机器阅读理解技术研究开题报告
2020-02-18 19:33:16
1. 研究目的与意义(文献综述)
阅读理解作为常见的一种题型,对于绝大多数人来说都不陌生,在从小到大的语文和英语科目中非常普遍的存在。机器阅读理解其实和人阅读理解面临的问题是类似的,不过为了降低任务难度,很多目前研究的机器阅读理解都将世界知识排除在外,采用人工构造的比较简单的数据集,以及回答一些相对简单的问题。
让机器阅读文本,理解文本语义,是实现自然语言理解的重要一步。而自然语言理解又被称为人工智能皇冠上的明珠。自从人工智能的概念诞生以来,让机器理解语言,并能够像人类一样使用语言进行交流,一直是许多人工智能研究者的愿景和目标。而如今随着深度神经网络的兴起,人工智能也迎来了新的生机。自然语言理解作为人工智能领域长久以来无人力及的明珠,也藉由大规模数据集的出现和计算能力的急剧提升,达到了前所未有的研究热度,无论在学术界还是工业界,成为人工智能领域的必争之地。由此可见,机器阅读理解本身具有极其重要的研究意义。
近几年,机器阅读理解任务的研究在国外上获得空前的瞩目,许多著名的研究机构,如斯坦福大学、卡内基梅隆大学、艾伦研究院等,工业界如 ibm、google、facebook 等巨头也纷纷加入到这一任务的研究中来。例如:herman在2015年发布填空型大规模英文机器阅读理解数据集cnnamp;dailymail,使深度学习方法应用在机器阅读理解任务上成为可能。herman提出三个深度学习模型,内部结构有所差别,但整体框架均为通过神经网络学习到问题和原文中每个词的表示,并基于这些表示进行打分,得分最高的词即为最后的答案。对于 cnnamp;dailymail 数据集,其答案一定为出现在原文中的一个词,根据这一特点,kadlec受 pointer network启发提出 asreader 模型,直接将原文中每个词的注意力相加作为其成为答案的概率,进而输出答案。这一模型非常简单,但取得了当时最好的结果,也启发了后续一系列模型。
2. 研究的基本内容与方案
基本内容:
1)基于深度学习理论,使用并学习现有的国内外MRC模型系统
2)对Du-Reader数据集进行研究,建立一个MRC系统
目标:
1)对于给定问题和其获选文档集合,要求阅读理解系统输出能够回答问题的文本答案;
2)文本答案能够正确、完整、简洁地回答问题;
3)对于是非类型问题,能够进一步给出相应答案的是非判断(Yes/No/Depends)
拟采用的技术方案及措施:
一、BiDAF、Match-LSTM、R-NET模型介绍
本选题将选用以下三种模型分别对Du-Reader数据集进行研究并相比较获得结果。以下是模型简介:
1)Match-LSTM
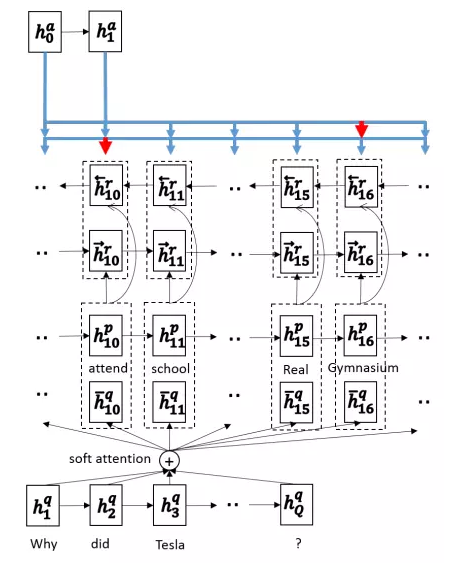 | |
Match-LSTM是由(Wang amp;Jiang,2016)发表在NAACL的论文提出,用于解决NLI(NaturalLanguage Inference,文本蕴含)问题。文本蕴含问题:给定一个premise(前提),根据这个premise去判断相应的hypothesis(假说)正确与否,如果从这个premise中能够推断出这个hypothesis,那么就判断为entailment(蕴含),否则就是contradiction(矛盾)。
| |
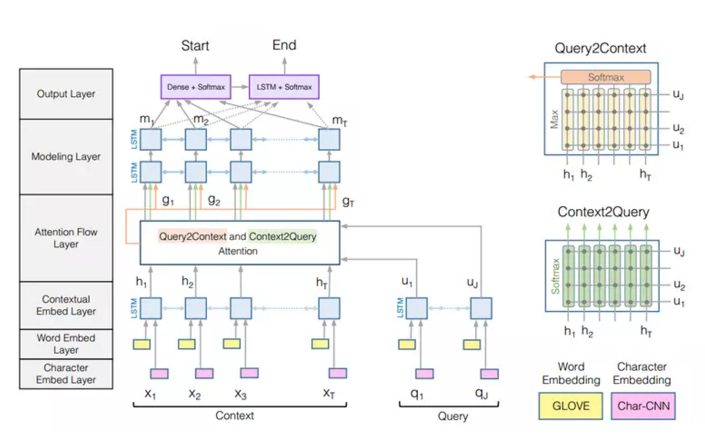
2)BiDAF
Bi-Directional AttentionFlow(BiDAF)模型由Minjoon Seo等人提出。该模型是针对SQuAD数据集提出的。模型中间的交互层使用了整个文章、问题两个角度的注意力机制。由于答案是原文中的短语,因此在输出层模型预测文章的起始位置和结尾位置,那么预测的答案就是这两个位置之间的词或短语。
| |
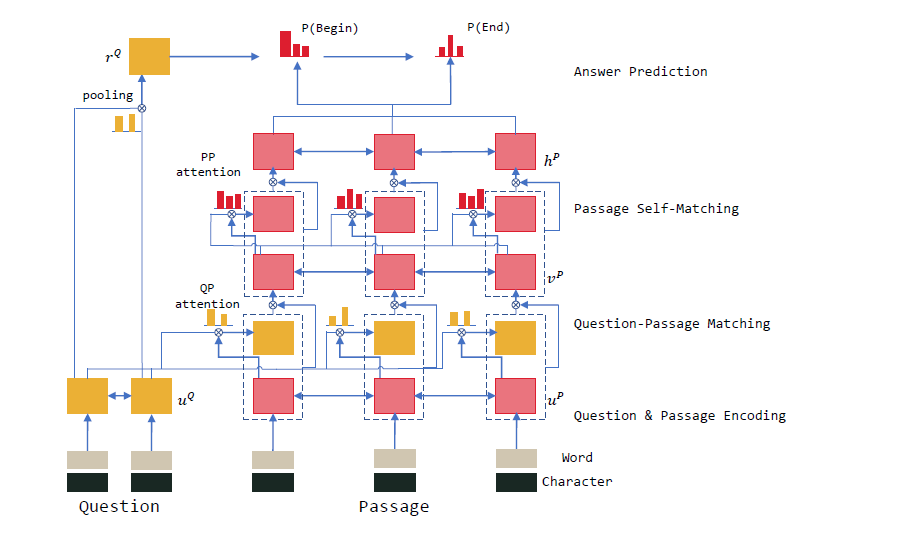
3)R-NET
R-NET模型一共分为四个步骤,分别为QUESTIONAND PASSAGE ENCODER, GATED ATTENTION-BASED RECURRENT NETWORKS, SELF-MATCHINGATTENTION, OUTPUT LAYER, 基本结构可观察上面所示的结构图。
二、实验方案
1、使用由百度提供的几种基线系统以及其他开源系统分别进行实验比较。
2、下载Du-Reader数据集进行训练和测试。
3、预处理原始数据,首先应分段“问题”,“标题”,“段落”,然后将分段结果存储到“segmented_question”,“segmented_title”,“segmented_paragraphs”
4、预处理数据准备好后,生成词汇表文件。
5、使用基于Tensorflow1.0的BIDAF和Match-LSTM模型以及使用R-NET模型,并设置相关的参数进行训练,其中考虑到数据集和模型容量非常大,超出了设备成功运行整个程序的能力,因此使用其提供的演示数据。
6、最后使用BLEU-4和Rouge-L对不同问题类型模型实验进行评估。
7、下载MS MARCO V2数据集,并将数据从MS MARCO V2格式转换为Du-Reader格式。然后,在MS MARCO数据上运行和评估Du-Reader基线系统,实现在多语言数据集上运行基线系统。
3. 研究计划与安排
(1)2019/1/19—2019/2/28:确定选题,查阅文献,外文翻译和撰写开题报告;
(2)2019/3/1—2019/4/30:系统或技术架构、程序设计与开发、测试与完善;
(3)2019/5/1—2019/5/25:撰写及修改毕业论文;
4. 参考文献(12篇以上)
[1] 朱海潮,刘铭,秦兵.基于指针的深度学习机器阅读理解[j].智能计算机与应用,2017,7 (06):157-159 161.
[2] 朱国轩. 基于深度学习的任务导向型机器阅读理解[d].华南理工大学,2018.
[3] 李亚慧. 机器阅读理解模型中的关键问题研究[d].哈尔滨工业大学,2018.



