基于L-多样性的数据发布系统应用与研究毕业论文
2020-04-13 11:09:57
摘 要
信息时代人们对个人隐私保护的问题愈发重视,而随着数据共享与数据挖掘技术的广泛应用,进一步加深了隐私保护的迫切性。科研机构对数据安全提出了各类的原则与算法,数据匿名化是发布数据时对隐私保护的常用手段,K-匿名原则降低了数据表泄露具体个体身份风险,L-多样性原则降低了因属性链接,从而发生隐私泄露的风险。在数据隐私匿名保护中,如何在保证隐私安全情况下,保留尽可能多的可用信息量是研究重点。
论文主要设计了在MyEclipse软件下,通过JavaWeb的技术,构建实现了MVC架构下的订单信息管理系统,对数据表设计实现了基于变形度信息损失量的L-多样性算法。
研究结果表明订单信息能通过匿名技术满足L-多样性,从而实现数据安全发布,且随着L值的增加,其数据隐私泄露风险随之减小,但同时数据信息可使用率会随之下降。
关键词:K-匿名;L-多样性;隐私保护;数据发布
Abstract
In the information age, people pay more and more attention to the issue of personal privacy protection. With the extensive application of data sharing and data mining technology, the urgency of privacy protection is further deepened. Research institutions for data security put forward all kinds of principle and algorithm of data anonymous is the common use of the published data on privacy protection, K - anonymous principle to reduce the risk of data table to reveal the specific individual identity, the principle of L - diversity decreased the risk of privacy because of properties link. In the anonymous protection of data privacy, how to keep as much available information as possible is the research focus under the condition of ensuring privacy security.
The paper mainly designed and implemented the order information management system under MVC framework through the technology of JavaWeb under MyEclipse software, and designed and implemented the L-diversity algorithm based on the degree of information loss of deformation degree for the data table design.
The research results show that order information can satisfy L-diversity through anonymous technology, so as to achieve data security release. As the L value increases, the risk of data privacy leakage decreases, but at the same time, the availability of data information will decrease.
Key Words:K-anonymity; L-diversity; privacy protection; data release
目 录
1 绪论 1
1.1 研究目的及意义 1
1.2 国内外研究现状 1
1.3 本课题的主要研究内容 3
2 L-多样性原理及实现 4
2.1 K-匿名 4
2.1.1 数据属性相关概念 4
2.1.2 K-匿名原理 4
2.1.3 攻击K-匿名的方法 5
2.2 L-多样性 6
2.2.1 L-多样性原理 6
2.2.2 攻击L-多样性的方法 7
2.3 匿名技术 7
2.3.1 泛化 7
2.3.2 隐匿 8
2.4 信息损失度量 9
3 基于L-多样性的订单系统设计与实现 11
3.1 订单管理系统的设计 11
3.2 L-多样性算法的设计 12
3.3 系统的联调与测试 16
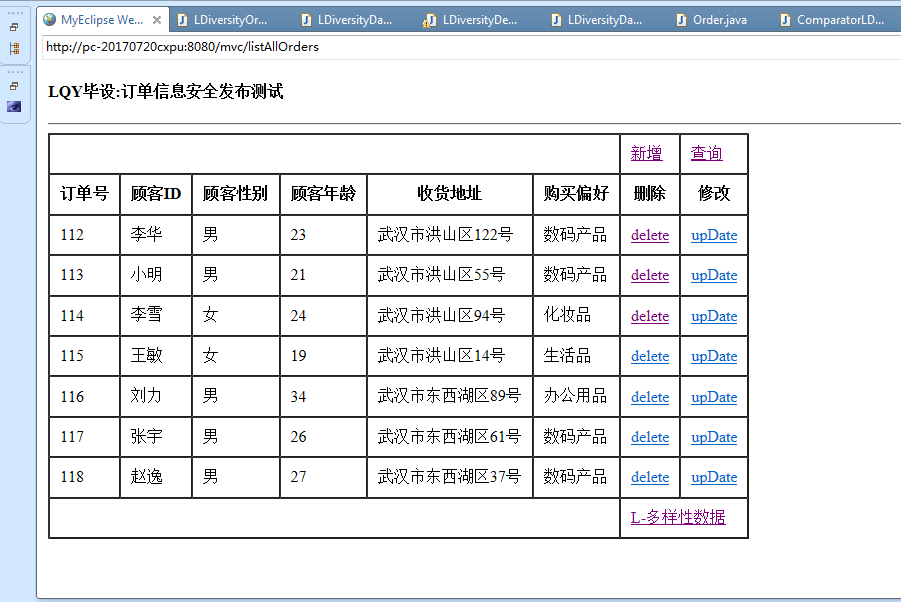
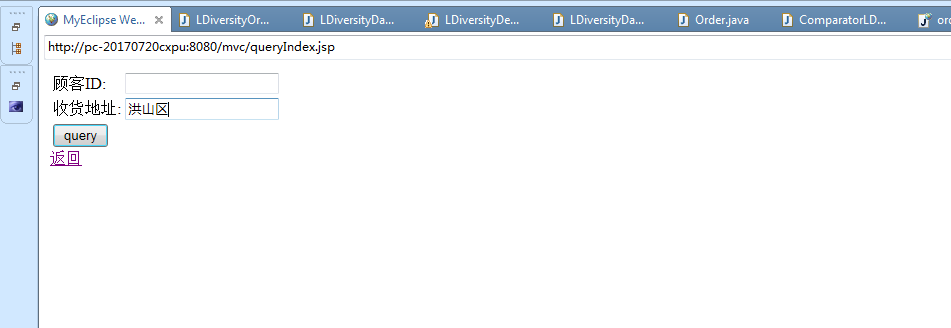
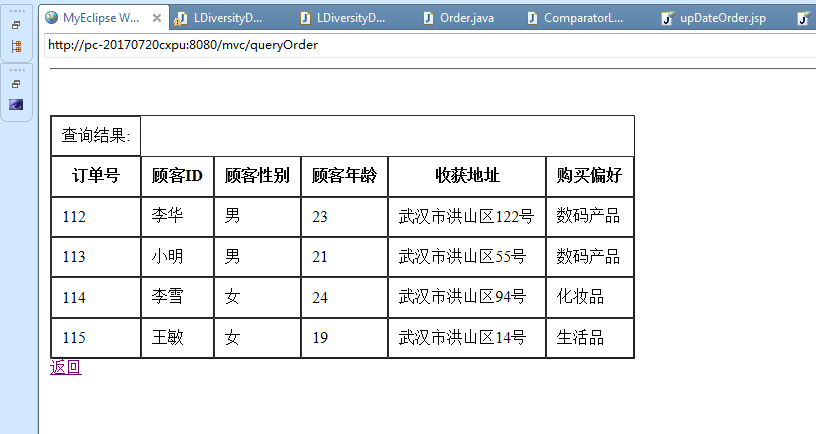
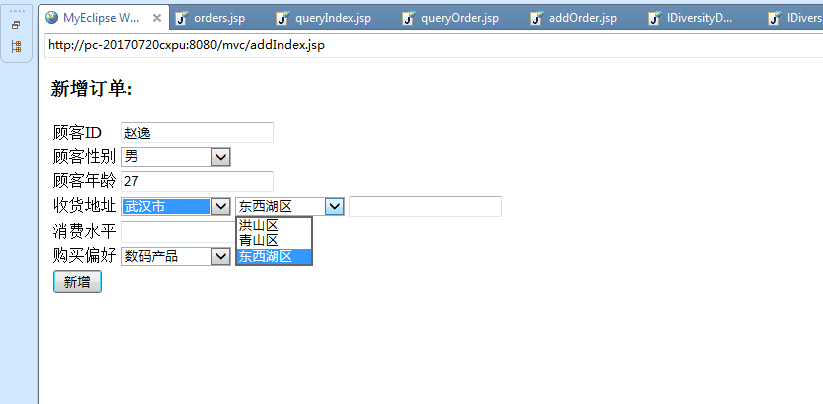
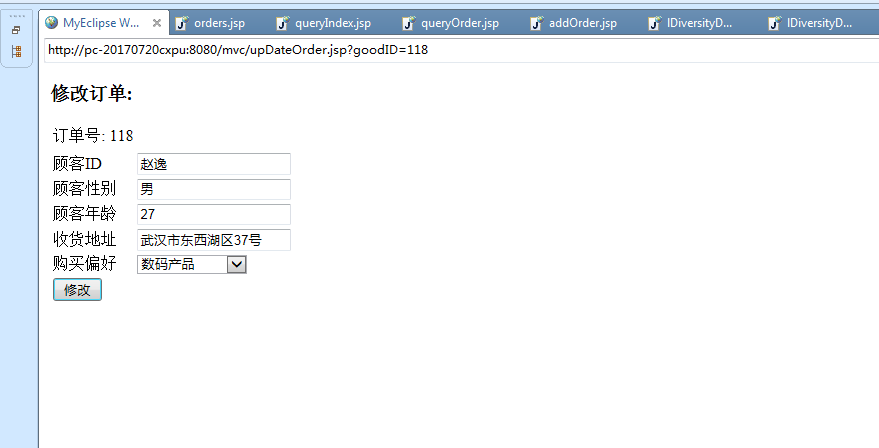
3.3.1 订单系统平台的实现 16
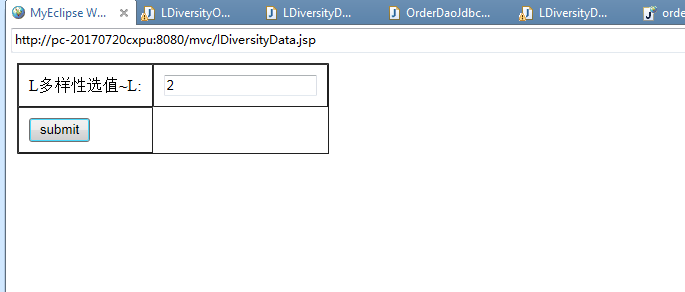
3.3.2 L-多样性数据的发布 20
4. 总结与展望 26
4.1 论文工作总结 26
4.2 研究工作展望 26
参考文献 27
致 谢 29
第1章 绪论
1.1 研究目的及意义
“隐私”,百度百科定义上,隐私是一种与公共利益,群体利益无关,当事人不愿他人知道或他人不便知道的个人信息。例如,居住在武汉市洪山区的李华,其经常在网上购物,他拥有姓名、年龄、收货地址、购买偏好等属性信息。从百度百科定义上,隐私是针对个人的属性,若是一群用户的属性,例如武汉市洪山区的用户购买力较高,这不属于隐私。如果某个攻击者能从公开的信息中,推断出具体特定的个体的敏感属性,例如攻击者推断出洪山区的李华购买力较高,那么这就是发生了隐私泄漏。
随着大数据以燎原之势的到来,信息资源已渐渐成为各国社会发展与国家安全的重要战略资源。相较于以往,信息技术的高速发展让信息共享更加容易和便捷。但与此同时,用户隐私泄露问题,伴随着以信息共享和数据挖掘为目的的数据使用,也频频发生。对于公司企业,2016年7月,微软公司遭到法国数据保护监管机构CNIL的直接发出措辞严厉的警告,起因为Window10系统过度搜集用户数据,被认定未遵守欧盟“安全港”法规。而因数据库被攻击,2017年9月,美国最大征信公司(伊奎法克斯公司.Equifax),被用户集体起诉要求赔偿约合4500亿美元。《2016年中国互联网安全报告》表明,中国46.3%的网站有漏洞,其中高危漏洞占7.1%。对于个人,在用户使用浏览器、GPS、购物、电子书时,用户的个人信息已经被交了出去。隐私是公民最基本也是最神圣的一种权利,隐私的保护问题乃是数据安全发布的重中之重。
李克强总理在2018年政府工作的建议中,头条建议即为“深入推进供给侧结构性改革”。其中第一项就最先谈到实施大数据发展行动,强调“发展壮大新动能”。无可否认,数据作为发展的动力引擎,带来了各种智能导航、无人车驾驶、图像识别、天眼监控等高科技的便利,但数据的高度个人化,使得在新时代,每一个人的隐私无可遁形。而数据背后隐藏的商业价值注定它极易成为黑客或数据攻击者觊觎的重要目标。如何防止承担着驱动算法不断优化迭代的数据被泄露,是科学研究者的重要课题。
1.2 国内外研究现状
如图1.1数据隐私保护的生命周期模型所示,数据从数据发布者、数据存储方、数据挖掘者、数据使用者,在各类情境下都需要相应的数据保护手段。在数据发布情景下,针对隐私保护进行的数据发布手段,亟需解决的问题是,如何在数据发布时,保证用户数据尽可能保留原信息量可利用的情况下,高效、可靠地降低泄露用户隐私的风险。目前针对数据发布的隐私保护问题,数据失真、数据加密和数据匿名化是三类隐私保护常用技术[1]。但数据失真会对数据的合法使用者造成错误信息判断;相比与数据匿名化,数据加密的隐私保护度更高,但也相应大大减少了信息的可利用性;在通用性上,匿名化技术更胜一筹。
图1.1 数据隐私保护的生命周期模型
数据生命周期
针对数据的匿名发布技术已经得到更大改进与优化,由Latanya Sweeney和Pierangela Samarati提出的一种数据匿名化方法K-匿名(K-anonymization)原则[2-3],后人扩展了K-匿名微聚焦算法[4]、基于聚类的K-匿名算法[5]、Entropy算法[6]等,K-匿名保证了在数据发布时,能有效地防御身份泄露,但是其没有考虑敏感属性的多样性问题,不法分子可以利用同质攻击和背景知识,找到敏感属性与标识符的对应关系造成隐私信息的泄露。
故针对该情景,Machanavajjhala等人提出了L-多样性原则[7],后人在此之上提出了基于数值敏感型L-多样性算法[8],基于聚类的增强L-多样性算法[9]。L-多样性针对K-匿名表中等价类敏感属性取值单一的情况,降低了敏感属性与准标识符属性之间的相关度,明显降低了隐私泄露风险。L-多样性原则解决了属性链接有可能发生的隐私泄露。此外的()-匿名模型[10],通过控制发布数据中敏感属性的联合分布概率来降低隐私泄露的风险。t-closeness[11]提出一种考虑敏感属性分布情况下隐私保护方法,而ε-differential privacy(差分隐私)[12]给出了个人隐私泄露的数学的定义。这些数据匿名的手段从不同方面降低了隐私泄露的风险,但数据表即使经过各种属性原则保证,隐私泄露的风险依然存在。
本文在阅读了各类关于数据匿名,特别是L-多样性的算法后,设计并实现了基于L-多样性算法的订单系统。
1.3 本课题的主要研究内容
本文以基于java的订单管理发布系统为背景,利用K-匿名和L-多样性模型组成的匿名算法系统对数据进行处理,设计并完成一套基于java的订单信息安全发布系统。
本文研究问题的目标是在保证隐私不被泄露的情况下,最大程度上地提高变换后的数据可用性,使数据研究者从变换后的数据中挖掘的知识尽可能与原始数据中可挖掘的知识一致,K-匿名保证了攻击者不能判别隐私信息所属具体个体,L-多样性模型建立在满足K-匿名原则基础上,解决属性链接,除了等价类中的元组数大于K,还要求每个元组至少有L个敏感属性。
由订单管理发布系统提交原始数据后,将原始数据选取合适的K值,对原始数据进行K-匿名化处理,得到的数据称为M1,在M1数据满足K-匿名原则的情况下,选取合适的L值进行L-多样化,得到的数据称为M2,将得到的数据M2接受相应的同质攻击、未排序匹配攻击、背景知识攻击等等,若M2中的隐私信息不会泄露,即成功抵御攻击,则可将其发布显示,即为数据M3;若M2中的隐私信息泄露,即不能抵御攻击,则可重新选择合适的K值与L值,直到可抵御相应的攻击。
以上是毕业论文大纲或资料介绍,该课题完整毕业论文、开题报告、任务书、程序设计、图纸设计等资料请添加微信获取,微信号:bysjorg。
相关图片展示: