生物文献检索与推荐系统毕业论文
2021-03-14 21:40:06
摘 要
对生物学家而言,通过传统搜索引擎获取生物文献极其困难,需要花费大量的时间精力来过滤冗余信息,极大地降低了科学研究的效率,阻碍了生物科学的发展以及人类的进步。在此背景下,本文设计并实现了生物文献检索与推荐系统。本文的主要工作如下:
1.基于theme特征提取算法,实现了从关键词到MeSH主题词的映射算法;
2.采用一致性评估算法,对theme特征提取算法进行了评估;
3.实现了基于相同作者的推荐算法;
4.实现了基于内容的推荐算法;
5.设计并实现了生物文献检索与推荐系统。
实验表明,本文采用的theme特征提取算法明显优于信息增益特征提取算法。同时,经过测试,本文实现的生物文献检索与推荐系统和传统搜索引擎相比,具有明显的优势。
本文的特色在于,采用检索与推荐相结合的方式,极大地提高了生物学家获取文献的效率。
关键词:生物文献,MeSH,特征提取算法,一致性评估算法,推荐算法
Abstract
For biologists, it is extremely difficult to obtain latest biological literature through the traditional search engine. Because of the great demand of time and effort to filter the redundant information, the traditional search methods greatly reduce the efficiency of scientific research, the development of biological science and the progress of human beings. In this paper, we design and implement a biological literature retrieval and recommendation system. The main work of this paper is as follows:
1. Map the keywords to MeSH words by using a theme based feature extraction algorithm;
2. Evaluate the theme feature extraction algorithm by using the consistency evaluation algorithm;
3. Realize a recommendation algorithm based on the same author;
4. Realize a content based recommendation algorithm;
5. Design and implement the biological literature retrieval and recommendation system.
The experimental results show that the proposed theme based feature extraction algorithm outperforms the information gain algorithm (see Table 2.1). Meanwhile, the result shows that the biological literature retrieval and recommendation system in this paper has obvious advantages over the traditional search engine (see Table 3.1).
The innovation point of this paper is that the combination of retrieval and recommendation has greatly improved the efficiency of biologists' access to literature.
Keyword: biological literature, MeSH, feature extraction, coherent measure, recommend algorithm
目 录
第1章 绪论 1
1.1 研究背景及意义 1
1.2 国内外研究现状 1
1.2.1 文献检索国内外研究现状 1
1.2.2 推荐国内外研究现状 3
1.3 论文主要工作 4
1.4 论文内容具体安排 4
第2章 算法设计及实现 6
2.1 基于MeSH的检索算法 6
2.1.1 映射算法 6
2.1.2 特征选择算法 6
2.1.3 一致性评估算法 7
2.1.4 theme算法实现 7
2.2 结合MeSH的推荐算法 12
2.2.1 基于内容的推荐 12
2.2.2 基于相同作者的推荐 13
2.3 本章小结 13
第3章 生物文献检索与推荐系统设计及实现 14
3.1 需求分析 14
3.2 数据库选择与设计 15
3.3 系统框架 16
3.4 系统实现 17
3.5 系统测试 18
3.6 本章小结 22
第4章 总结与展望 23
4.1 总结 23
4.2 展望未来 23
4.3 个人体会 23
第1章 绪论
本章主要从研究背景、研究意义、国内外研究现状、主要工作及本文具体安排等几个方面进行阐述。
1.1 研究背景及意义
随着大数据时代的到来,海量的信息暴露在人们面前。一方面,人们可以随心所欲地遨游在信息的海洋中,可以更加方便地了解这个纷繁陈杂的世界。另一方面,在享受便利的同时,人们也需要花费大量的时间和精力来排除干扰信息,提炼出真正对自己有用的信息。生物领域的研究人员亦是如此。
搜索引擎的出现在一定程度上满足了人们对信息检索的需求。通过Google和百度,人们可以较为方便地获取到自己想要的新闻、图片、小说,视频等信息。但是,对一个专业的生物研究人员来说,这是远远不够的,他们在检索时,希望得到更加精确的结果,而不是如搜索引擎那样,返回网页、视频等各式的信息。因此,为了解决生物研究人员对文献的检索问题,我们需要为其构建专门的文献数据库,并提供专业的、简易的,有效的查询接口。同时,根据生物研究人员对文献的历史操作(如浏览,收藏,下载等)数据,猜测其偏好的文献类型,然后主动地、定制化地为他们推送相关的文献,也可以进一步地缩短其获取文献的时间。
在此背景下,本文研究设计了生物文献检索与推荐系统,借助本系统,生物研究人员可以极大地提高获取生物文献的效率,将主要精力投入到科学研究上,从而为社会的发展人类的进步做出贡献。
1.2 国内外研究现状
本小节分别对文献检索以及推荐算法的国内外现状进行阐述。
1.2.1 文献检索国内外研究现状
就生物文献检索而言,主要有自由词检索和基于MeSH(Medical Subject Headings)主题词检索两种方式。
自由词检索基于用户输入的检索关键词,如果文章题目、摘要或者正文中存在用户输入的关键词,该文章就被命中[1,2]。自由词用词灵活,并且直观易懂,方便用户掌握,但是检准率及检全率都很难保证[3]。如,有的文章包含了“蜜蜂”,但是所讲的主题和“蜜蜂”并没有太大关系,而有的文章虽然讲的主题是“蜜蜂”,但是文章中却没有出现“蜜蜂”。在这两种情况下,采用自由词检索的方式,检索出来的结果都不能令人满意。另一方面,某一概念通常存在多种表达,如对于“扁桃体”这个词,就有“amygdala”、“tonsilla”、“tonsil”和“throat-almond”等表达方式,此时用户想要保证检索的全面性、准确性,就需要输入多个关键词。这样对用户而言,较为繁琐。另外,用户在检索某一概念时,也会希望了解到和这一概念相关的其他概念,这时,采用自由词检索的方式也不易做到。如用户输入“扁桃体”时,可能还希望得到“免疫系统”方面的信息(实际上“免疫系统”是“扁桃体”的上位词)。
MeSH是由美国国立医学图书馆创建和维护的医学主题词表,MeSH的使用可以使标引者和检索者对同一概念的表达达成一致,避免用多个词语表达一个概念,提高了检索的效率[3]。如对上述的“扁桃体”,在生物医学数据库中,如果采用MeSH主题词“tonsil”,那么包含其他词汇的文献也会一并检出。在生物领域中,MeSH主题词扮演了类别的作用,每篇生物文献都可归属于一个或者多个MeSH主题词,而每个MeSH主题词也包含了一篇或多篇的文献。然而,相比自由词检索,MeSH主题词检索方法复杂,主题词难以确定并且检索结果不够直观,而自由词检索十分灵活,检索结果直观易懂[3]。同时,主题词的标引需要花费大量的人力、物力,更新起来较为缓慢,对用户的要求也较高[2,4]。
因此,若能综合两种方式的优势,取长补短,可以使检索的灵活性,检索的准确性都达到一个较好地效果。
文本的表示及其特征项的选取是文献检索的一个重要环节。
文本的表示将文本从无结构的原始文本转化为结构化的可供计算机处理的信息。目前最常用的文本表示方法是向量空间模型(VSM)。然而,向量空间模型有一个严重的问题,我们称之为维度灾难——即使是一个中等大小的文本集,在其中出现的独一无二的一元词和二元词也可能有几千甚至几万个,从而导致本地特征空间的维度过于庞大[5]。对很多机器学习算法而言,这是无法接受的,例如,极少的神经网络能够处理如此数量的输入节点。因此,在不牺牲文本中的重要信息的情况下,降低本地特征空间的维度就显得非常的迫切了,这也是特征选择的目的所在。特征选择方法包括通过语料库统计去除无信息量的词以及通过组合较低级别的特征词来构造新的特征词。Lewis和Ringuette在通过朴素贝叶斯模型和决策树方法来进行二元分类的过程中使用信息增益(IG)来大量地降低了文档的词汇量[5,6]。Wiener等使用互信息(MI)和卡方检验(CHI)来为神经网络选择输入节点[7,8]。Yang和Schutze等使用主成分分析来找到文本特征向量中正交的维度[7,8,9]。Kim提出采用theme算法进行特征选择[10]。Yang通过比较评估各种特征选择算法,得出信息增益和卡方检验对降维而言是最为有效的方法。下面,对信息增益做出一个简短的介绍。
信息增益通过测量特征的存在能够为分类系统带来多少信息量来衡量特征的重要程度,带来的信息量越多,那么该特征就越重要。如果文本的类别共有m个,那么词t的信息增益定义为:
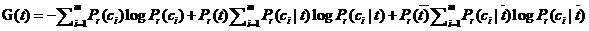
其中,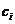 表示数据集中,属于类别的文献篇数占总文献篇数的比,
表示数据集中,属于类别的文献篇数占总文献篇数的比,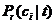 表示包含词t的文献中属于类别的文献占比,
表示包含词t的文献中属于类别的文献占比,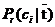 表示不包含词t的文献中属于类别的文献占比。信息增益的缺点在于,相比于特征对某一类别的贡献,它更看重于特征对系统总体的贡献,这样提取出来的特征词可能能够较好地反映系统的主题,但是无法较好地反映某一类别的主题。
表示不包含词t的文献中属于类别的文献占比。信息增益的缺点在于,相比于特征对某一类别的贡献,它更看重于特征对系统总体的贡献,这样提取出来的特征词可能能够较好地反映系统的主题,但是无法较好地反映某一类别的主题。
1.2.2 推荐国内外研究现状
传统的推荐系统可以初步地分为三类:基于协同过滤的推荐系统、基于内容的推荐系统以及混合式推荐系统[11,12]。
Goldberg等于1992年提出协同过滤算法,并将其应用到Tapestry系统中[13]。协同过滤算法又分为两类:基于用户的协同过滤算法以及基于物品的协同过滤算法。基于用户的协同过滤算法主要关注于用户偏好模型的建立。该算法引入用户相似性度量和加权相似性求和来预测用户的兴趣。基于物品的协同过滤算法和基于用户的协同过滤算法十分相似,它基于用户更喜欢和他们感兴趣的物品相似的物品这一假设。该类推荐系统为某个特定的用户计算相似的物品,能够有效地改进推荐的准确性和相关性。GroupLens[14]、Video Recommender[15]和Ringo[16]是首个使用协同过滤算法来进行自动预测的系统,Amazon.com使用协同过滤算法来推荐书籍,Jester系统则使用协同过滤算法来推荐笑话[17]。协同过滤算法的缺点在于,当新的物品加入时,由于缺少用户对该物品的喜恶信息,需要很长一段时间,该物品才能得到推荐。
基于内容的推荐算法使用物品的内容来为物品偏好建模。总体而言,基于内容的推荐算法由三部分组成。第一部分为内容分析,即提取物品的内容描述。第二部分为配置文件学习,通过学习和用户有关的物品的内容来生成用户的配置文件。例如,相关反馈算法可以用来在网页推荐中生成用户配置文件。第三部分是过滤组件,通过将配置文件中的物品和候选物品进行相似性距离排名来推荐相关的物品。当前,基于内容的推荐系统常被用来推荐包含文本信息的物品,如文献、网站和新闻等。这些物品的内容通常被描述为特征词,例如,Skskillamp;Webert系统使用128个信息量最大的词来表示文献[18],Fab系统则使用100个最为重要的词来表示网页内容[19]。基于内容的推荐系统主要的缺点在于对推荐对象的限制,推荐对象必须可以被计算机自动化地解析处理(如文本)或者已经被人工地标注了特征。另外,基于内容的推荐系统,其推荐内容比较单一,如果用户之前没有表示出对某物品的偏好,那么相似的物品永远不会被推荐,即使用户可能对该类物品有着潜在的兴趣。



