基于编码的分布式存储系统研究毕业论文
2020-02-17 23:04:37
摘 要
大数据时代,互联网的发展为人们带来了方便的同时,也带来了海量的数据。如何大批量且安全地存储这些数据是人们当前所需要解决的问题,因而分布式存储应运而生。分布式存储采用大量廉价的硬盘构建存储量大,可靠性高,拓展性强的存储系统,为了提升存储数据的安全性和可靠性,通常对数据进行编码,增加冗余来提高数据存储的可靠性。常规的编码方案有副本技术,纠删编码,局部修复编码,再生编码。副本技术和纠删编码是时下流行且方便的编码方案,究其原因是实现的方法较为简易,但是随之而来的存储开销和修复开销太大使得人们不得不寻找更合适的编码方案来降低存储开销和修复开销,再生编码和局部修复编码随之诞生。再生编码作为一种纠删编码结合网络编码理论而诞生的新兴的网络编码技术,在存储开销和修复开销方面的优化使其成为了人们所青睐的编码方案。然而同样的再生编码也有他的缺陷,再生编码计算复杂度较高导致修复效率的降低,以及网络环境的限制,再生码不一定能够在最优参数下对数据进行编码。本文针对当前现状,主要研究内容是:比较当前主流编码方案(副本技术,局部修复编码,纠删编码,再生编码),依据网络环境的不同选取合适的编码方案,这样达到对网络资源利用的最大化。
关键词:分布式存储;再生编码;纠删编码;存储开销;修复开销
Abstract
In the era of big data,the development of the Internet has brought convenience to people and brought a huge amount of data. How to store these data in large quantities and safely is a problem that people need to solve nowadays,and distributed storage comes into being. Distributed storage uses a large number of inexpensive hard disks to build storage systems with large storage capacity,high reliability,and strong scalability. In order to improve the security and reliability of stored data,data is usually encoded to increase redundancy to improve data storage reliability. Conventional coding schemes include copy technology,erasure coding,local repair coding,and reproduction coding. Copy technology and erasure coding are popular and convenient coding schemes. The reason is that the implementation method is simple,but the storage overhead and repair overhead are too large,so people have to find a more suitable coding scheme to reduce Storage overhead and repair overhead,regenerative encoding and partial repair encoding were born. The emerging network coding technology,which was born as a type of erasure coding combined with network coding theory is becoming a popular coding scheme. However,the same regenerative coding has its drawbacks. The high computational complexity of regenerative coding results in a reduction in repair efficiency,and the limited regenerative code of the network environment may not be able to encode data under optimal parameters. In view of the current status quo,the main research contents are: compare the current mainstream coding schemes (copy technology,partial repair coding,erasure coding,regenerative coding),and select the appropriate coding scheme according to the different network environments,so as to achieve the maximum utilization of network resources.
Keywords: distributed storage;regenerating codes;erasure codes;storage overhead;repair overhead
目录
第一章 绪论 1
1.1研究目的及意义 1
1.2 相关技术研究现状分析 1
1.3主要研究内容及结构安排 2
第二章 纠删码的基础理论 4
2.1引言 4
2.2纠删编码的技术原理和分类 4
2.3 RS码编码重构原理 4
2.4 RS码的生成矩阵 7
2.4.1 范德蒙德矩阵 7
2.4.2 柯西矩阵 7
2.5 性能分析 8
第三章 再生码的基础理论 9
3.1 引言 9
3.2 再生码概述和信息流图 9
3.2.1再生码分类 9
3.2.2 信息流图 9
3.2.3 最小存储和最小修复带宽折中曲线 11
3.3性能分析 13
第四章 副本技术和局部修复码 14
4.1 引言 14
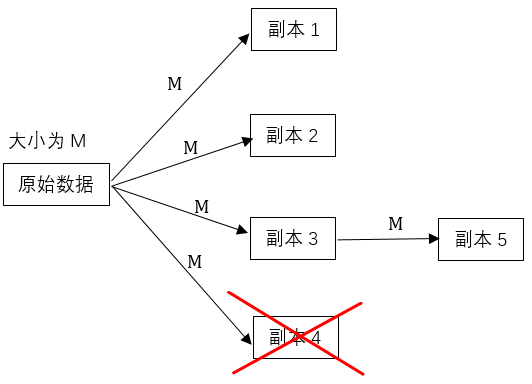
4.2 副本技术 14
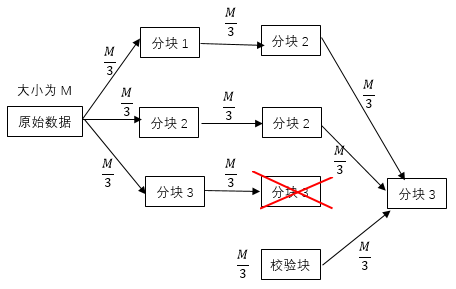
4.3 局部修复码 15
4.3.1最小距离 15
4.3.2 最小距离上界函数 15
4.4 性能分析 16
第五章 基于Matlab的仿真测试 18
5.1 Matlab简介 18
5.2 不同参数下的编码比较 18
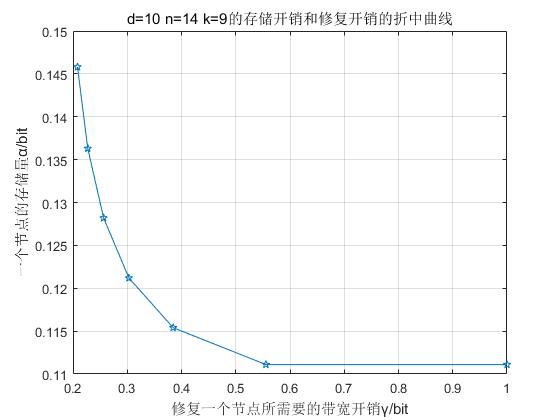
5.2.1 n=14,k=9的编码折中曲线 18
5.2.2 n=14,d=9编码折中曲线 19
5.2.3 d=9,k=9编码折中曲线 20
5.3 总结 21
参考文献 23
致谢 24
第一章 绪论
1.1研究目的及意义
随着分布式存储系统的发展,数据流量已经到达PB级[1],人们对分布式存储系统的存储量和安全性提出了新的要求,对分布式编码的研究也逐渐深入,如何选取适宜的编码方案成了网络公司首先需要考虑的问题。目前副本技术在分布式存储系统中被普遍的使用,例如典型的GFS和HDFS[2]。纠删编码则在实际应用中被许多云存储系统采用,像facebook的云存储系统中就采用了HDFS-RAID纠删编码,HDFS-RAID方案中使用RS编码替代了三副本技术。而与副本技术和纠删编码这两种相对成熟的编码方案相比,再生编码的研究在这几年也在逐渐发展,人们既希望降低存储开销和修复开销又不希望编码和修复过程太过复杂导致不够实用[3]。
分布式存储系统编码方案的优缺点的体现主要有以下三点:
- 存储开销。存储同样大小的信息,不同的编码方案所需要的存储开销是不同的。通常情况下副本技术的存储开销是现存编码方案中是最大的。存储开销是分布式存储中首先要考虑的,因为实际应用中由于成本、资源限制无法像理论研究中那样提供足够的资源进行数据的存储。
- 修复开销。因为分布式存储系统本身原因或者外部入侵者的攻击,数据损坏是经常发生的。与存储开销相似,修复开销同样受到成本,资源的限制,降低修复开销是优化编码方案的一个重要方向。在修复方面,除了修复开销,修复复杂度也是相当关键的,假使一个分布式系统的修复复杂度过高,降低了修复效率,这样的一个分布式系统是不实用的。
- 可靠性问题。在分布式存储系统中,假使经常发生数据损坏或者数据损坏,将导致生活中用户的重大损坏,而提高编码方案的可靠性能够提高整体系统的可靠性,从而有效地避免这些因可靠性过低带来的经济损坏。
本文的研究目的旨在比较主流编码方案(副本技术,纠删编码方案,再生码,局部修复码)的存储开销和修复开销,针对不同的网络特性选取合适的编码方案,实现存储需求和成本之间折中。
1.2 相关技术研究现状分析
大数据时代带来的海量数据,便捷了人们的生活也带来了新的困扰,如何安全的存储海量数据成了互联网公司所需要解决的问题。分布式存储系统利用大量硬盘阵列来进行数据存储,并在这过程中进行编码保证数据的安全性使得即使存储节点失效,也能够经过存活节点进行重构原始数据[4]。目前许多互联网巨头的云存储系统大多使用的三副本或者纠删码来对数据进行编码,例如Google公司的GFS系统和Apache基金会的HDFS系统使用的就是三副本技术,除此之外微软公司使用的是基于异或运算的局部修复码的容错机制。不同的编码方案有着不同的优点,而随着互联网的发展,副本技术和纠删编码逐渐展现了弊端,存储开销大,修复开销大,可靠性低。人们提出新的编码方案——再生编码。再生码在纠删码的基础结合了网络编码思想[5](信息流图),在修复过程中经过从帮助节点下载数据进行数据修复[6]。再生编码作为新兴的编码方案,一经提出就受到学界普遍的关注。随着人们深入研究,再生编码可靠性高,存储开销小,修复开销小的优势被逐渐挖掘出来。最小存储再生码[7],准周期再生码[8],二进制再生码[9],投影再生码[10]接连被提出。但是即使再生码在诸多方面上有着优势,在实际应用中也要考虑编码难度,再生码由于参与编解码的节点数较多导致了计算复杂度较大,这对分布式系统的计算效率提出了一定的要求。由于副本技术和纠删编码易于实现,修复开销虽然大但是修复过程简单,使得这两种编码方案依旧作为主流的容错方案。除此之外,局部修复码在单个节点损坏时有效地降低了修复开销,在多节点损坏时其优势不在,且不满足MDS特性。因此在实际网络中,要依据网络的特性和成本因素选取适当的编码方案。
1.3主要研究内容及结构安排
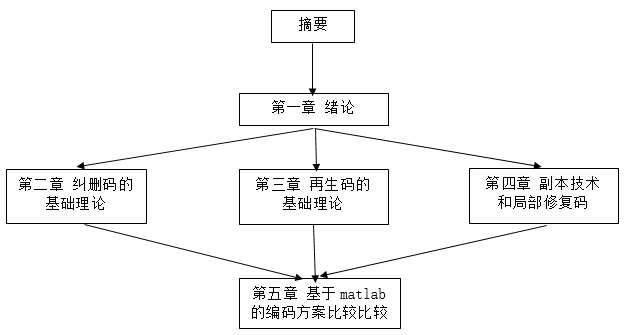 本文针对分布式存储系统的四种编码方案,主要在存储开销和修复开销问题上进行了比较。如图1.1,分为这几个部分:
本文针对分布式存储系统的四种编码方案,主要在存储开销和修复开销问题上进行了比较。如图1.1,分为这几个部分:
图1.1 论文的主要内容
- 绪论。介绍了互联网大数据的发展对分布式存储系统的影响以及目前主流分布式系统中使用的编码方案。分析了编码方案比较中所需要重视的几个参数,最后介绍了本文的研究内容和本文的结构。
- 纠删码的基础理论。介绍了纠删码的技术知识和分类,着重阐述了RS码的起源和编码解码过程,最后对RS码的存储开销和修复开销进行 了分析。
- 再生码的基础理论。介绍了信息流图的基础知识以及最大流最小割定理,在再生码容量公式的推导过程中分析了MSR和MBR,在此基础上画出了存储开销和修复开销折中曲线,对再生码的存储开销和修复开销进行了剖析。
- 副本技术和局部修复码。介绍了副本技术的分类和优缺点,对副本技术的存储开销和修复开销分析总结。此外还介绍了一种局部修复码的编码方案,在与纠删码比较后分析了在存储开销和修复开销上有何优势。
- 基于Matlab的编码方案比较。借助Matlab,将纠删码和再生码的存储开销和修复开销放在一张图中,结合对副本技术和局部修复码的分析,总结了四种编码方案的存储开销和修复开销。
第二章 纠删码的基础理论
2.1引言
由于副本技术的系统开销非常大,纠删编码应运而生,因为其系统开销较低和可靠性较高,在实际应用中,纠删编码的编码和重构过程也较为成熟,经过不断的发展和优化,纠删编码被普遍应用于大规模云存储系统中。本章主要介绍纠删编码的分类和技术原理,主流纠删编码的编码,解码和修复过程,纠删编码的存储参数分析。
2.2纠删编码的技术原理和分类
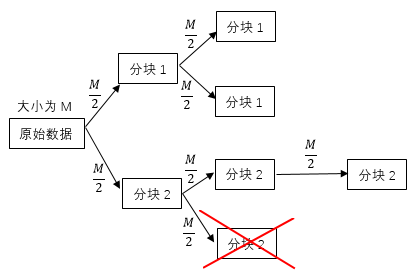
纠删编码的技术原理[11]:首先将要存储的文件D分割成k个信息块,对其编码生成m个校验块,将这n(k m)个数据块分布到存储系统中不同的节点中,实现冗余的添加,只需要从这些存放数据块的节点中获取k’(k’≥k)个数据块就可以重构出原始文件D。假使从上述节点中连接任意获取k个数据节点即可重构出原始文件D,那么这种纠删码满足最大距离可分(Maximum Distance Separable,MDS)特性,可靠性和冗余度的权衡使最优的。
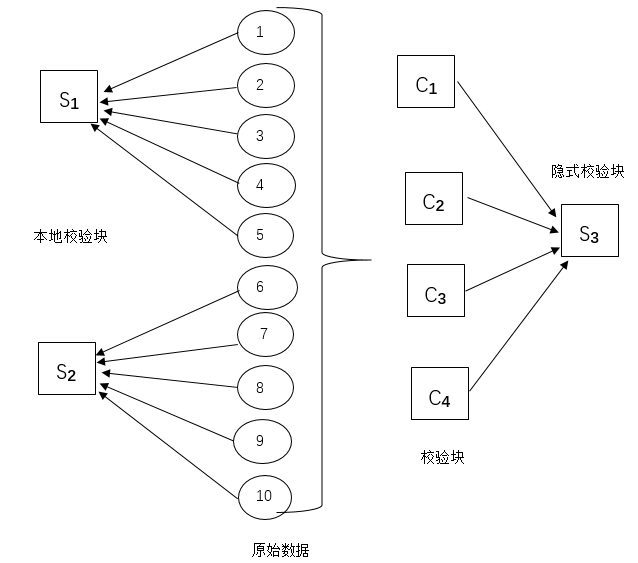
纠删编码的分类:依据MDS特性,纠删编码可以分为MDS码和非MDS码。他们之间的区别就在于MDS特性上,非MDS码的重构中并非所有的数据块组合都能重构出原始数据块,而MDS码则是任意k个数据块都可以重构出原始数据块。典型的MDS码有RS码,典型的非MDS码有局部修复码(Locally Repairable Codes,LRC)。纠删编码的分类如图2.1所示
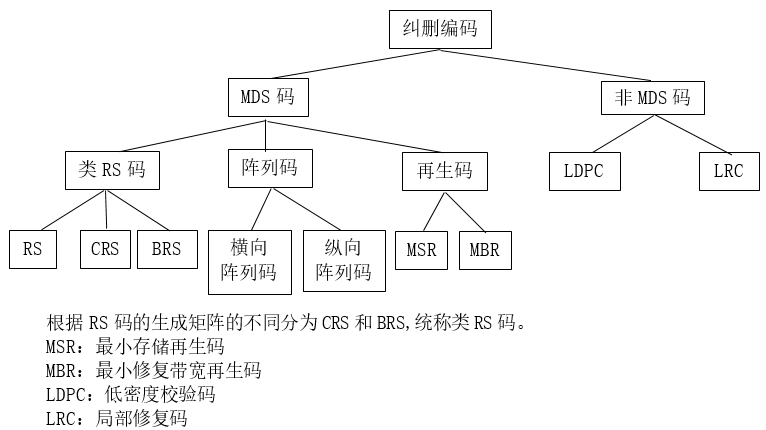 2.3 RS码编码重构原理
2.3 RS码编码重构原理
图2.1 纠删编码的分类
纠删编码的编码和重构示意图如图2.2所示
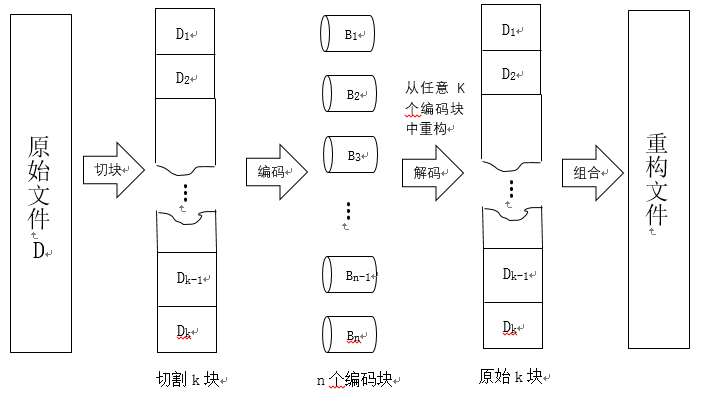
图2.2 纠删编码的编码和重构示意图
RS(Reed-solomon)编码,起源于1960年,是第一种满足MDS特性的纠删编码方法,经过长久的发展已经有了完善的理论和实践基础。RS是一种基于伽罗瓦域GF(2w)上的编码方式。RS码通常分为两类:一类是范德蒙德RS编码(Vandermonde RS codes),另一类是柯西RS编码(Cauchy RS codes)。
(n,k)RS编码中存在一个m行k列的矩阵G(m=n-k),用于将原始数据编码得到校验数据块,这个矩阵G称为RS码的生成矩阵。RS编码实际上就是利用生成矩阵与数据列向量的乘积来计算得到信息列向量的,其重构过程也是利用未出错信息所对应的生成矩阵的逆矩阵与未出错的信息列向量相乘来恢复原始数据。
RS码编码的原理如图2.3所示。
图2.4表示在RS码解码和修复过程中,假设D3,D5,C3块失效,可以选择任意k=5个存活节点,依据选择的存活节点,获得对应的残留矩阵G’,在图2.4的下部分中,计算出残留矩阵G‘的逆矩阵G’-1,G’-1与存活节点的乘积结果就是编码前的原始数据,原始数据与生成矩阵相乘的结果就是编码后的数据块,这样RS码的修复和重构就完成了。
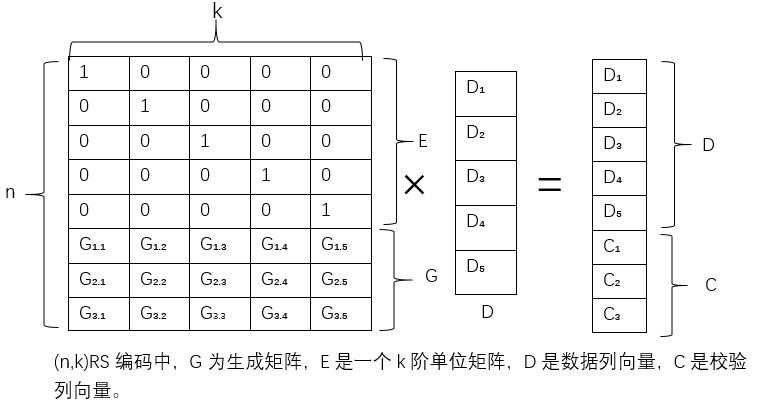
图2.3 (n,k)RS编码的生成矩阵和编码过程
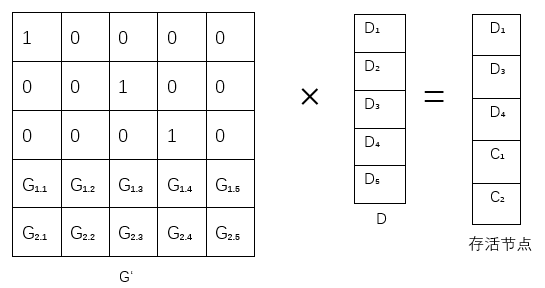
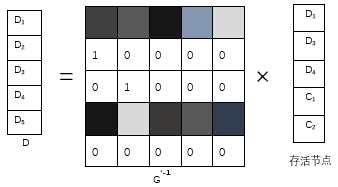
图2.4 (n,k)RS码的解码过程
2.4 RS码的生成矩阵
RS码的生成矩阵大致分为两种:范德蒙德矩阵和柯西矩阵。由范德蒙德矩阵得到RS码称为范德蒙德RS编码(Vandermonde RS codes),由柯西矩阵得到的RS码称为柯西RS编码(Cathy RS codes)。
2.4.1 范德蒙德矩阵
范德蒙德矩阵的形式为
矩阵中第i行,第i列的元素可以表示为
对于范德蒙德矩阵,每一行的底数都相同,每一列的底数都以自然数顺序依次加一;每一列的指数都相同,每一行的指数都以自然数顺序依次加一。
范德蒙德矩阵的性质:
- 范德蒙德矩阵的转置矩阵也是范德蒙德矩阵。
- 范德蒙的行列式可以表示为公式(2-1)所示:
(2-1)
- 依据性质(2)当所有的都互不相等,则范德蒙德矩阵的行列式不为0。
2.4.2 柯西矩阵
柯西矩阵的形式为
矩阵中第i行,第i列的元素可以表示为。
柯西矩阵的性质:
- 柯西矩阵的转置矩阵也是柯西矩阵。
- 柯西矩阵的行列式可以表示为公式(2-2)所示:
(2-2)
- 依据性质(2)假使所有的都互不相等,且所有的都互不相等,则柯西行列式不为0。假使不存在和互为相反数的情况,则柯西矩阵可逆。
2.5 性能分析
对一个(n,k)纠删码,假设原始数据D大小为M,被分块为k个信息块,编码后生成m个校验快,一共有n(k m)个数据块。则存储开销如公式(2-3)所示:
(2-3)
当一个节点损坏或损坏时,利用任意k个其他存活节点重构出原始数据D,则修复开销如公式(2-4)所示:
(2-4)
第三章 再生码的基础理论
3.1 引言
随着互联网的蓬勃发展,数据呈现爆炸式增长的趋势,纠删编码的修复开销过大导致了分布式存储的成本过高。互联网公司不得不寻找修复开销更优良的编码方式。人们将纠删编码结合网络编码理论提出了再生码。
3.2 再生码概述和信息流图
3.2.1再生码分类
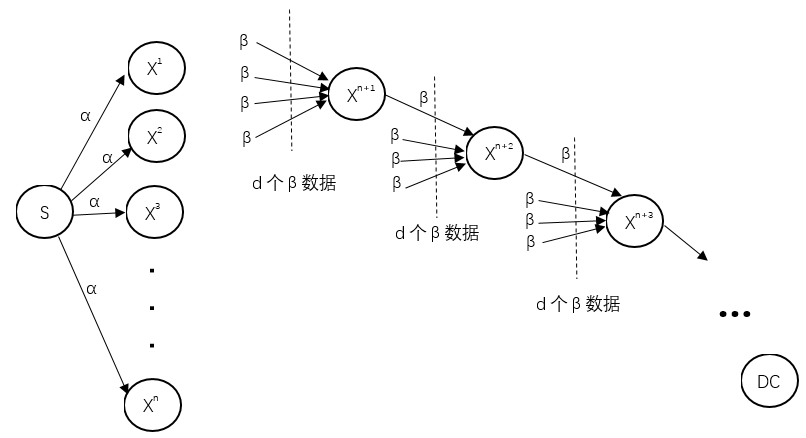
在再生码的修复过程[12]中,需要从剩下的存储节点里面连接d个节点分别下载β大小的数据形成新节点,新节点替换损坏的节点完成对再生码的修复。修复后的新节点中的数据不一定要求与损坏节点一样只需要修复后的分布式存储系统满足MDS即可。依据修复要求的不同,再生码可以分为三类。
- 精确修复再生码:修复后的新节点中的数据与损坏的数据一样。
- 功能修复再生码:修复后的新节点的数据可以跟损坏的数据不同,只需要修复后的分布式系统满足MDS特性。
- 系统局部精确修复再生码:作为一种处于精确修复和功能修复之间的修复方式,对系统节点进行精确修复,保证与损坏的数据一样,而对于非系统节点进行功能性修复,只需要修复后的信息满足MDS特性。
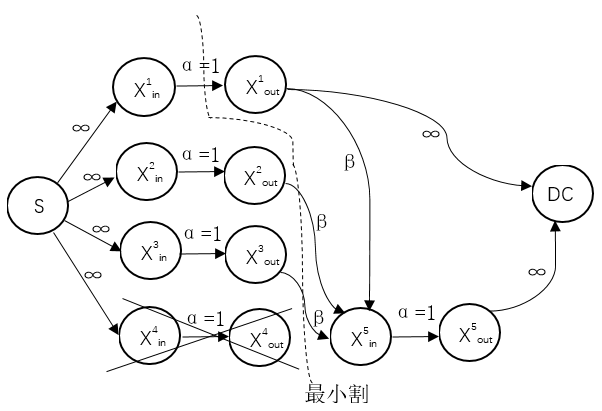
3.2.2 信息流图
信息流图是分布式存储系统中重要表示图形,通常由顶点和有向边组成。如图3.1所示,信源S是信息流图中的发点,数据接收器是信息流图中的收点,其他顶点为中间顶点,连接各个顶点的是一条条有向边,每一条有向边都有自己的流量即为权值。
信息流图中的割定义为一个切线,切线经过有向边将所有顶点划分为两个独立的分别包含信源和数据收集器的子集,当信息从信源出发无法经过中间顶点进入数据收集器。有向边的权值和最小的割即为最小割。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: