基于试卷笔迹的身份识别方法与实现毕业论文
2020-02-17 23:03:29
摘 要
随着基于笔迹身份识别技术的不断发展,通过笔迹鉴别身份已经变成了一项很重要的技术手段。在汉字笔迹鉴别领域中,书写者在书写汉字时会产生很多变形,这些有的受字体影响,还有的受书写者当时情绪影响,这些都给笔迹鉴别带来了一定挑战。
目前笔迹鉴别根据不同采样方式可分为在线和离线两类。本文主要针对离线的单个汉字文本笔迹的鉴别进行研究,完成对基于试卷的笔迹样本进行图像预处理,笔迹特征提取和基于libSVM来进行文本训练与测试三个方面进行系统的总体设计,并利用MATLAB开发平台设计完成。其中图像预处理主要是图像灰度化和大小归一化,然后改变Gabor滤波器尺度参数比较特征提取效果来确定最佳参数,通过不同方向选择的笔迹鉴定正确率比较,最终方向参数选择为60°、120°和180°三个方向,将三个方向提取到的特征串联起来组成高维特征向量,最后进行样本训练与测试完成笔迹身份鉴定,使用支持向量机(Support Vector Machines, SVM)对笔迹特征进行训练和识别,用的有效训练样本是95份,每人有五份训练样本,测试样本也是95份,用以上的方法进行笔迹鉴别,最终测试鉴别正确率为92.6%。
关键词:笔迹鉴别;特征提取;支持向量机;Gabor滤波
Abstract
With the continuous development of Handwriting-based identification technology, identification through handwriting has become an important technical means. In the field of Chinese character handwriting identification, writers will produce many distortions when they write Chinese characters. Some of them are affected by fonts, and some are affected by writers'emotions at that time. All these bring some challenges to handwriting identification.
At present, handwriting identification can be divided into online and offline according to different sampling methods. This paper mainly studies the identification of off-line single Chinese character text handwriting, completes the overall design of the system in three aspects: image preprocessing of handwriting samples based on test papers, handwriting feature extraction and text training and testing based on libSVM, and uses the development platform of MATLAB to complete the design. Among them, image preprocessing is mainly image gray level and size normalization, and then changes the Gabor filter scale parameter comparison feature extraction effect to determine the best parameters. By comparing the correct rate of handwriting identification selected in different directions, the final direction parameters are selected as 60 degrees, 120 degrees and 180 degrees. The features extracted from the three directions are connected in series to form high-dimensional feature vectors. Finally, the high-dimensional feature vectors are formed. Sample training and testing are carried out to complete handwriting identification. Support Vector Machines (SVM) are used to train and recognize handwriting features. 95 valid training samples are used. Each person has five training samples and 95 test samples. The handwriting identification accuracy is 92.6% in the final test.
Key Words: Handwriting Identification; Feature Extraction; Support Vector Machine; Gabor Filtering
目 录
第1章 绪论 1
1.1 研究背景 1
1.2 国内外研究现状 2
1.3 本文研究内容及结构安排 3
1.3.1 本文研究内容 3
1.3.2 本文结构安排 3
第2章 笔迹鉴别系统设计及预处理 4
2.1 笔迹鉴别系统设计 4
2.1.1 系统总体设计 4
2.1.2 各模块设计 5
2.2 图像预处理 7
2.2.1 笔迹图像预处理 7
2.2.2 图像灰度化与大小归一化 7
第3章 笔迹特征提取与实验结果 9
3.1 笔迹特征提取 9
3.1.1 Gabor滤波器 9
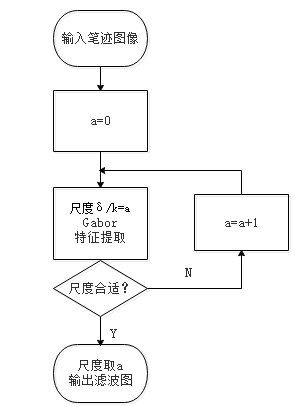
3.1.2 改进后Gabor滤波器实现与参数选取 10
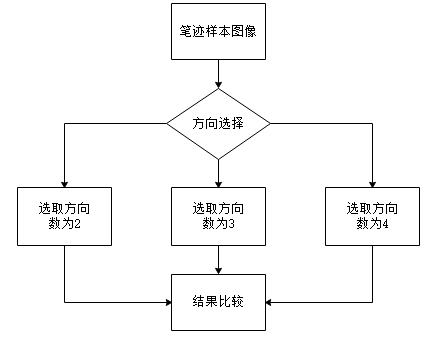
3.1.3 三种方向下特征提取 13
3.1.4 特征提取数据 14
3.2 SVM算法 16
3.2.1 传统SVM算法 16
3.2.2 libSVM多分类 17
3.2.3 SVM参数设置 18
3.2.4 实验结果 18
第4章 总结与展望 21
参考文献 22
致 谢 23
第1章 绪论
1.1 研究背景
正如俗话所说的“字如其人”,每个人书写都会有自己独有的写作风格特点,通过笔迹就能提取有关特征完成身份鉴别,有时候这种特征会受到作者书写时的身体状况或者情绪影响,可能导致笔迹变化较大,而且专门受过训练的人会模仿相关笔迹,达到以假乱真的目的[1],随着笔迹鉴别相关技术不断的进步,现在我们大多会使用计算机来分析和解决相关复杂问题,笔迹鉴别技术已经十分成熟了。手写体汉字识别(Handwritten Chinese Character Recognition ,HCCR)的研究已有50多年,其目的是为了应对大量的字符类别、相似字符之间的混淆以及个体之间不同的书写风格带来的挑战。根据笔迹数据传输的方式,笔迹鉴定可以分为在线和离线两种[2]。在线HCCR主要记录和分析笔尖运动轨迹,识别所表达的语言信息,而在离线HCCR中,分析字符(灰度或二进制)图像,并将其分类。离线HCCR有很多应用,如邮件分类、银行支票阅读、书籍和手写笔记抄写,而在线HCCR已广泛应用于生活中,如笔输入设备签名板、智能手机、计算机辅助教育等[3]。此外,它也是一个手写文本识别的重要的必须组成部分(包括在线和离线)同时考虑分割和识别,高特征识别精度是手写体文本或笔迹鉴别成功的关键。
由于部分考试的有关性质、学生的特点和考试专业的规模,考试的组织和管理具有组织考试压力大、管理难度大、代考作弊危害严重等特点。考试,这些特殊性使得自学考试面临的安全形势更加严峻,有效防止作弊尤其是代课考试作弊尤为重要,为防止自学考试作弊,首先要加强对考生的考试前教育,加强监考教师的管理,同时加强考试管理,特别是对考生的准确识别。考试机构利用笔迹识别技术对考生在每次考试中填写和复制的笔迹卡信息进行检查和验证。这是自学成才在毕业前进行身份认证的最后一道关卡,是身份认证最重要、最必要的环节。考试机构利用笔迹鉴别技术对考生在每次考试中填写和复制的笔迹卡信息进行检查和验证。这是对于那些准毕业生在毕业前进行身份认证的最后一道关卡,是身份认证最重要、最必要的环节。
由于深度学习在不同领域都有非常多的成功的例子,有鉴于此,汉字笔迹实现身份识别的求解方法已经从传统方法转变为利用卷积神经网络(Convolutional Neural Network,ConvNet),而这种方法首次报告成功应用于脱机汉字笔迹实现身份识别是多列深度神经网络[4]。之后,在ICDAR竞赛中,使用稀疏卷积神经网络实现在线情况下的最佳性能,而针对离线状况,提出了交替训练的松弛卷积神经网络。近年来,通过融合局部和全局扭曲、多监督训练、多模型投票等多种策略整合,实现了离线的最高精度。此外它还成功地应用于类似于朝鲜语笔迹实现身份识别。虽然这些方法在很大程度上优于传统方法,但它们都是基于端到端学习的[5],忽略了中长期深入研究的领域特定知识。手写体汉字识别界在过去的文献综述中报告了许多有用和重要的成就,如今,基于深度学习的方法成为新的解决手写相关问题的前沿技术。
1.2 国内外研究现状
笔迹鉴别是一种通过寻找手写图像之间的相似性来区分不同手写身份的技术。计算机手写汉字识别可以分为两类:文本独立和文本依赖方法[6],这取决于研究对象和提取特征的方法。这两种方法的主要区别在于,文本依赖性是比较不同笔记图像中的相同字符,而文本独立性是将大量手写图像中的纹理和轮廓等字符独立特征作为比较两种图像的基础。目前,文本依赖方法主要有基于模板变形比较法、方向指数直方图法和高阶相关法[7],国内一般采用基于标准模板变形比较的方法是通过标准模板,从相对于标准模板的笔迹结构的变形中提取相对应笔迹特征。变形是由像素的位移来描述的,将手写字符和标准模板转换为尽可能接近的格式,以最小化汉明距离。最后,采用贝叶斯方法或距离测量方法进行分类。方向指数直方图也是目前用到很多,它是根据手写汉字笔迹中四个方向:水平、垂直、左、右对角线来进行结构特征提取,手写文本笔迹从上述四个方向来捕捉笔迹特征来进行分类识别。高阶相关法就是将这些笔迹特征通过建立相关函数来进行鉴别,可以通过一阶或者高阶相关函数来进行建立提取的特征之间联系。此外,还有弧模频率法、行程匹配法、多通道分解法等多种方法用于实际生产。
而目前世界上研究笔记鉴别已经随着深度学习在不同领域的成功的影响,也有学者提出了一种局部特征融合[8]的方法,他们首先对笔迹图像进行提取特征,利用K临近分割,能够提取汉字字符的笔画特征;Speeded-Up Robust Features算法提取关于字符的局部纹理和形状特征;轮廓梯度方法则用于提取笔迹的轮廓与曲度信息,他们对提取的三种特征进行了结合,取得非常显著的效果。还可以利用交替训练的方法确定三种特征的权重,这种融合特征的方法得到的实验结果比传统单一特征方法要更更加可靠。还可以对传统局部二值模式算法[9]进行改进,对每个划分出的图像区间进行级联形成全局特征,也达到了很好的效果。
最近,结合了传统的特征提取方法,如Gabor和梯度特征图[10]和googlenet以获得非常高的离线HCCR精度。此外,对于在线HCCR,通过使用具有变形、假想笔划图、路径签名图和方向图等多种领域知识的ConvNet获得了最佳性能[11]。这些结果清楚地识别了使用领域知识进一步提高性能的优势。值得注意的是,在将深度学习应用于大多数图像分类任务中,生成用于增加训练数据的失真图像也是一种领域知识的利用。基于深度学习的方法也在其他与手写文本识别相关的问题中得到了应用,如作者识别、混合模型、置信度分析、手写法律金额识别和文本定位。ConvNet还可以与隐马尔可夫模型结合用于在线手写识别[12]。近年来,长短期记忆的递归神经网络[13]已成功地应用于手写体中文文本识别,而无需对字符进行显式分割。递归神经网络和ConvNet的组合也被用于场景文本阅读[14]。很明显,越来越多的与字符识别相关的问题将把注意力转向高性能解决方案的深度学习方法。
1.3 本文研究内容及结构安排
1.3.1 本文研究内容
本次毕业设计内容是了解现有笔迹鉴别方法的特点,试卷中存在每人都会书写承诺词,提取承诺词的相关特征,实现书写者身份鉴别。本次设计基本内容是:完成试卷图像中手写承诺词特征提取、设计分类器、实现书写者身份鉴别。离线文字笔迹身份鉴别按照设计流程分为图像的预处理、特征提取和分类器设计三个部分。本次设计通过基于Gabor滤波器来进行特征提取,同时利用开源的libSVM软件算法来实现特征数据分析,完成笔迹鉴定目的。
1.3.2 本文结构安排
这次编写的论文包含了4个部分的内容,具体内容如下:
第一部分绪论:文章主要从研究背景以及国内外研究现状综合阐述了笔迹鉴别的必要性,介绍了当前研究现状,基于深度学习的算法已经成为了主流。
第二部分模块设计与图像预处理:介绍笔迹鉴别整体设计框架与各模块设计,还有图像预处理的必要性和相关具体实现。
第三部分特征提取与实验结果:基于Gabor滤波器进行三次特征提取,并基于libSVM软件算法进行特征数据分析,完成笔迹鉴别判定。
第四部分总结与展望:总结本次设计工作并对下一步进行展望。
第2章 笔迹鉴别系统设计及预处理
2.1 笔迹鉴别系统设计
2.1.1 系统总体设计
笔迹鉴别系统主要利用MATLAB开发平台,进行相关图像预处理之后,利用Gabor滤波进行特征提取,再用libSVM进行模式识别,完成样本的训练与测试之后就可以得到笔迹鉴定的结果。本次设计的笔迹鉴别系统主要包含三个重要模块,图像预处理,特征提取,基于libSVM分类,总体结构如图2.1。
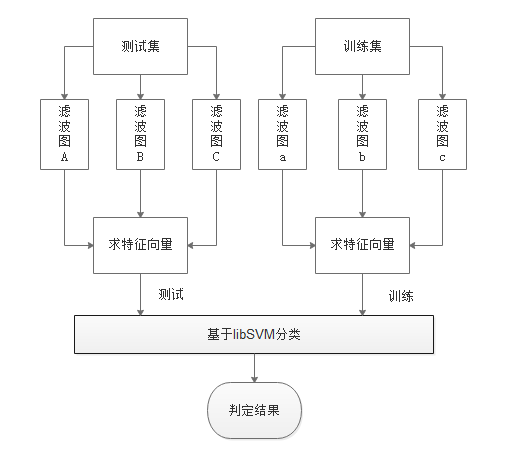
图2.1 系统总体架构
在整个系统设计中,我将分成三个主要功能实现结构,首先对所收集到的汉字手写笔迹原样本进行处理,处理之后的图片分类存放在一起,便于后续处理,再经过图像预处理,将我们用相机采集到的笔迹样本图像进行灰度化和大小归一化处理,然后我们可以将预处理过后的样本进行特征提取,提取到三个方向的滤波图之后,提取我们需要的特征数据并且完成数据分析与处理,完成这一步后就进行最后一步,使用libSVM进行样本训练,得到训练模型后进行样本测试,最终完成笔迹鉴别工作,得到笔迹鉴定结果。
2.1.2 各模块设计
1)图像预处理模块:先将所获取的原始笔迹样本进行灰度化处理并且分类编号,以便压缩图片大小,也能便于存储使用,再对一些大小不一致的笔迹图像进行大小归一化,就完成了图像的预处理相关内容,模块结构框图如图2.2。
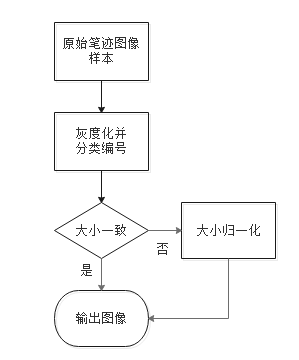
图2.2 预处理模块流程图
采集的图像原始样本经过上述处理之后不仅便于存取与后续特征提取操作,还能将笔迹中不必要的信息剔除,在对图片预处理时也要充分考虑不同文本不同背景下的笔迹图片大小等其他因素的影响,综合考虑各种方法来取得较好笔迹样本图像,必要时可以人工框选所需文本图像,对笔迹图像进行旋转缩小等操作保证该样本有效。
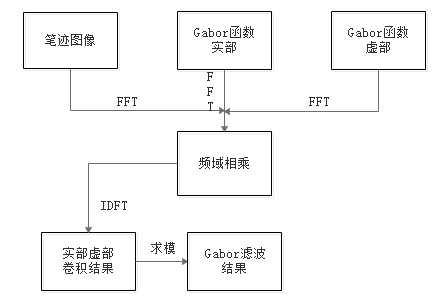
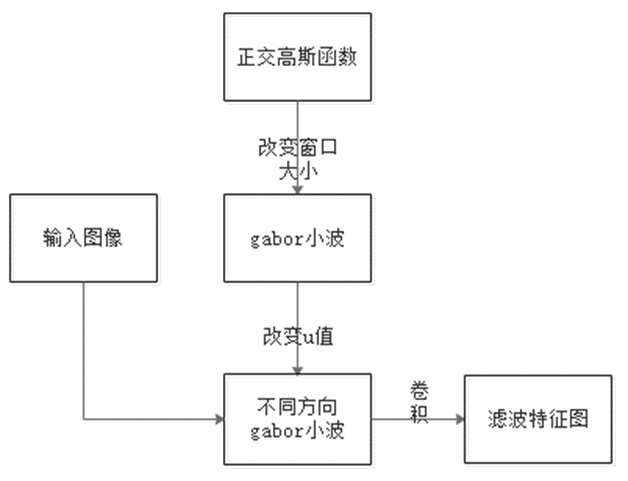
2)笔迹图像特征提取模块:预处理过后的笔迹图像就能直接进行特征提取,Gabor变换属于加窗傅立叶变换,本次使用Gabor函数在三个频域不同方向上提取到相关的特征,另外Gabor函数与人眼的生物作用相仿,所以经常用作纹理识别上,并取得了较好的效果。所以我采用Gabor特征提取,从三个方向提取特征值来进行后期模式识别,如图2.3。
特征提取模块是整个系统核心的技术,将提取的特征值进行整理之后就可以进行后续操作,编写一个Gabor滤波器函数的m文件后续即可进行调用计算,Gabor特征提取关键是参数选择,改变参数选取三个方向做卷积运算。将得到的数据进行整理,将三个方向的特征向量按照顺序连接起来,便于之后进行分析。
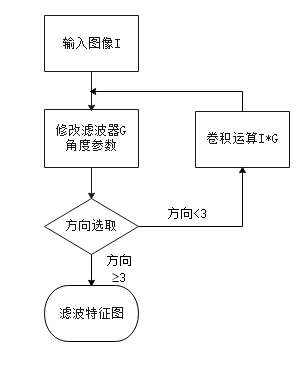
图2.3 Gabor特征提取模块结构
3)笔迹图像分类识别模块:
笔迹比对最后一步就是进行模式识别,利用libSVM进行数据学习和数据测试,得出笔迹身份鉴定结果,模块架构如图2.4。
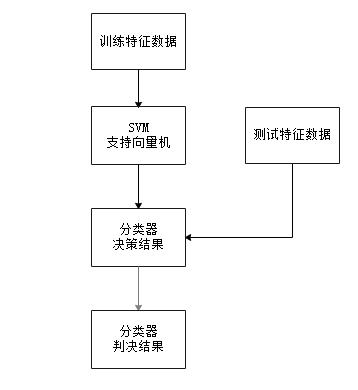
图2.4 笔迹图像分类识别模块架构
利用libSVM,设置好参数,对样本进行训练与测试,就可以完成模式识别工作,通过改变核函数的选取,通过比对结果可以分析学习模型正确率,进而分析系统设计优劣。
2.2 图像预处理
2.2.1 笔迹图像预处理
本文所用笔迹数据均为单个汉字,在现有的可用数据集中基本需要我们进行汉字分割后再进行处理,所以本文采用的数据来源于身边朋友同学,为获取笔迹原始图像,我们最初始需要将所写笔迹通过照片或者扫描的方式转换成数字图像,为保留笔迹中全部信息,可以在扫描或拍照时提高分辨率。此次进行笔迹鉴定,是采用基于Gabor滤波的方法来提取笔迹特征,这些笔迹纹理特征能表现每个书写者的书写汉字的风格,以此来作为鉴定笔迹原作者身份,所以预处理需要消除一些其他影响干扰因素才能更加准确地进行鉴定。
所以本次预处理我们有必要首先对采集到的笔迹样本图像进行预处理,去除掉字迹图片上无关的背景颜色,对于样本还要进行筛选,对于字迹模糊不容易进行鉴别的样本可以去掉,亮度等一些无关笔迹特征提取的信息,包括字迹上的一些页码或者其他无关信息进行删除,以此来减少特征提取时这些冗余信息造成的干扰,影响笔迹鉴别精度,而且彩色图像相对于灰色图像占用存储空间会更多,经过预处理也可以减少储存样本的空间,进行图像相关计算也会减少时间,特征提取时的计算量也会相应减少。本次预处理主要包括图像灰度化和大小归一化。
2.2.2 图像灰度化与大小归一化
1)图像灰度化
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: