影响用户决策的商品属性约简毕业论文
2020-02-19 17:01:22
摘 要
电商高速发展的环境下,在提升用户体验方面,出现了越来越多研究,如,通过各种算法提高用户推荐效率,或者将用户进行聚类,再进行协同过滤等,具有非常实用的现实意义。本文借助粗糙集理论对商品属性进行了约简,这是从另一方面为提高用户体验做准备的,对研究用户购买行为方面具有重要的指导意义,目的是为了锁定商品哪些属性是决定用户购买的核属性。
本文主要使用了粗糙集理论的属性约简算法。算法核心包括求集合属性上下近似,并对集合属性进行约简。论文主要研究了粗糙集理论和方法模型,商品属性集的分类,以及如何对影响用户决策的属性集进行约简。论文最后采用一个算例对本文所述核心内容进行说明。
研究结果表明,粗糙集属性约简在约简商品属性方面是可行的,并且其无需先验知识,这也是其得以广泛应用的其中一个原因。
关键字:商品属性;粗糙集理论;属性约简
Abstract
In the serroundings of rapid development of e-commerce, more and more studies have been conducted on improving user experience, such as improving user recommendation efficiency through various algorithms, or clustering users and then filtering collaboratively, which have very practical significance.In this paper, the commodity attributes are reduced with the help of rough set theory, which is prepared for the improvement of user experience and has important guiding significance for the research on the purchase behavior of users. The purpose is to determine which attributes of commodities are the core attributes that determine the purchase of users.
This thesis mainly uses the attribute reduction algorithm of rough set theory. The core of the algorithm includes finding the upper and lower approximation of set attributes and reducing set attributes. This paper mainly studies rough set theory and method model, classification of commodity attribute set, and how to reduce attribute set that affects user decision. Finally, an example is given to illustrate the core content of this paper.
The results show that the rough set attribute reduction is feasible in reducing commodity attributes, and it does not require prior knowledge, which is one of the reasons for its wide application.
Key Words:Commodity Attributes; Rough Set Theory; Attribute Reduction.
目 录
摘 要 I
Abstract II
第1章 绪论 1
1.1研究背景及意义 1
1.2国内外研究现状 1
1.2.1商品属性 1
1.2.2粗糙集 1
1.3研究内容与方法 3
1.3.1研究内容 3
1.3.2研究方法 3
1.4技术路线 3
第2章 粗糙集理论基础 5
2.1粗糙集基本思想 5
2.2 基于粗糙集的属性约简方法 8
第3章 商品属性集分析 13
3.1商品属性组 13
3.2其他特性——用户评价 14
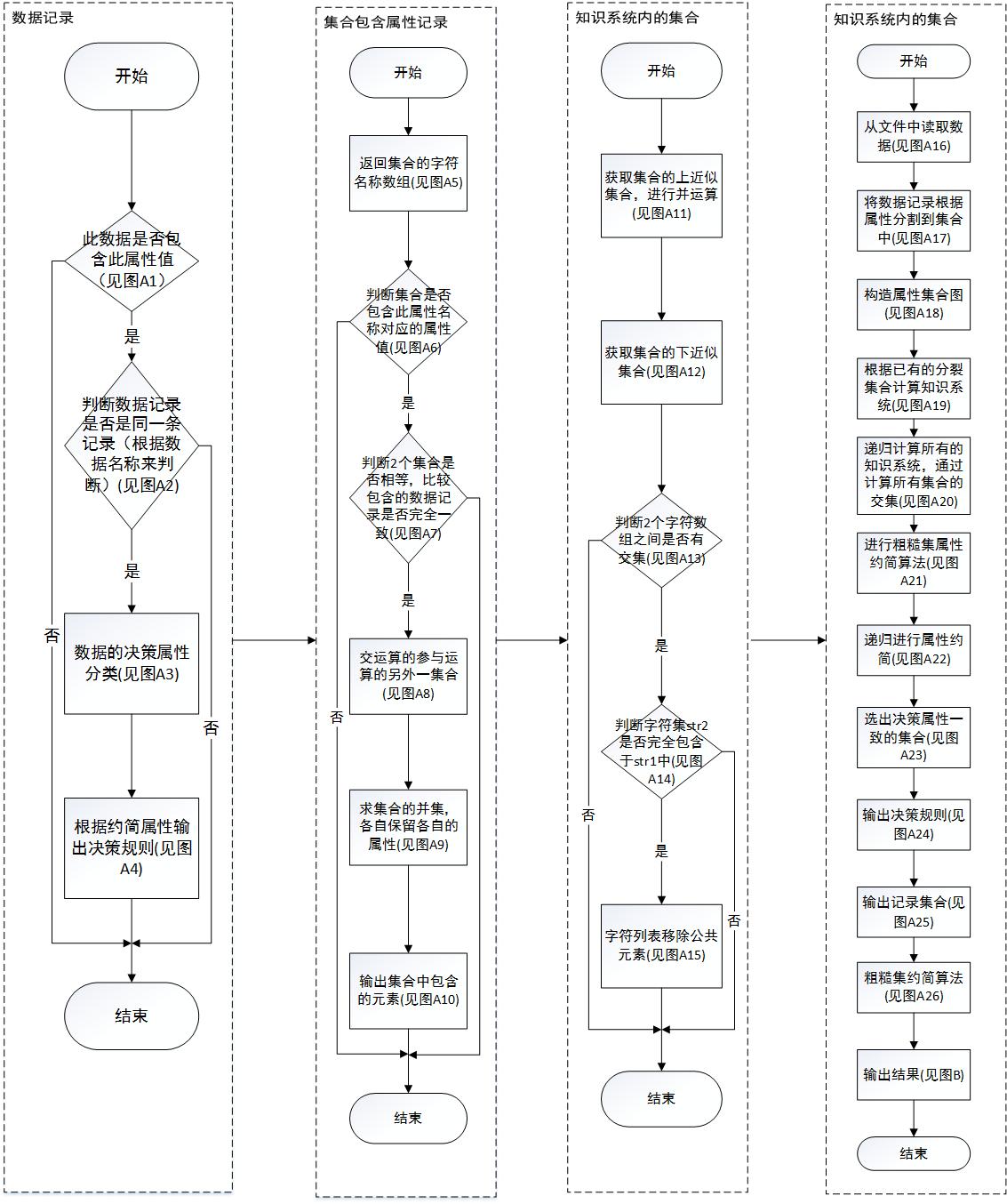
第4章 约简算例 16
4.1属性约简简述与数据准备 16
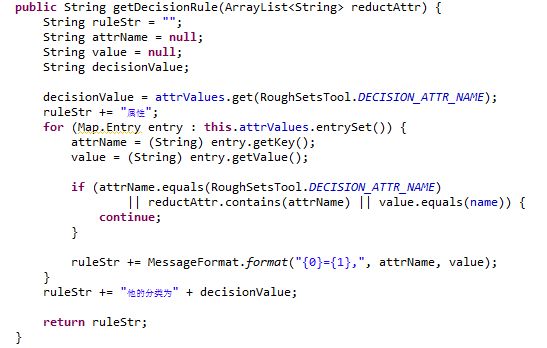
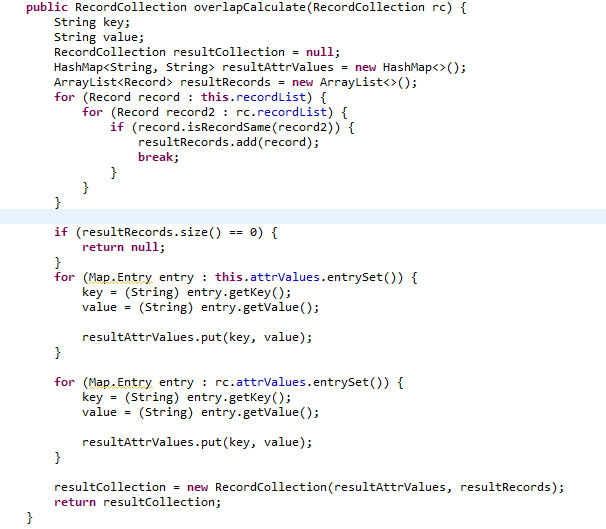
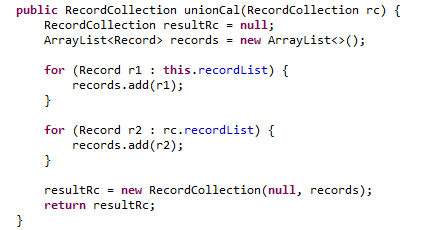
4.2算法实现流程 17
4.3输出结果 18
4.4结果分析 18
第5章 结论 20
参考文献 21
附录A 22
附录B 38
致谢 39
第1章 绪论
1.1研究背景及意义
在电子商品出现的在线采购时代,可以在因特网上购买各种各样的商品,在这个时代,网上采购为购买者提供了很多便利,并为用户“带回家而不出门”提供了大量时间。然而,随着电子商务的增长以及初级商品种类和数量的迅速增长,信息的转让不断增加,消费者面临着越来越多的选择。这给消费者做出购买选择无疑会构成阻碍,会影响用户体验。
尽管在目前建议的技术方面取得了重大进展,但解决影响用户的采购选择仍然更加困难。有一个简单的基础,通过简单的研究方法,商品特性数据,研究商品特性对用户决定的影响,跟踪客户的经验,并为改善客户的经验提供坚实的基础。这对买家和经销商都意味着很大的意义。
1.2国内外研究现状
国内外有关本文研究方向的内容很多,可大致分为两个分类,一个是研究商品属性,另一个是研究粗糙集。
1.2.1商品属性
阮光册[1]研究了商品属性的情感表达与商品销售热度的关系,了解到正负情感词对一位用户购买某件商品的行为影响,正的情感词对用户购买行为有促进影响,负的情感词对其购买行为有阻碍影响,影响的这个度,以及如何影响,这篇论文有很好的说明。高长远[2]等人研究了商品属性值和用户特征的协同过滤算法,这是为了降低数据的系数程度,提高推荐效率。星雨[3]研究了基于商品属性集的个性化研究,其研究非常具体,也提供了案例算法,提高推荐质量。Silke Bambauer-Sachse, Priska Heinzle[4]商品与服务的比较广告:不同类型的产品属性通过消费者抗拒和激活对消费者反应的影响。Yuren Wang, Xin Lu, Yuejin Tan[5]研究了产品属性对顾客满意度的影响:洗衣机在线评价分析。Wan-I. Lee, Shan-Yin Cheng, Yu-Ta Shih[6]研究了网络购物中产品属性、参与度、口碑和购买意愿之间的影响. Shu-hsien Liao, Hsiao-ko Chang[7]研究了一种基于粗糙集的在线消费者推荐系统关联规则方法。
1.2.2粗糙集
周创德[8]主要就粗糙集求核和属性约简进行研究,一方面有针对性地解决了问题,另一方面又提出了一种更优化的方法。刚毅凝[9],田迪[10],杜金涛[11],杨本植[12]将粗糙集研究和电子商务推荐系统结合起来研究,将用户体检又提升到一个新的层面。邬阳阳[13]研究了大数据和粗糙集,为大数据研究提供了另一种角度。粗糙集团理论——一种数学工具,它描述不完整和不确定性,有效分析不准确、不一致和不完整的信息,分析数据,提取潜在知识并揭示潜在模式。利用一个简单的分类机制,对已知的知识库进行分类,对知识进行近似描述,并制作一个简明的格式,以取得我们希望的结果。
粗糙集理论,是由Pawlak教授在1982年提起[14],用于分析和处理不正确、不一致、不完全的情报和定量的知识。粗糙集理论原本的原型,从分析比较简单的情报模型开始,其基本的思想,就是保持原分类能力不变,通过等价关系的分类这样的方式,来发现知识、实现知识约简,导出概念分类规则[4]。如今,有关于粗糙集的国际会议有3个相关理论在中国也得到了空前的关注并且得到了迅速发展[4]。从2001年开始每年中国都举办中国粗糙集和软件计算相关的学术会议。并且各种各样的粗糙集相关的国际学术会议也不断地在中国展开。但是因为诞生的时间还不是很长,其他的一些理论和诞生之初还在发展中,理论之上,还存在待解决的问题,并且也还有完备的必要性,另一方面,在应用上也有必要检查修正并改善。1992年第一回国际粗糙集会议在波兰召开,在这次会议商谈集合近似定义的基本思想,与此对应,在以集合为基础的研究环境下研究学习的器械。随后,以粗糙集理论为主题的国际的会议每年会开一回,就其理论和应用进行展开。粗糙集理论的不确定的描写是相对客观的,在无先验知识的情况下,提供严格处理分类数据处理问题的方法,在保留关键信息的前提下,把知识压缩到最小程度,从能提示简单模型的数据的经验中,得到确认的知识。因为其规则,不确定,和问题的处理局势方面、以及其他有着理论道具的方面相比,其更有优越性,因此成为数据挖掘的重要工具之一。粗糙集理论,不需要考虑先验知识的性质,一部分学者,对以粗糙集理论为基础的相关应用领域分支的主题展开研究,研究数据处理的一些问题。例如,根据以知识不确定特征为核心来进行分析,在此基础上,取得缺省知识数据,数据推动自主学习、数据推动自主的粒计算、数据驱动的概念学习的研究,能得到良好的结果。初步确认3DM的妥当性。粗糙集理论研究的最新进展,主要有以下几个方面,可变精度粗糙集的研究、连续属性的离散化处理、不预期情报处理、粗糙集理论拓展的研究、粗糙集的与神经网络结合的研究、与不明确集合结合的研究以及其他一部分粗糙集理论关联的研究。
粗糙集在我国的开始虽然有点晚,但是因为理论的研究和与此对应的我国的学者的积极参与,如今正在急速发展。而且,一些与粗糙集相关的国际国内会议不断在我国的各大城市举行。2001年5月,举办了“第一次中国粗糙集和软件计算机学术研讨”,创始者是z.pawlak教授,宣布大会报告。随后每年的会议,都有在规模和质量方面上很好的改进。例如,在2010年10月12日,第10届中国粗糙集和软件计算机会议、第4届中国网站知识、第4回中国粒计算会议在重庆电气大学第3国际会议中心盛大开幕。这回的主席报告,重庆邮电大学计算机学院的院长教授主办。这次会议期间,根据国内外专家的报告书显示,有与大会相关的部门前学术会议。除会议外有与粗糙集相关的论文,在国内的计算机的核心杂志上发表了。粗糙集理论,在国内国外急速发展与应用,并且已被证明在时间方面非常游泳,如今甚至也有在专家系统应用成功的案例。
可见国内外无论对此商品属性还是粗糙集方面有许多研究,且研究得非常深入透彻,但从另一方面来看,将二者结合起来,利用粗糙集对商品属性进行约简的研究还是不够多。为此,本论文从这点出发,利用粗糙集约简商品属性,从商品众多属性中找到核属性,为用户提供更优化的服务。
1.3研究内容与方法
1.3.1研究内容
(1)介绍研究的背景、目的,再介绍研究方法,并展示文章结构图。
(2)分析粗糙集在商品属性约简方面的现状,主要介绍两部分,第一部分主要介绍粗糙集相关情况,第二部分分析商品属性约简情况。
(3)简要说明影响用户决策的商品属性集以及其他特性,并适当做了分类。
(4)介绍属性约简算法,主要有三类算法:基于并行计算的属性约简算法、基于增量学习的属性约简算法、基于粒计算的属性约简算法。
(5)通过一个小案例对本文属性约简进行一个说明。
(6)总结并致谢。
1.3.2研究方法
(1)文献分析法
本研究主要借助了知网等期刊、文献等,并结合查阅外网有关文献,来确定本主题的意义和研究方法。
(2)粗糙集属性约简算法
这是本文的核心内容, 主要借助这个实现算法案例分析。
1.4技术路线
本文技术路线如图1.1所示:
图1.1 技术路线图
第2章 粗糙集理论基础
2.1粗糙集基本思想
是波兰学者Pawlak提出粗糙集理论,他主要通过上下近似算法来描述非专门性的正确的知识,是一种灵活的数学工具,主要处理信息不一致和不确定。该理论不仅可以建模非线性和不连续的函数关系,而且不具有很高的主观性,能够很有效的对大数据进行处理。在大数据领域,粗糙集理论的研究有很多,主要集中在两个方面:模型的扩展和属性还原算法的设计。粗糙集利用等价类的概念来研究问题,并以集合的上下近似来说明集合,是一个成熟的数学理论,不需要任何先验知识[15]。
(1)粗糙集理论的一些基本概念如下所示:
a)知识的含义
在粗糙集理论中,“知识”是主要的一部分,并且被认为是一种神秘能力,它在不同类别中有许多不同的含义,并且情节是不均匀的。比如,在远古时候,社会的行为是源于对伙伴的关心;人们一定要辨别哪些是可以吃的,哪些是不可以吃的;医生在为病人提建议开药前,必须确认病人所患什么病痛;现在网购发展如此迅速,消费者要想在诺大的商品间找到自己想要的,就必须明确自己本身的需求。这就是一种什么能力。
b)不可分辨关系与基本集
在划分对象时,若他们差别不大,可以被认为是同一类对象,并且称他们为不可分辨关系。举个例子,如果将一个空间的人按照性别分离成:男性和女性,那么两个同为男性的两个人就是不可区分关系,因为描述他们的属性特征都为男性。如果再加入肤色属性特征:白种人和黄种人,就可以将人群分为四种:男性白种人、女性白种人、男性黄种人、女性黄种人。这时,如果同为男性,二者为性别属性特征下的不可分辨关系。不可分辨关系也称为一个等效关系。两个女性白种人间的不可分辨关系可以理解为它们在女性,白种两种属性特征下存在等效关系.
c)基本集:是由粒子组成的,这些粒子是建立在领域知识的基础上,粒子与粒子之间的关系互相不可分辨,共同组成基本集。知识也可看作是一组等效关系,将论域分类成等效类。
d)粗糙集上下近似
在粗糙集理论中,上下近似算法是一对基本的概念,也是粗糙集相似度量的方法。从一般角度和大众理解方面来看,它们之间存在着包含与被包含的关系。但是,当把它们推广到双论域上多粒度粗糙集模型时,集合之间的包含关系就不一定呈现了。下面讨论上下近似的概念。假设给定了如下所示数据:
x1:女性黑种人,x2: 男性黄种人,x3:男性黑种人,x4: 男性白种人,x5:女性黄种人,x6: 男性黑种人,x7:女性白种人,x8:男性黄种人
一个A上的子集合X={x2,x5,x7},那么用知识库中的知识应该怎样描述它呢?无论是单属性知识还是由几个知识进行交、并运算合成的知识,都不能得到这个新的集合X,也就是在所有的现有知识里面找出跟他最像的两个一个作为下近似,一个作为上近似。可以选择“女性黄种人或者女性白种人”这个概念:{x5,x7}作为X的下近似。选择“女性或者黄种人”{x1,x2,x5,x7,x8}作为上近似,值得注意的是,下近似集是在那些所有的包含于X的知识库中的集合中求交得到的,而上近似则是将那些包含X的知识库中的集合求并得到的。可通过粗糙集判断集合粗糙程度。
(2)粗糙集的一些特征使它特别适合进行数据挖掘和数据分析[16]。如下所示:
a)粗糙理论是导入知识粒度概念,将知识粒度化后,其判断正确与否的主要指标是知识粒度的正确性。
b)粗糙集理论的主要特征是进行数据的预处理。针对此数据的冗余和错误,特征约简和特征选择被执行,以减小数据维数。
c)粗糙集理论的显著特征是不需要什么先验知识。在分析问题的时候,只依赖于与问题相关的一组数据,对于处理问题而言实质上是非常强的。
d)基本的粗糙集理论只适合处理离散属性数据,应用环境也非常有限。还可以利用能够识别矩阵的相关理论来执行数据处理。
(3)另一方面,粗糙集理论具有一些非常独特的观点。这些特征使得其特别适合于进行数据分析方面的应用。如下:
a)知识的粒度性:在粗糙集理论中,知识粒度是依据知识,不能正确表示特定概念的原因。这样的概念,是以不可分辨关系为粗糙集理论的基础,以此为基础定义上下近似之类的概念,从而达到接近效果的目的。
b)新型的成员关系。模糊集合是特定的所属度不同,而粗糙集的成员是由客观计算得到的。也就是说只和既定的数据相关联而避免的主观的影响。粗糙集理论,以不可分辨知识为定义。因此,知识就有了数学的含义。
c)粗糙集理论核心
知识、集合的划分、近似集合、数据库中数据挖掘的应用以及属性约简算法等是分析研究粗糙集理论的重要内容。在此先考虑一个数据库中的一个二维表,如表2.1所示,通过此表简要说明一下条件属性和决策属性这两个概念。
表2.1 数据库二维表
元素 | 有无波点 | 价格 | 有无松紧腰 | 是否购买 |
p1 | 有 | 高 | 有 | 是 |
p2 | 有 | 中 | 有 | 是 |
p3 | 有 | 低 | 有 | 是 |
p4 | 有 | 高 | 有 | 是 |
p5 | 有 | 低 | 无 | 否 |
p6 | 无 | 中 | 有 | 否 |
p7 | 有 | 高 | 有 | 是 |
属性分为两大类:条件属性和决策属性。并不是所有条件属性都是需要的,有些条件属性为冗余的。拿上表来说明这个问题,上表为一款裙子的信息,条件属性:有无波点、价格、有无松紧腰,决策属性即为:是否购买。根据上表,我们可以按属性分类,首先,条件属性波点可分类为{{p1,p2,p3,p4,p5,p7},{p6}},按条件属性价格可分类为{{p1,p4,p7},{p2,p6},{p3,p5}},按条件属性“有无松紧腰”可分类为{{p1,p2,p3,p4,p6,p7},{ p5}}。我们可以看出,“波点”属性一列,无波点的裙子是不被购买的,所以“有无波点”肯定为关键属性,而“有无松紧腰”一列,有松紧腰的会被购买,而无松紧腰的不会被购买,因此,同理,“有无松紧腰”也是关键的条件属性。反而价格一列并没有类似这样的规律,因此,该裙子的条件属性可约简掉价格属性,关键属性为“有无波点”、“有无松紧腰”。
从上述简单分析也可以看出,先验知识对粗糙集属性约简来说是非必需的,这是其一个优势,也是其能广泛应用的一个重要原因。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: