理解可重定位目标文件的符号表信息。
符号,即是对函数或者全局变量的引用。针对链接过程,单个可重定位目标文件的符号表可以理解为由两部分组成,一是当前文件对外提供的符号集合,二是当前文件依赖的外部符号集合。链接过程,即可理解为链接器解析所有的文件,为每个文件的每个依赖的外部符号,在其他文件所对外提供的符号集合中,寻找到一个正确的映射。当程序被链接成单个可执行文件时,每个符号在程序中的相对地址都已确定,再更新可执行文件中每个符号引用为相对地址即可。至此,链接结束,生成最终可执行文件。
2.3.2 静态链接库与动态链接库
静态链接库与动态链接库,是代码复用的两种方式。其本质是库开发者开发完源代码后,将源代码编译成许多可重定位目标文件,再将这些文件打包成单个文件的产物[9]。它们的区别在于将库文件链接进可执行文件的过程是不同的。
静态链接库在链接阶段,把所有的库文件中的二进制指令全部链接进可执行文件中。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: